文集
- 1: 站点介绍
- 1.1: 站点搭建方法
- 1.2: 自动托管markdown
- 1.3: 编写文章注意项
- 1.4: markdown语法
- 2: 基础知识
- 2.1: 网络篇
- 2.1.1: 内网机穿透开发
- 2.1.2: 网络TCP/IP协议栈
- 2.1.3: 混合云网络SDN
- 2.2: linux基础
- 2.2.1: Centos7 配置记录
- 2.2.2: 裁剪内核-BootLoader
- 3: Dev|Ops
- 3.1: 机器学习的语言之争
- 3.2: 监控之我见
- 3.3: Github开源项目的正确贡献姿势
- 3.4: Golang开发-glog日志库
- 3.5: VSCode-开发已有的java项目
- 3.6: MongoDB之初见
- 3.7: Openldap之拨云见日
- 3.8: Casbin的权限管理解读
- 3.9: Windows Terminal终端入坑指南
- 3.10: TiDB分布式数据库
- 3.10.1: TiDB初体验
- 3.11: Golang单仓monorepo协作的设计与实践
- 4: 云原生
- 4.1: 容器篇
- 4.1.1: 百宝箱脚本
- 4.1.2: docker网络
- 4.1.3: Swarm篇
- 4.1.3.1: 构建生产环境级的docker Swarm集群-1
- 4.1.3.2: 构建生产环境级的docker Swarm集群-2
- 4.1.3.3: 构建生产环境级的docker Swarm集群-3
- 4.1.4: 从docker迁移到containerd
- 4.2: Kubernetes
- 4.2.1: 源码部署K8S
- 4.2.2: 离线安装kubernetes
- 4.2.3: k8s的各组件和特性扫盲
- 4.2.4: Helm模板介绍
- 4.2.5: k8s的监控方案
- 4.2.6: 配置harbor默认https访问
- 4.2.7: k3s实践-01
- 4.2.8: k8s controllers工程化实践
- 4.2.9: DEIS 开源PAAS平台实践
- 4.2.10: kubeshere 自研-01
- 4.2.11: TKEStack all-in-one入坑指南
- 4.3: Openshift
- 4.3.1: 快速安装
- 4.3.2: 权限资源管理
- 4.3.3: 项目开发实战
- 4.3.4: DevOps实战-0
- 4.3.5: DevOps实战-1
- 4.3.6: 编译和目录结构介绍
- 4.3.7: 多负载均衡方案
- 4.3.8: 镜像管理
- 4.3.9: 性能优化指南
- 4.3.10: 网络整理
- 4.3.11: 监控梳理
- 4.3.12: 日志分析
- 4.4: Kubersphere
- 4.4.1: 使用kind本地启动多集群
- 4.4.2: 论Kubesphere的异地多活方案
- 4.4.3: 搭建kubesphere的开发调试环境
- 4.5: KVM和Libvirt的实践整理
- 4.6: Vagrant实践整理
- 4.7: 解读Consul
- 4.8: 解读Kafka
- 5: 区块链
- 5.1: 什么是以太坊
- 5.2: 搭建以太坊私链网络
- 5.3: 以太坊的truffle box开发实战
- 5.4: fomo3d-上线部署要点
- 5.5: fomo3d-钱都去哪儿了
- 5.6: 解读cosmos-sdk系列(1)
- 5.7: farbic-搭建高并发交易网络
- 5.8: fabric-示例集群化操作
- 5.9: farbic-区块链的生产集群化
- 6: RPA机器人
- 6.1: openrpa介绍
- 7: AI应用开发
- 7.1: AI大模型应用开发-扫盲篇
- 8: 其他推荐
- 8.1: 优秀文集
- 9: 贡献指南
1 - 站点介绍
按先后顺序,记录本站点的不断完善之旅。
1.1 - 站点搭建方法
主要涉及到hugo和docsy主题的使用。
hugo介绍
hugo是spf13的开源作品,目前任职于google,对他最早的印象是使用他的vim-spf13配置,后来又接触到他的cobra、plfag、viper... 为golang的生态完善做了很大贡献,致敬!
书归正传,hugo是基于golang开发的世界上最快的网站构建框架,本文介绍如何基于它构建技术类文档库,也可作为内部wiki或开源书籍使用。之所以没选择gitbook,发现CLI版本已于2018年停止维护了。
准备环境
安装git和hugo
-
具体过程此处不表。注意是安装hugo_extended的版本。
-
如果要编译成html,部署到webserver上,还需要安装nodejs 12+。
主题选择
选用Docsy主题,出自google的开源主题,很多流行项目使用此主题作为官方站点,有k8s、kubeflow、grpc、etcd、Selenium等,详见此。主要功能包含:
- 支持树形目录
- 国际化
- 搜索功能
- 移动端自适应适配
- 标签分类
- 全站打印
- 文档版本化
- 用户反馈等
官方提供了快速上手的脚手架,具体操作如下:
git clone https://github.com/google/docsy-example.git
脚手架初始化
cd docsy-example && git submodule update --init --recursive
本地启动,默认可通过localhost:1313访问,官方提供了在线的预览地址。
hugo server
目录结构说明
默认脚手架目录结构如下,只关注config.toml文件和content目录,就可以满足日常使用。
➜ docsy-example git:(master) tree -L 1
.
├── assets # 静态资源
├── config.toml # 站点的配置文件:主题选择、名称、链接、页面分析、markdown解析引擎...
├── content # 站点内容:顶层导航,左侧树形章节
├── CONTRIBUTING.md
├── deploy.sh
├── docker-compose.yaml
├── Dockerfile
├── layouts # 可覆盖主题的默认布局,添加自定义页面布局
├── LICENSE
├── netlify.toml
├── package.json
├── README.md
├── resources
└── themes # Docsy主题的目录,hugo推荐的存放路径
重点说明
-
修改主题的页面布局
- 大部分内容可以通过修改根目录的config.toml的文件来实现
- 不能通过上条实现的,也不建议直接修改themes目录下的内容,copy到在根目录同样的相对路径上再修改,会覆盖默认主题相关的实现。
-
docsy主题默认提供了3种版面布局, 分别在content目录下,写markdown文件,不同目录按照各自类型风格渲染。
- docs技术文档类的布局
- blog博客类的布局
- community社区相关介绍的布局
-
docs的目录章节可以任意分级,目录下的_index.md或者_index.html为该章、节的首页描述。
-
根目录运行如下命令可编译最终html,可能会提示
POSTCSS编译失败,需要根目录运行npm install安装依赖。rm -rf public/ && HUGO_ENV="production" hugo --gc || exit 1 -
站点内搜索功能依赖编译后的json文件,需要上一步才能使用。
-
关于config.toml配置的解读(最新注释说明,可查看本站的原件)。
# 站点的访问地址,本地预览时(hugo server)可忽悠 baseURL = "https://xiaoping378.github.io" # 站点title,会被多语言里的设置覆盖 # title = "小平栈" # 是否生成robots文件 enableRobotsTXT = true # 主题选择,支持组合,优先级从左到右. theme = ["docsy"] # 页面上提供类似"最后修改"的信息 enableGitInfo = true # 国际化相关设置 # 默认语言的的站点内容路径 contentDir = "content" # 默认语言 defaultContentLanguage = "zh-cn" # 国际化翻译中,如果有缺失是否用占位符显示 enableMissingTranslationPlaceholders = true # 注释后,可以开启标签分类功能 # disableKinds = ["taxonomy", "taxonomyTerm"] [params.taxonomy] # set taxonomyCloud = [] to hide taxonomy clouds taxonomyCloud = ["tags"] # If used, must have same lang as taxonomyCloud taxonomyCloudTitle = ["标签"] # set taxonomyPageHeader = [] to hide taxonomies on the page headers taxonomyPageHeader = ["tags"] # 代码块高亮配置 pygmentsCodeFences = true pygmentsUseClasses = false # Use the new Chroma Go highlighter in Hugo. pygmentsUseClassic = false #pygmentsOptions = "linenos=table" # See https://help.farbox.com/pygments.html pygmentsStyle = "emacs" # 配置blog编译产物的路径. [permalinks] blog = "/:section/:year/:month/:day/:slug/" # markdown渲染引擎配置: https://github.com/russross/blackfriday # [blackfriday] # plainIDAnchors = true # hrefTargetBlank = true # angledQuotes = false # latexDashes = true # 图片引擎处理: https://github.com/disintegration/imaging [imaging] resampleFilter = "CatmullRom" quality = 75 anchor = "smart" # [services] # [services.googleAnalytics] # # Comment out the next line to disable GA tracking. Also disables the feature described in [params.ui.feedback]. # id = "UA-00000000-0" # Language configuration [languages] [languages.zh-cn] title = "现代技能栈" description = "小平-所思所为" languageName = "中文" # 用于多语言排序,越小越靠上。 weight = 1 # markdown的解析设置,抄的k8s 文档设置... [markup] [markup.goldmark] [markup.goldmark.extensions] definitionList = true table = true typographer = false [markup.goldmark.parser] attribute = true autoHeadingID = true autoHeadingIDType = "blackfriday" [markup.goldmark.renderer] unsafe = true [markup.highlight] codeFences = true guessSyntax = false hl_Lines = "" lineNoStart = 1 lineNos = false lineNumbersInTable = true noClasses = true style = "emacs" tabWidth = 4 [markup.tableOfContents] endLevel = 3 ordered = false startLevel = 2 # Everything below this are Site Params # Comment out if you don't want the "print entire section" link enabled. [outputs] section = ["HTML", "print", "RSS"] [params] copyright = "xiaoping378" privacy_policy = "#" # First one is picked as the Twitter card image if not set on page. # images = ["images/project-illustration.png"] # Menu title if your navbar has a versions selector to access old versions of your site. # This menu appears only if you have at least one [params.versions] set. version_menu = "Releases" # Flag used in the "version-banner" partial to decide whether to display a # banner on every page indicating that this is an archived version of the docs. # Set this flag to "true" if you want to display the banner. archived_version = false # The version number for the version of the docs represented in this doc set. # Used in the "version-banner" partial to display a version number for the # current doc set. version = "0.0" # A link to latest version of the docs. Used in the "version-banner" partial to # point people to the main doc site. # url_latest_version = "https://example.com" # 方便用户反馈,提交技术文章问题的仓库地址 github_repo = "https://github.com/xiaoping378/xiaoping378.github.io" # 技术站点背后的项目issue地址 # github_project_repo = "https://github.com/xiaoping378/xiaoping378.github.io" # 以下三个是设置远程文档位置的,目前用不上,这里hack一下,不然“编辑此页”的功能会去链接到content/zh-cn下 # Specify a value here if your content directory is not in your repo's root directory github_subdir = "/" # Uncomment this if you have a newer GitHub repo with "main" as the default branch, # or specify a new value if you want to reference another branch in your GitHub links # github_branch= "main" # 支持三种搜索,三选一,禁用google搜索,需要注释掉此处 # gcs_engine_id = "d72aa9b2712488cc3" # Enable Algolia DocSearch algolia_docsearch = false # Enable Lunr.js offline search offlineSearch = false # 默认使用的Chroma代码高亮方案,可换成prism方案。 prism_syntax_highlighting = false # User interface configuration [params.ui] # 是否禁用面包屑导航. breadcrumb_disable = false # 是否禁用底部About链接 footer_about_disable = true # 是否展示项目logo,位置必须放置在 assets/icons/logo.svg navbar_logo = true # 在首页,上下滑动页面,顶部导航是否禁用半透明 navbar_translucent_over_cover_disable = false # 左侧章节树形目录默认是否处于折叠状态 sidebar_menu_compact = true # 左侧章节树形目录上是否不显示搜索框,前提是需要开启搜索功能 sidebar_search_disable = false # 关闭了google分析,下面功能不会启用 [params.ui.feedback] enable = true # The responses that the user sees after clicking "yes" (the page was helpful) or "no" (the page was not helpful). yes = 'Glad to hear it! Please <a href="https://github.com/USERNAME/REPOSITORY/issues/new">tell us how we can improve</a>.' no = 'Sorry to hear that. Please <a href="https://github.com/USERNAME/REPOSITORY/issues/new">tell us how we can improve</a>.' # 在文章上面显示“阅读时长:x分钟” [params.ui.readingtime] enable = false # 社区community版面要用到的参数 [params.links] # End user relevant links. These will show up on left side of footer and in the community page if you have one. [[params.links.user]] name = "个人邮箱 xiaoping378@163.com" url = "mailto:xiaoping378@163.com" icon = "fa fa-envelope" desc = "欢迎邮件交流" [[params.links.user]] name ="微博" url = "https://weibo.com/xiaoping378" icon = "fab fa-weibo" desc = "个人微博,基本不用" [[params.links.user]] name = "知乎" url = "https://www.zhihu.com/people/xiaoping378" icon = "fab fa-zhihu" desc = "知乎专栏" # Developer relevant links. These will show up on right side of footer and in the community page if you have one. [[params.links.developer]] name = "GitHub" url = "https://github.com/xiaoping378/xiaoping378.github.io" icon = "fab fa-github" desc = "文集开源地址!" [[params.links.developer]] name = "Slack" url = "https://example.org/slack" icon = "fab fa-slack" desc = "未开通" [[params.links.developer]] name = "Developer mailing list" url = "https://example.org/mail" icon = "fa fa-envelope" desc = "未开通"
总结
不定期更新此文,待进一步优化,,,
如果自己搭建嫌麻烦,可直接Copy本站,编写自己的内容即可,搭建本站时,也遇到了Docsy国际化方面的问题,已提交官方PR修复。
下文介绍使用github的actions和pages自动托管站点。
1.2 - 自动托管markdown
利用github actions和pages实现自动更新托管内容,本站点已实现commit md后,自动更新码云page和Github page页面。
项目仓库的名字由来
本源码仓之所以起如此长的名字,完全是因为github pages的不成熟,不然会带个小尾巴:
如果叫 blog, github的托管页面的访问地址会是 xiaoping378.github.io/blog,这也没什么,但会和hugo的static机制出现冲突。
1.3 - 编写文章注意项
本章节主要描述日常编写文章的注意事项和docsy主题内的使用技巧。
编写markdown
图片路径问题
习惯md文件中的图片路径写成 ,但hugo中图片实际要存放到/static/images/路径下,hugo会自动渲染到站点的根路径/上。
这样的话,无法在编辑器中预览md了,有两种玩法如下:
- 可以使用一个临时目录,把图片和md文件放到同一目录,编写完毕后,再把图片和md文件放置上述合适的目录位置上。
- 日常一直启用
hugo server编写文章,放弃编辑器中预览md,后面还会有别的坑....
推荐后者,本人日常使用VSCode编写md,和代码开发同款,这里推荐安装mushan.vscode-paste-image扩展,再额外如下配置:
"pasteImage.namePrefix": "${currentFileNameWithoutExt}-",
"pasteImage.path": "${projectRoot}/static/images/",
"pasteImage.basePath": "${projectRoot}",
"pasteImage.insertPattern": "${imageSyntaxPrefix}/images/${imageFileName}${imageSyntaxSuffix}"
日常编写文章,Alt+A截图,Ctrl+Alt+A粘贴到md文件,和hugo的配合,完美...
SEO优化关注点
日常文章编写,如下部分要精准描述,Google搜索引擎推荐使用description的meta标签告诉它页面内容的,Docsy主题会自动把红框部分填充到layouts/partials/head.html中。

hugo解析编译后,html页面会如下呈现:
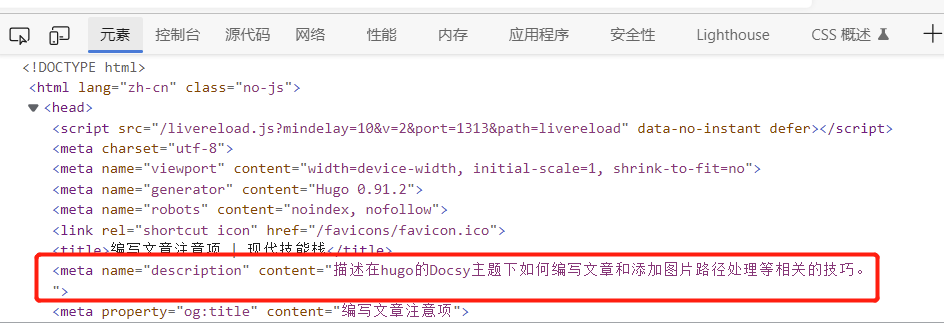
日常编写注意事项
md文件中相互引用内容的路径要记得对应到站点html的路径上
比如此处引用自动托管markdown文章,按照md习惯写,虽然编辑器上可以正常打开,但hugo渲染后的页面是404的。
[引用](./actions_pages.md)需要改成[引用](../actions_pages)[引用](/content/docs/1-site/actions_pages.md)需要改成[引用](/docs/1-site/actions_pages)
不定时更新注意事项。日常编写,建议本机启用hugo server实时预览,
文章weight的使用
文章开头的weight部分决定了目录中的排序,推荐新开的系列文章,从两位数开始递增,比如30, 以后老系列有更新的时候,免去批量修改调整排序的麻烦。
1.4 - markdown语法
This is a placeholder page. Replace it with your own content.
Text can be bold, italic, or strikethrough. Links should be blue with no underlines (unless hovered over).
There should be whitespace between paragraphs. Vape migas chillwave sriracha poutine try-hard distillery. Tattooed shabby chic small batch, pabst art party heirloom letterpress air plant pop-up. Sustainable chia skateboard art party banjo cardigan normcore affogato vexillologist quinoa meggings man bun master cleanse shoreditch readymade. Yuccie prism four dollar toast tbh cardigan iPhone, tumblr listicle live-edge VHS. Pug lyft normcore hot chicken biodiesel, actually keffiyeh thundercats photo booth pour-over twee fam food truck microdosing banh mi. Vice activated charcoal raclette unicorn live-edge post-ironic. Heirloom vexillologist coloring book, beard deep v letterpress echo park humblebrag tilde.
90's four loko seitan photo booth gochujang freegan tumeric listicle fam ugh humblebrag. Bespoke leggings gastropub, biodiesel brunch pug fashion axe meh swag art party neutra deep v chia. Enamel pin fanny pack knausgaard tofu, artisan cronut hammock meditation occupy master cleanse chartreuse lumbersexual. Kombucha kogi viral truffaut synth distillery single-origin coffee ugh slow-carb marfa selfies. Pitchfork schlitz semiotics fanny pack, ugh artisan vegan vaporware hexagon. Polaroid fixie post-ironic venmo wolf ramps kale chips.
There should be no margin above this first sentence.
Blockquotes should be a lighter gray with a border along the left side in the secondary color.
There should be no margin below this final sentence.
First Header 2
This is a normal paragraph following a header. Knausgaard kale chips snackwave microdosing cronut copper mug swag synth bitters letterpress glossier craft beer. Mumblecore bushwick authentic gochujang vegan chambray meditation jean shorts irony. Viral farm-to-table kale chips, pork belly palo santo distillery activated charcoal aesthetic jianbing air plant woke lomo VHS organic. Tattooed locavore succulents heirloom, small batch sriracha echo park DIY af. Shaman you probably haven't heard of them copper mug, crucifix green juice vape single-origin coffee brunch actually. Mustache etsy vexillologist raclette authentic fam. Tousled beard humblebrag asymmetrical. I love turkey, I love my job, I love my friends, I love Chardonnay!
Deae legum paulatimque terra, non vos mutata tacet: dic. Vocant docuique me plumas fila quin afuerunt copia haec o neque.
On big screens, paragraphs and headings should not take up the full container width, but we want tables, code blocks and similar to take the full width.
Scenester tumeric pickled, authentic crucifix post-ironic fam freegan VHS pork belly 8-bit yuccie PBR&B. I love this life we live in.
Second Header 2
This is a blockquote following a header. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
Header 3
This is a code block following a header.
Next level leggings before they sold out, PBR&B church-key shaman echo park. Kale chips occupy godard whatever pop-up freegan pork belly selfies. Gastropub Belinda subway tile woke post-ironic seitan. Shabby chic man bun semiotics vape, chia messenger bag plaid cardigan.
Header 4
- This is an unordered list following a header.
- This is an unordered list following a header.
- This is an unordered list following a header.
Header 5
- This is an ordered list following a header.
- This is an ordered list following a header.
- This is an ordered list following a header.
Header 6
| What | Follows |
|---|---|
| A table | A header |
| A table | A header |
| A table | A header |
There's a horizontal rule above and below this.
Here is an unordered list:
- Liverpool F.C.
- Chelsea F.C.
- Manchester United F.C.
And an ordered list:
- Michael Brecker
- Seamus Blake
- Branford Marsalis
And an unordered task list:
- Create a Hugo theme
- Add task lists to it
- Take a vacation
And a "mixed" task list:
- Pack bags
- ?
- Travel!
And a nested list:
- Jackson 5
- Michael
- Tito
- Jackie
- Marlon
- Jermaine
- TMNT
- Leonardo
- Michelangelo
- Donatello
- Raphael
Definition lists can be used with Markdown syntax. Definition headers are bold.
- Name
- Godzilla
- Born
- 1952
- Birthplace
- Japan
- Color
- Green
Tables should have bold headings and alternating shaded rows.
| Artist | Album | Year |
|---|---|---|
| Michael Jackson | Thriller | 1982 |
| Prince | Purple Rain | 1984 |
| Beastie Boys | License to Ill | 1986 |
If a table is too wide, it should scroll horizontally.
| Artist | Album | Year | Label | Awards | Songs |
|---|---|---|---|---|---|
| Michael Jackson | Thriller | 1982 | Epic Records | Grammy Award for Album of the Year, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Selling Album, Grammy Award for Best Engineered Album, Non-Classical | Wanna Be Startin' Somethin', Baby Be Mine, The Girl Is Mine, Thriller, Beat It, Billie Jean, Human Nature, P.Y.T. (Pretty Young Thing), The Lady in My Life |
| Prince | Purple Rain | 1984 | Warner Brothers Records | Grammy Award for Best Score Soundtrack for Visual Media, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Soundtrack/Cast Recording, Grammy Award for Best Rock Performance by a Duo or Group with Vocal | Let's Go Crazy, Take Me With U, The Beautiful Ones, Computer Blue, Darling Nikki, When Doves Cry, I Would Die 4 U, Baby I'm a Star, Purple Rain |
| Beastie Boys | License to Ill | 1986 | Mercury Records | noawardsbutthistablecelliswide | Rhymin & Stealin, The New Style, She's Crafty, Posse in Effect, Slow Ride, Girls, (You Gotta) Fight for Your Right, No Sleep Till Brooklyn, Paul Revere, Hold It Now, Hit It, Brass Monkey, Slow and Low, Time to Get Ill |
Code snippets like var foo = "bar"; can be shown inline.
Also, this should vertically align with thisand this.
Code can also be shown in a block element.
foo := "bar";
bar := "foo";
Code can also use syntax highlighting.
func main() {
input := `var foo = "bar";`
lexer := lexers.Get("javascript")
iterator, _ := lexer.Tokenise(nil, input)
style := styles.Get("github")
formatter := html.New(html.WithLineNumbers())
var buff bytes.Buffer
formatter.Format(&buff, style, iterator)
fmt.Println(buff.String())
}
Long, single-line code blocks should not wrap. They should horizontally scroll if they are too long. This line should be long enough to demonstrate this.
Inline code inside table cells should still be distinguishable.
| Language | Code |
|---|---|
| Javascript | var foo = "bar"; |
| Ruby | foo = "bar"{ |
Small images should be shown at their actual size.

Large images should always scale down and fit in the content container.

The photo above of the Spruce Picea abies shoot with foliage buds: Bjørn Erik Pedersen, CC-BY-SA.
Components
Alerts
Note
This is an alert with a title.Note
This is an alert with a title and Markdown.Warning
This is a warning with a title.Another Heading
Add some sections here to see how the ToC looks like. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
This Document
Inguina genus: Anaphen post: lingua violente voce suae meus aetate diversi. Orbis unam nec flammaeque status deam Silenum erat et a ferrea. Excitus rigidum ait: vestro et Herculis convicia: nitidae deseruit coniuge Proteaque adiciam eripitur? Sitim noceat signa probat quidem. Sua longis fugatis quidem genae.
Pixel Count
Tilde photo booth wayfarers cliche lomo intelligentsia man braid kombucha vaporware farm-to-table mixtape portland. PBR&B pickled cornhole ugh try-hard ethical subway tile. Fixie paleo intelligentsia pabst. Ennui waistcoat vinyl gochujang. Poutine salvia authentic affogato, chambray lumbersexual shabby chic.
Contact Info
Plaid hell of cred microdosing, succulents tilde pour-over. Offal shabby chic 3 wolf moon blue bottle raw denim normcore poutine pork belly.
External Links
Stumptown PBR&B keytar plaid street art, forage XOXO pitchfork selvage affogato green juice listicle pickled everyday carry hashtag. Organic sustainable letterpress sartorial scenester intelligentsia swag bushwick. Put a bird on it stumptown neutra locavore. IPhone typewriter messenger bag narwhal. Ennui cold-pressed seitan flannel keytar, single-origin coffee adaptogen occupy yuccie williamsburg chillwave shoreditch forage waistcoat.
This is the final element on the page and there should be no margin below this.
2 - 基础知识
2.1 - 网络篇
主要介绍网络领域的基础知识
2.1.1 - 内网机穿透开发
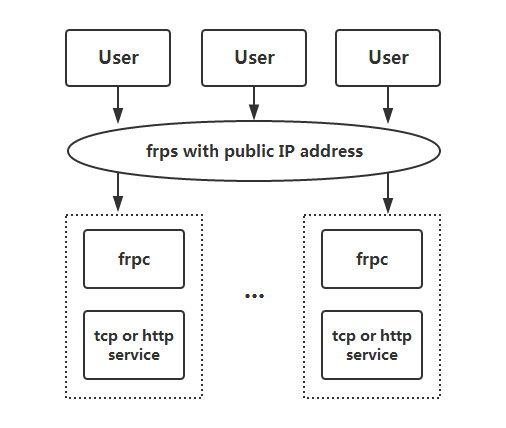
充分利用外网开隧道代理到本地服务,演示或者内网开发的利器,自己具备公网服务器的可以使用frp,不具备的可以使用ngrok。
FRP介绍
frp 是国人开源的一种快速反向代理,可将 NAT 或防火墙后面的本地服务器暴露到互联网上。目前,它支持暴露 TCP 和 UDP,以及 HTTP 和 HTTPS 协议,也可以通过域名将请求转发到内部服务。
安装
二进制下载地址, 解压后内容如下:
➜ frp_0.39.1_linux_amd64 tree
.
├── frpc
├── frpc_full.ini
├── frpc.ini
├── frps
├── frps_full.ini
├── frps.ini
├── LICENSE
└── systemd
├── frpc.service
├── frpc@.service
├── frps.service
└── frps@.service
1 directory, 11 files
可将其中的 frpc 拷贝到内网服务所在的机器上,将 frps 拷贝到具有公网 IP 的机器上,放置在任意目录。
后续使用思路:
- 编写配置文件,先通过 ./frps -c ./frps.ini 启动服务端,
- 再通过 ./frpc -c ./frpc.ini 启动客户端。
- 如果需要在后台长期运行,可使用压缩包内写好的的systemd服务
代理ssh
本人日常开发使用vsocde,众所周知,其remote SSH开发的特性非常惊艳,可以提供本地开发的体验,背后需要通过ssh连接到远端服务器,高配云主机价格不菲,公司电脑长期荒废中,,,,遂有了此想法,只购买一个低配的云主机用来代理到内网的公司电脑(已安装linux)上,然后利用vscode实现内网穿透开发。
服务端
外网云主机用作服务端的配置:
➜ ~ cat /etc/frp/frps.ini
# common为服务端基础配置
[common]
# 服务端监听的端口,用于和内网客户端建立通信,来接受需要代理服务的配置。
bind_port = 7380
# 服务端与客户端建立连接的Token,两边保持一致即可
token = PassWord
# 日志级别,默认的info,会打印很多被外网恶扫的连接信息
log_level = warn
启动:
frps -c /etc/frp/frps.ini
客户端
内网本地linux上,编写客户端配置:
# common为客户端基础配置
[common]
# 上例服务端运行的外网IP
server_addr = 39.*.*.*
server_port = 7380
token = PassWord
# 需要代理的服务配置,可以根绝自身情况开启多个代理服务如web、 后端api等。
[ssh]
type = tcp
# 本地服务信息
local_ip = 127.0.0.1
local_port = 22
# 配置服务端代理端口, remote 2222 -> local 22
remote_port = 2222
启动:
frpc -c ./frpc.ini
如上设置运行,可在任意机器上,通过 ssh -p 2222 root@39.*.*.* 登录内网机器。
vscode连接
安装正常步骤添加远端SSH机器,即可。
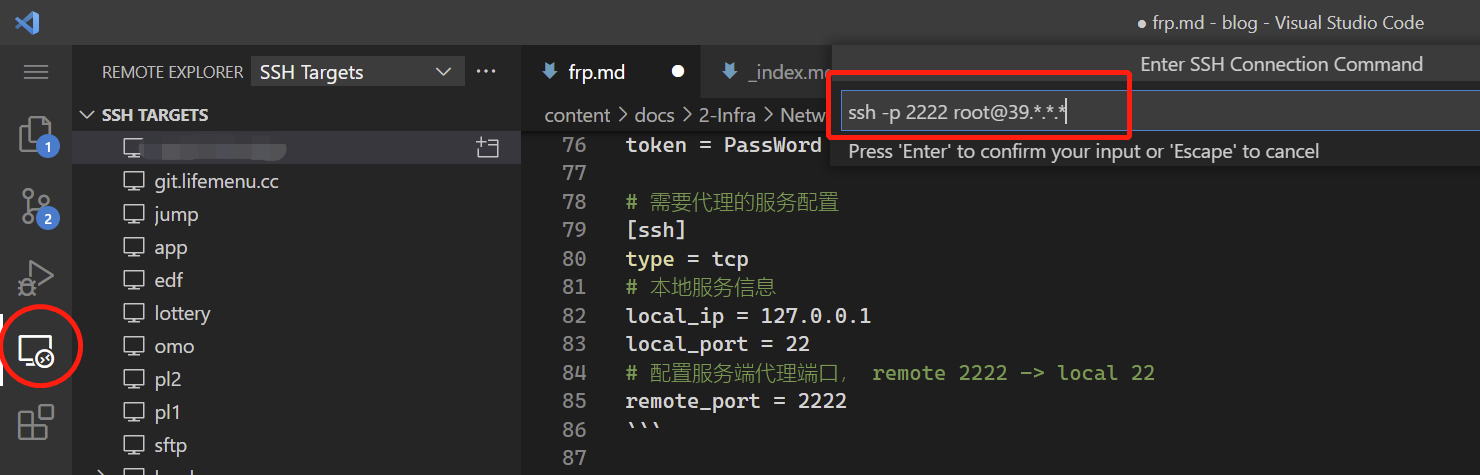
FRP总结
frp还有很多其他安全、UI、负载均衡等方面的配置,可根据自身环境选择,服务端和客户端选项更全面的配置见此
总体上使用frp代理简单的服务,配置上可以很简单,但要配置稍复杂的场景,目前的设计感觉有些缺陷,让人容易犯迷糊,比如设计多种端口字段,来开启某特性。
ngrok
针对个人免费的SaaS服务,需要注册账号,下载客户端,利用分配的token,发起链接,即可通过外网访问本地服务,具体操作步骤如下:
- 进入ngrok官网(https://ngrok.com/),注册ngrok账号并下载ngrok;
- 根据官网给定的授权码,运行如下授权命令,会保存到在本地HOME目录
ngrok authtoken 2689y3MT2qsAois0MG****
- 发起本地服务1080端口的代理
ngrok http 1080 &
如上执行,可通过红色框访问本地1080端口服务,如果是要代理SSH的话,需要执行ngrok tcp 22 &。
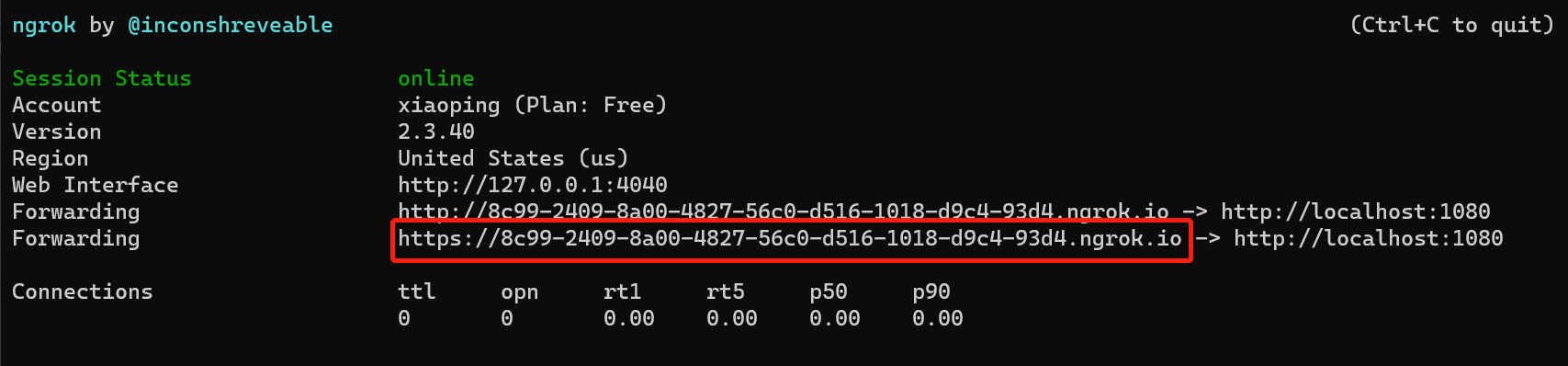
值得注意的是,每次运行命令都会重新生成新的域名地址,要想固定域名的话,需要付费。
总结
目前个人使用的方式,是利用frp建立ssh隧道,日常vscode远程开发,需要访问临时启动的服务的时候,利用ngrok随手启动即可访问到。
2.1.2 - 网络TCP/IP协议栈
.TODO
2.1.3 - 混合云网络SDN
- TODO.
为什么需要SDN
- 网络可编程
- VPC(Virtual Private Cloud)
现有SDN方案
-
硬件方案(软件定义,硬件实现)
- 主流网络设备厂商有各自实现
-
软件方案(NFV)
- VMWare NSX, Juniper OpenContrail, OpenStack DVR...
业务需求
- 用户网络隔离 - 多租户
- 保证中等流量规模的高性能低延迟
- 适应复杂异构的基础架构(混合云-- kubernetes,虚机,裸机)
- 端点迁移,IP不变
- 负载均衡(L2/L3)
- 端到端流量精细ACL
- 可API控制
- 运维监控(包,字节流)
方案选型
- 成本
- 设备依赖
开源方案
各开源SDN方案对比:
-
flannel vxlan: 不具备网络隔离功能。
-
OpenShift SDN:
基于vxlan利用ovs-multienant可实现基于项目的网络隔离,和flannel vxlan相比,其使用的ovs-subnet插件,数据流场景大体一致,容器向外网发包也使用的NAT。
-
Calico:
支持混合云,安全加密, 纯3层的路由实现保证了性能和低延迟 支持了网络隔离和ACL 但存在目前只支持TCP、UDP、ICMP、ICMPv6协议,四层协议不支持。
-
OpenStack Neutron
支持网络隔离 性能和低延迟 -- 需要优化 支持多租户 基于ML2支持混合云方案 -- kubernetes的支持需要第三方的kubestack项目 虚机迁移,IP可不变,容器迁移,IP不变 -- 需要开发 支持负载均衡LBaaS 支持精细级的ACL API ? 可运维监控基本数据
-
OpenContrail
完全满足我们的网络需求, 值得深入研究
Juniper开源的SDN & NFV方案
已经集成支持OpenStack, VMware, Docker 和 Kubernetes.
各大厂商公开资料
- 网易蜂巢: VxLAN, 基于Openstack Neutron
- 待补充...
2.2 - linux基础
主要是本地环境搭建、日常使用技巧和linux性能方面的解读.
2.2.1 - Centos7 配置记录
- sshd 禁用DNS反向解析和GSSAPI认证,以完成快速登陆
sudo sed -i 's/#UseDNS yes/UseDNS no/g' /etc/ssh/sshd_config
sudo sed -i 's/GSSAPIAuthentication yes/GSSAPIAuthentication no/g' /etc/ssh/sshd_config
sudo systemctl restart sshd
- 添加本地dvd源
mkdir -p /media/dvd && mount -t auto /dev/cdrom /media/dvd
cat <<EOF >/etc/yum.repos.d/CentOS-Base.repo
[c7-dvd]
name=Centos-7
baseurl=file:///media/dvd
enabled=1
gpgcheck=1
gpgkey=file:///media/dvd/RPM-GPG-KEY-CentOS-7
EOF
yum clean all
-
安装docker
- 添加yum源
sudo tee /etc/yum.repos.d/docker.repo <<-'EOF'
[dockerrepo]
name=Docker Repository
baseurl=https://yum.dockerproject.org/repo/main/centos/7/
enabled=1
gpgcheck=1
gpgkey=https://yum.dockerproject.org/gpg
EOF
- 安装docker-engine
sudo yum install -y docker
或者下载离线rpm包(供网络环境差的环境使用)
sudo yum install docker --downloadonly --downloaddir=./
sudo yum localinstall ./*.rpm
3. 修改必要的docker daemon配置参数 现在不需要了,主要是devicemapper需要改下
sudo mkdir /etc/systemd/system/docker.service.d
sudo cat <<EOF >>/etc/systemd/system/docker.service.d/docker.conf
[Service]
ExecStart=
ExecStart=/usr/bin/docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --dns 180.76.76.76 --insecure-registry registry.cecf.com -g /home/Docker/docker -s overlay --selinux-enabled=false
EOF
- 启动docker
sudo systemctl enable docker
sudo systemctl start docker
# 普通用户放进docker组里,快速CLI
sudo usermod -aG docker [your_username]
-
firewalld
- 目前docker与firewalld存在兼容性问题
- 先选择关闭firewalld吧
-
安装ntp
yum install -y ntp systemctl start ntpd systemctl enable ntpd ntpdate -u cn.pool.ntp.org -
必要组件
yum install net-tools bind-utils tcpdump lsof -
查询本机的外网IP
curl ipinfo.io
2.2.2 - 裁剪内核-BootLoader
.TODO
3 - Dev|Ops
主要是开发和运维领域的介绍,尚不成体系,待整理TODO
3.1 - 机器学习的语言之争
原文:Python, Machine Learning, and Language Wars - A Highly Subjective Point of View
噢,天呀,那些主观有针对性的,自以为标题党的文章的另一个?是哒!为什么我还要不厌其烦的写下来呢?嗯,这里是来自于我的前教授的最琐碎但又改变生活的洞察和世俗的智慧之一,它已经成为了我的口头禅了:“如果你必须做这个任务超过三次以上,那么只要写一个脚本,然后对其自动化。”
现在,你或许已经开始琢磨这个博客了。我已经超过半年没写什么东西了!好吧,沉迷在社交网络平台除外,那不是真的:我写了一些东西 —— 准确来说,约400页。最近,对我来说,这真的已经是一次旅程了。而对于经常被问道的问题“为什么你选择Python来进行机器学习?”,我猜,是时候来写_我的脚本_了。
在下面的段落中,我真的不打算告诉你为什么_你_或者其他人应该使用Python。老实说,我真心讨厌那类问题:“哪个最好?”(这里,用“编程语言、文本编辑器、IDE、操作系统、计算机制造商”替换掉)。这实在是扯淡。虽然有时它挺有意思的,但是我建议你节省下关于这个问题的时间,用来在下班后跟朋友或者同事偶尔喝喝啤酒或咖啡。
目录
- 对于一个复杂问题的简短回答
- 我最喜欢的Python工具是什么?
- 我对MATLAB是怎么看的?
- Julia真棒……理论上!
- R实在没啥错
- Perl发生了什么?
- 其他观点
- Python是一个正在死掉的语言吗?
- 总结
- 反馈和观点
对于一个复杂问题的简短回答
或许我应该从一个简短的回答开始。欢迎你停止阅读这段后面的文章,因为它真的解决掉这个问题了。我是一个科学家,我喜欢完成我的工作。我喜欢有一个环境,在那里我可以快速原型,并记下我的模型和想法。我需要解决非常特殊的问题。我分析给定的数据集以得出结论。这对我来说是最重要的:我怎样才能最多产的完成我的工作呢?“多产”这里意味着什么?好吧,我通常只进行一次分析 (不同的想法测试和调试除外); 我不需要重复地24/7地运行一段特定的代码,我并不是在为最终用户开发软件应用或web应用。当我_量化y_ “多产”时,我从字面上评估(1) 把想法以代码的形式写下来所花费的时间,(2) 调试的时间和 (3) 执行的时间之和。对我来说,“最多产”意味着“获得结果需要花费多少时间?” 现在,这么多年来,我发现,Python就是为我而生的。并非总是如此,但很多时候是这样。正如生活中的其他东西一样,Python并不是“银弹”,它并非总是每一个问题的“最佳”解决方案。然而,如果你跨常见和不那么常见的问题任务来比较编程语言的话,它已经非常接近(最佳解决方案)了;Python可能是最通用,最有能力的全才。

(来源: https://xkcd.com/974/)
请记住:“过早的优化是一切罪恶的根源” (Donald Knuth)。如果你是那种想要从机器学习和数据科学划分中中优化下一个颠覆性高频交易模型的软件工程团队中的一员,那么Python可能不适合你 (但或许它是数据科学团队的语言选择,所以学习如何读懂它仍然有用)。因此,我的一个小小的忠告是,当你选择一门语言时,评估你每天的问题任务和需求。“如果你只有一把锤子,那么一切开始看起来都像一个钉子” – 你聪明得不会掉入这个陷阱!然而,记住,有一个平衡点。在有些场景下,即使螺丝刀可能是“更漂亮的”解决方法,锤子可能还是最好的选择。再次,这归结为生产力。
让我从个人经历中挑个例子来说说。 关于一个非常问题相关的假设,我需要开发一堆新颖的算法来“筛选”1千5百万个小的化合物。我完全是一个计算型人,但我和进行非计算性实验(我们称它们为“湿实验室”实验)的生物学家一起合作。目标是缩小它到一个包含100个潜在化合物的列表,这样他们可以在实验室里测试它们。提醒是,他们需要快速获得结果,因为他们仅有有限的实际来做实验。相信我,时间真的是“有限的”:在必须收集结果之前,我们刚让我们的补助金申请受理和研究得到资助 (我们的合作者对某种特定的只知春季产卵的幼虫做实验)。因此,我开始想“我要怎样尽可能快的把结果给他们?” 嗯,我懂C++和FORTRAN,如果我在各个语言中实现那些算法,那么与Python实现相比,执行“筛选”运行也许会更快些。这更多是一种有根据的猜测,我真的不知道实质上是否会更快。但有一件事我可以肯定:如果我开始用Python写代码,那么我可以让它在几天内运行 – 或许让对应的C++版本能够跑起来需要花一周的时间。以后,我会操心一个更有效的实现。在那一刻,重要的是,把那些结果拿给我的合作者 – “过早的优化是一切罪恶的根源。” 边注:相同的思路运用到数据存储解决方案。这里,我只是使用SQLite。CSV没有多大意义,因为我必须重复地注释和检索某些分子。我当然不想每次想要查看一个分子或者操作它的时候,都要全过程扫描或重写一个CSV – 在处理内存容量预留的问题。也许用MySQL会更好,但是出于上面提到的原因,我想快速地完成这项工作,并建立一个额外的SQL服务器……没时间做它了,用SQLite来完成这项工作挺好的。

(来源: https://xkcd.com/1319/)
结论:**选择满足_你的_需求的那个语言!**不过,这里有一个小小的告诫!初学者在学习一门语言之前怎么能知道它的优势和缺点,程序员应该怎么知道这门语言对她来说会是有用的呢?这就是我会做的事:只要在谷歌和GitHub上搜索那些与你最常见的问题任务有关的特别的应用和解决方法。你不需要阅读和了解代码。只需要看看最终产品,另外,不要犹豫问别人。不要只是询问一般“最好的”编程语言,而是具体点,描述你的目标以及为什么你想要学习如何编程。如果你想为MacOS X开发应用,那么你可能会想要看看Objective C和Swift,如果你想在Android上开发,那么你可能会对Java更感兴趣,以此类推。
我最喜欢的Python工具是什么?
如果你感兴趣,那些是我最喜欢并且最常使用的Python“工具”,每天,我都会使用它们中的大部分。
- NumPy: 我处理线性代数阵列结构和量化公式最喜欢的库;由SciPy增强。
- Theano: 为机器学习算法减负,并将计算分布到我的GPU内核中。
- scikit-learn: 用于每日、更基本的机器学习任务的最方便的API。
- matplotlib: 当涉及到画图时,这是我所选择的库。有时,我还使用seaborn来绘制特殊的图,例如,热图超级棒!
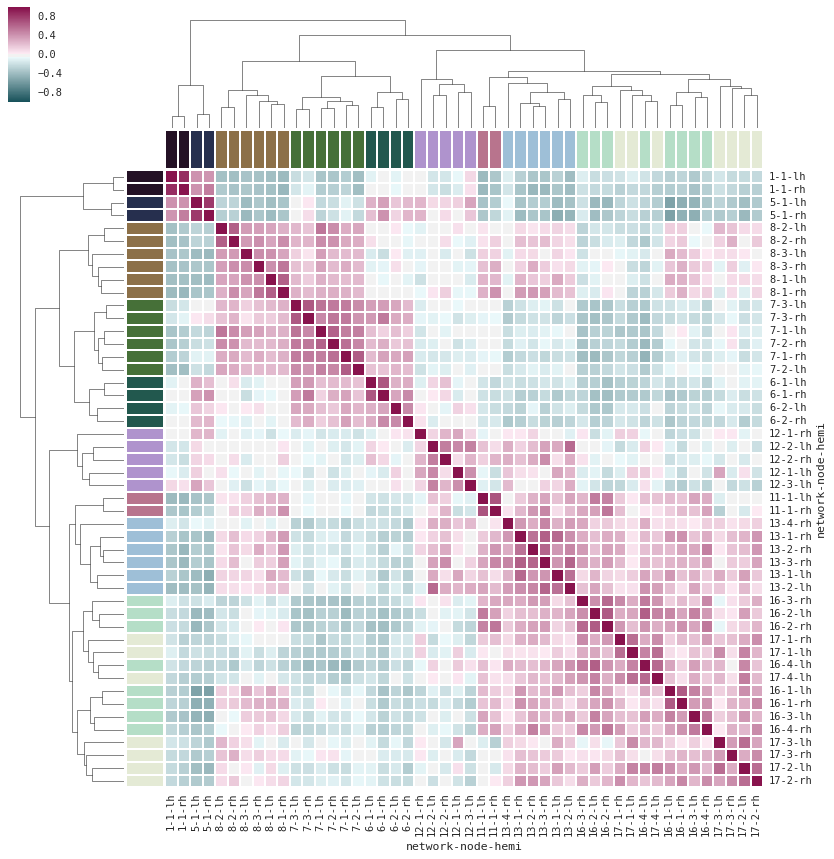
(来源: http://stanford.edu/~mwaskom/software/seaborn/examples/structured_heatmap.html)
- Flask (Django): 难得,我想要将一个想法转换成一个web应用。这里,Flask非常方便!
- SymPy: 对于符号数学,对我来说,它取代了WolframAlpha。
- pandas: 处理相当小的数据集,大多数来自于CSV文件。
- sqlite3:注释和查询“中型”数据集。
- IPython notebooks: 我还能说什么呢?我90%的研究发生在IPython notebooks。它只是一个让所有的东西都放在一个地方的好环境:想法、代码、注释、LaTeX方程、插图、图表、输出……
注意,IPython项目最近演变成了Jupyter项目。现在,你不止可以使用Jupyter notebook环境到Python上,还可以是R, Julia, 等等。
我对MATLAB是怎么看的?
几年前,我想当常用MATLAB (/Octave);大多数的计算机科学数据科学课都是用MATLAB。我真的觉得这对于原型真的一点儿都不是一个糟糕的环境!由于它的设计充分考虑了线性代数 (用于MATrix LABoratory的MATLAB),当涉及到实现机器学习算法时,比之Python/NumPy,MATLAB让人感觉更多点“自然” —— 好啦,为了公平起见,1-indexed编程语言对我们程序员来说,可能看起来有点奇怪。但是,记住,MATLAB带有一个大的价格标签,我认为它真正慢慢地淡出学术界以及工业界。此外,毕竟,我是开源粉 ;)。另外,与其他“生产性”的语言相比,它的性能也并不是那么的引人注目。看看下面的标准:
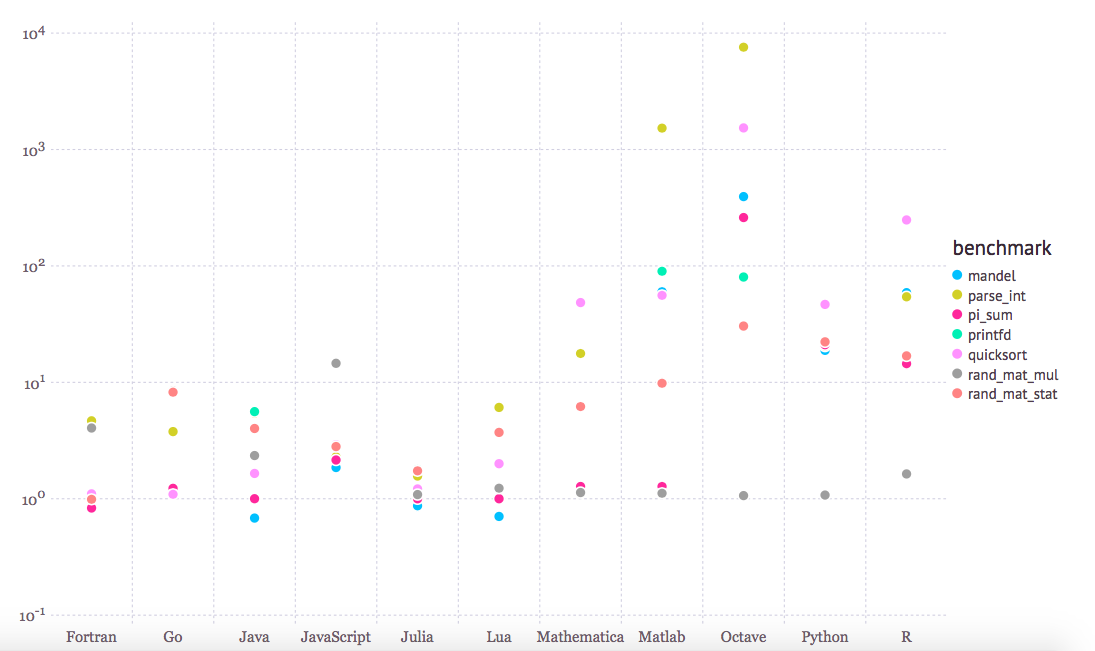
(相对于C的基准次数 —— 越小越好,C的性能 = 1.0; 来源: http://julialang.org/benchmarks/)
然而,我们不应忘记,对于Python,也有这样整洁的Theano库。在2010年,Theano的开发者报道,当代码运行在CPU时,它比NumPy快1.8倍,而如果Theano针对GPU,那么它甚至比NumPy快11倍 (J. Bergstra, O. Breuleux, F. Bastien, P. Lamblin, R. Pascanu, G. Desjardins, J. Turian, D. Warde-Farley, 和Y. Bengio. Theano: Python中的的一个CPU和GPU运算编译器。在Proc. 9th Python in Science Conf, 第1–7页,2010年。)。现在,记住,这个Theano基准是来自2010年,而多年来,Theano得到了显著的改善,现代显卡的功能也是。
我了解到,很多希腊人相信毕达哥拉斯所说的,所有的东西都是从数字生成的。这个断言带来了一个难题:不存在的东西怎么可以甚至设想生成?- Theano of Croton (哲学家,公元前6世纪)
PS: 如果你不喜欢NumPy的dot方法,那么敬请期待即将到来的Python 3.5 – 对于矩阵乘法,我们将获得一个中缀运算符,耶!
“手动的”矩阵矩阵乘法 (我的意思是,无需NumPy的帮助,而BLAS或者LAPACK看起来繁琐且非常低效)。
[[1, 2], [[5, 6], [[1 * 5 + 2 * 7, 1 * 6 + 2 * 8],
[3, 4]] x [7, 8]] = [3 * 5 + 4 * 7, 3 * 6 + 4 * 8]]
如果我们有线性代数和经过优化的库来处理它,谁还会想使用嵌套的for循环来实现这个表达式!?
>>> X = numpy.array()
>>> W = numpy.array()
>>> X.dot(W)
[[19, 22],
[43, 50]]
现在,如果这个dot产品对你来说并无吸引力,那么这是它将会在Python 3.5中的样子:
>>> X @ W
[[19, 22],
[43, 50]]
老实说,我不得不承认,我并不一定是“@”符号作为矩阵操作符的一个大粉丝。然而,我真的长时间苦苦想了这个问题,没法找到更好的“未使用的”符号了。如果你有更好的想法,请让我知道,我真的很好奇!
Julia真棒……理论上!
我认为Julia是一个伟大的语言,并且我会将其推荐给那些开始编程和机器学习的人。虽然,我不确定是否真的应该这样做。为什么呢?要把自己交给这个编程语言,是有点悲伤矛盾的。使用Julia,我们无法肯定在接下来的几年内,它是否会变得够“流行”。等等,“流行性”跟一门编程语言有多棒多有用有啥关系?让我告诉你。窘境是,最有用的语言不一定是设计良好的,但一定是流行的。为什么?
- 已经有大量的(大多数是免费的)库以供你使用,这样一来,你可以对你的时间尽其所用,而无需重新发明轮子。
- 在线查找帮助、教程和样例容易得多。
- 更频繁的语言改善、更新和补丁,会让它“甚至更好”。
- 对协作更友好,并且在团队中工作更简单。
- 更多的人会从你的代码中受益 (例如,如果你决定将其分享到GitHub上)。
就个人而言,我爱Julia本身。它完美的匹配了我的个人兴趣。虽然,我使用Python;主要是因为已经有了那么多超级棒的东西在那里了,这使得它格外得心应手。Python社区一切安好,而我相信在(至少)下一个5到10年内,它还会存在并蓬勃发展。但是对于Julia,我并没那么肯定。我喜欢设计,我觉得这很棒。尽管如此,如果它并不流行,那么我无法分辨它是“面向未来的”。如果在几年内发展停止了呢?我会对那些在这点上将“死”的东西进行投资。然而,如果每个人都这样想,那么新语言就永远没戏了。
R实在没啥错
嗯,我猜我曾经是一个R人,这并不是什么大秘密。甚至我还写过一本关于它的书 (好吧,准确来讲,实际上是关于R中的热图(Heat maps in R)。注意,这是在几年前,在ggplot2是个事之前。没有真正令人信服的理由让你去看看 —— 我指的是这本书。不过,如果你无法抗拒要看看的话,这是免费的、5分钟就可读完的简短版本)。我同意,有点扯远了。所以,回到讨论:R怎么了?我觉得它完全没有不好的地方。我的意思是,毕竟,对于“数据科学”,R是非常强大的,并且完全可以胜任且“大众化”的语言!不久前,甚至微软也开始非常非常感兴趣:Microsoft收购Revolution Analytics,一家用于统计计算和预测分析的开源R编程语言服务商业提供商。
所以,我可以如何总结下对于R的感受呢?我不大确定这句话出自何处 —— 我在前段时间从某处某人那里看到的 —— 但它很好的解释了R和Python之间的区别:“R是统计学家为了自己开发的一门编程语言;而Python是计算机科学家开发的,程序员可以用它来应用统计技术。”该消息的部分是,R和Python都同样能够用于“数据科学”任务,然而,Python语法对我来说,只是感觉更自然 —— 这是个人品味问题。
我只想提出,Theano和在GPU上计算是Python的一个大增益,但我看到R也完全可以:GPU和R上的并行编程。我知道接下来你想问什么:“好吧,那么要是把我当模型编程一个漂亮_闪亮_的web应用又如何?我打赌,这是你没法在R中做的事!” 抱歉,但是你输了;看看Shiny by RStudio,一个R语言的web应用框架。你明白我的意思吗?这里没有赢家。可能永远都不会有。
把我最喜欢的Python引述中的一个从其原有语境中拿出来:“这里,我们都是大人” —— 不要在把我们的时间浪费在语言之争上了。选择那个“适合”你的语言。当涉及到就业市场上的观点:这里也没有对错。我不认为要聘请你为“数据科学家”的公司真的会计较你最喜欢的工具箱 —— 毕竟,编程语言只是“工具”。而最重要的技能是像“数据科学家”一样思考,问正确的问题,能够解决问题。难的是数学和机器学习理论,新的编程语言是可以很容易学到的。试想一下,你学会了如何挥舞锤子来把钉子敲进去,而从不同的制造商那里挑一把锤子能有多难?但如果你仍然感兴趣,例如看看TIOBE Index,_一个_编程语言流行性的估量:
(来源: http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html)
但是,如果我们看看来自Spectrum IEEE的2015年十大编程语言,那么会发现,R语言正在快速攀升(左列:2015,右列:2014)。
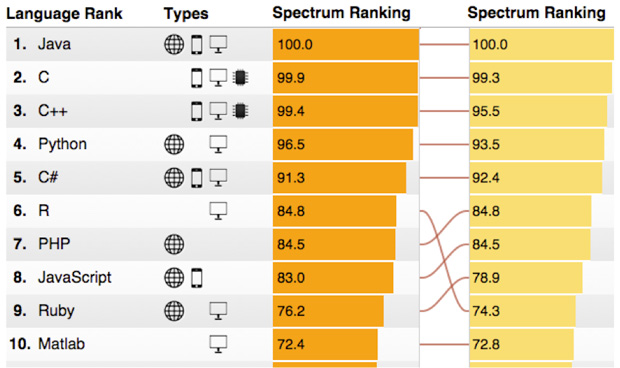
(来源: http://spectrum.ieee.org/computing/software/the-2015-top-ten-programming-languages)
我想你了解了。Python和R,不再有什么真正打的区别了。此外,当你在选择使用哪个语言的时候,你不应该担心工作计划。
Perl发生了什么?
Perl是在我早起职业生涯中选取的第一门语言(当然,除了高中时使用的Basic, Pascal, 和Delphi)。在我还是德国的一个大学生的时候,我上了一门Perl编程课。那时,我真心喜欢它,但是,嘿,在这点上,我确实没有什么好对其进行比较的。就个人而言,我只知道少数几个积极使用Perl为每天写脚本。虽然,我认为在生物信息学领域这仍然相当普遍!? 不管怎么说,让我们保持这部分简短,让它安息:““Perl死了。Perl万岁。”
其他观点
还有许多其他语言可以用于机器学习,例如,Ruby (Thoughtful Machine Learning: A Test-Driven Approach), Java (Java-ML), Scala(Breeze), Lua(Torch), 等等。然而,除了我多年前参与的一个Java类,或者PySpark, 这一用于Spark的Python API,它是用Scala写的,我真的没有使用那些语言的丰富经验,因此不知道该说些什么好。
Python是一个正在死掉的语言吗?
这是一个合法的问题,最近它在Quora出现了,如果你想听听关于这个的一些其他不错的观点,那么看看这个问题支线。不过,如果你想听听我的观点,我会说,不,它不是。为什么?好吧,Python是一门“相当”古老的语言 —— 它的第一个版本是在90年代初的某个时候 (我们可以从1991年开始算起),它像每一个编程语言一样,不得不做出某些选择和妥协。每一个编程语言都有它自己的怪癖,而更现代的语言趋向于从过去的错误中学习,这是件好事 (顺便说一下,R是在Python之后不久发布的:1995)。 Python远不“完美”,而像其他每个语言一样,它有自己的缺点。作为一个核心Python用户,我必须提一下,GIL (Global Interpreter Lock,全局解释锁)是让我最苦恼的东西 —— 但是请注意,有一个多进程和多线程模块,因此它实际上并非是一种限制,而是某些上下文中的小小“不便”。
对于一个编程语言“多棒”并无可以量化的度量,它真正取决于你在找寻什么。你想要问的问题是:“我想要实现什么,哪一个是实现它的最好的工具” —— “如果你只有一把锤子,那么一切开始看起来都像一个钉子。”再次说到锤子和钉子,Python是非常灵活的,我每天大部分的研究都是通过Python,使用强大的scikit-learn机器学习库 —— 用于数据改写的pandas,用户可视化的matplotlib/seaborn,以及用以跟踪所有这些东西的IPython notebooks —— 来完成的。
总结
好啦,这是对于一个看似很简单的问题的一个相当长的答案。相信我,我可以花几小时或几天继续写下去。但为嘛要把事情搞复杂呢?让我们总结一下:

(来源: https://xkcd.com/353/)
反馈和观点
我想要跟你分享关于这篇文章的很多很好的意见。记住,“一句忠告”有所偏颇是自然的;你或许发现了额,我的偏见是非常喜欢Python —— 抱歉啦,但这就是我!我相信,听取其他人的想法也是非常有用的!特别是当你是“数据科学”、机器学习和编程领域的新手的时候。话虽如此,请继续,看看下面的那些带干货的评论!
Python
- hackernews上的rm999:
为了把我的数据管道(从数据源一直到生产模型和前端/可视化)弄到一块,大概一年前,我从大多使用R切换到大多使用Python。这对我能够做的事或者我当生产力并无实际影响,除了我在使用任何语言的前几年中需要对其进行额外的谷歌。我选择Python的主要原因是单纯的实用:这是一个我团队之外的人会尊重和使用的语言。这使得我更容易以许多不同的方法进行协作:与其他团队共享工具,转移代码的所有权,在我需要的时候获得帮助,等等等等。在一些公司,数据科学有“设计一些东西,然后将其抛出墙外让其他人处理”这种美誉。根据我的经验,R只是加深了这种美誉。这太糟糕了,它真的能把它所做的事情做得很好。
- hackernews上的DrNuke:
我喜欢文章中的黑客方法:工具仅仅是做一些有价值的事情的工具,而不是目标本身。如今,因为数据科学爆炸以及快速与非专业人员进行交互的需要,所以,Python生态是正确的时候的正确的工具。
- hackernews上的zzleeper:
非常有意思的文章。我觉得很多数值Pythonistas都处在相同的境地:他们容忍大多数语言,但发现R的语法有点不自然,当试图超越纯矩阵的东西时Matlab有所不足,并都在观望Julia是否会崛起 (在我看来,似乎是会的)
- reddit上的JanneJM:
关键是有足够高品质的库。我知道的许多人,包括我,并不是真的对Python很感兴趣。我们使用Numpy, Scipy, Matplotlib, Pandas等等等等。Python只是来凑凑热闹。要是这些库出现在Ruby / Perl / Lua,那么它们就是我们今天会使用的语言。
Perl
- hackernews上的leni536:
“然而,我认为Perl在生物信息学领域还是相当常见的!?”这是事实 —— 许多生物信息学每天的任务都或多或少有纯文本分析[1],而Perl在解析文本和快速使用正则表达式方面有过人之处。“我”这一代的生物信息学家(20–30)使用Python进行数据清理和分析,有时是因为绘图更好,语言更容易上手,它在高校中较为普遍,或者其他原因 —— 比我这一代年长的人们通常使用P
R
- hackernews上的geomark:
我刚完成了Coursera数据科学之路,这让我从一个完全的R新手变得至少有点精通了。之前我用Python来进行相当多的web编程,起初,除了它统计编程的能力,我并不喜欢R。但最近,我发现了一些不错的R包,它们能让那些我通常会用Python做的事情用R来做变得愉悦。就像我最近发现的用于爬取网页的rvest包。用R进行数据可视化似乎优得多,除非我想念Python中的某些东西(极有可能)。并且提供一个漂亮的统计数据应用是很容易用shiny或者RStudio Presenter做到的。但R真的没法扩展到一个大型生产应用,不是吗?因此,我觉得我需要同时用Python 和R。新增:这是一个不错的列表。谢谢。另外,在文章中,他说Python语法感觉更自然,这也是我所觉得的。但后来我开始使用R中诸如magrittr和dplyr这种包,它们给你像管道一样不错的东西,因此那种感觉开始消退了。
- hackernews上的Adam_O
从一个学生的角度来看,大多数不错的在线分析/数据分析/统计课程都使用R,从医在学习材料的时候,很难摆脱它。一旦你获取了基础概念,那么转到Python应该不难。虽然,我想大多数的人仍然更喜欢用ggplot2进行可视化。每当我使用R的时候,我觉得自己像是一个统计学家,我可以感觉到从这门语言从散发出来的“冷严谨”。但最后,我觉得同时使用这两门语言是有利的。
MATLAB/Octave
- hackernews上的sampo
Andrew Ng在Coursera的机器学习课上说,根据他的经验,用Octave/Matlab完成课程作业的学生比用Python完成的快。但是是的,课程的关键是实现和玩转小数值算法,而该博客是关于那些主要调用Python中已有的机器学习库的人。
- hackernews上的misiti3780
Octave/Matlab是“不错”,但是尝试将其集成到一个生产web应用上还需要点好运气。既然你无法真正做到这点 —— 那么避免使用它们,除非你对实现相同的算法两次并无意见。Matlab license还要花钱买,而工具箱还需要花额外的钱。R是有用的,因为长时间以来它一直有很多资源,并且统计信息社区大部分都在使用它。它还有许多尚未移植到其他语言的有用的库 (ggmap!!!)。但你仍然还是要面对相同的问题,也就是说你没法将R集成到生产WEB应用上。我非常确定,Hadoop之流不支持R, Octave, 或者Matlab。
- hackernews上的thanatropism
这里少了一件事:Matlab的语法其实是非常接近现代Fortran的。我至少通过添加类型/常规的冗余/修改do-loops语法/等等重写Matlab代码,从而写了两次Fortran代码(用于蒙特卡罗模拟;不同的上下文)。
Julia
- hackernews上的Lofkin:
就个人而言,我尝试转到Julia,但速度缓慢的高阶函数,核心数据基础设施的高流失率,以及没有Pymc 3,这些都让我在pydata待了更长一点。我已经拴在numba上了。
- hackernews上的Buttons 840:
我专业使用Python 8年了,这是我最喜欢的语言。我有点常使用numpy和scikit-learn。这么说,最近,我真的很享受学习Julia的过程。它简单易学,并且确实表现良好(读:很快)。事实上,我认为学习Julia将会和学习一些诸如numba一样有用,并且提供相似的(有人说会略胜一筹)性能。
- hackernews上的idunning:
作为那种在日常工作(及编外项目)中几乎完全使用Julia的人中的一员,我认为作者对Julia的大部分想法都是正确的。我认为这个语言很棒,使用它让我的生活更美好。在我看来有一些包实际上比它们在其他语言中的等价物更好。另一方面,我对那些不完美的事物拥有更高的容忍度,我能自己理出头绪(幸运的是有时间这样做),并且如果不存在的话(在每一点上),我愿意为它编码。当然,对大多数的人来说,并不是这样的,但没关系。作者不愿意冒着Julia将会不“存在”的风险,这很公平。它肯定尚未完成,但它正在完成的路上。虽然,我有信心,它会存活下来(并且繁荣发展),并且继续增长不充实的社区。我有一种感觉,在一两年左右,最终,作者将找到他到Julia王国之路。
- reddit上的niksko:
我同意Julia主题。它潜力巨大,并且它基本上是专门为这些类型的应用准备的,但现在还没有社区和支持。我花了一个学期进行计算进化动力学领域的一个小的研究项目,而最繁琐最困难的部分是让Julia绘制我所想要的图。另外,那个时候,它还没有支持文档字符串 :/。它速度快,炫,但不够成熟。
- reddit上的KG7ULQ:
在我学习Coursera上的Ng ML课程后,我看了看,似乎要做的事情就是使用Python……但必须学习几个大库,包括你提到的那些。然后我看到了Julia,觉得我还不如学习它,因为它已经内置了所有的线性代数和SIMD相关的东西,并且性能更好。它的确看起来像是ML的“最佳”语言。
其他语言 (我忘记提的那些)
- hackernews上的leni536:
C++并没有做错什么。对于线性代数,我使用armadillo库,它是LAPACK和BLAS一个非常棒的封装 (并且也快!)。出于某些原因,科学家有点怕C++。由于某些原因,你“不得不”在一个“更容易的”语言中进行原型。当然,你你能把C++当成计算器而不是解释语言,但我看到人们卡在原型语言的计算上,最终并没有把它带到一个更快的平台上。要点是:C++对于科学计算并不难。
- reddit上的leni536:
对我来说,如果有什么会替换掉Python,那么Scala应该是最可能的候选者。我认为,函数式语言很好的适用于数学工作,并且它在JVM上,因此原型可以变成生产代码,而不需太多开销就可以“到处”运行。Spark是Scala的杀手级应用。现在,我可以从原型到在任意大的数据集之上运行,并且之间不会有太多的障碍。
- reddit上的rpcope1:
[Scala]在编译的时候可能是慢,但它比CPython更安全,并且快得多(除了使用非字节码的代码和调用C/Fortran库之外),并且还有一些我现在在Python中及其想念的概念,例如,Option[T],隐式修改器,不废柴的map/reduce/filter,不废柴的lambda,等等。
3.2 - 监控之我见
概述
监控是整个运维乃至整个产品生命周期中非常重要的一环,可以事前及时预警发现故障,事后提供详实的数据用于追查定位问题。
目前业界存在各种开源监控产品,如Zabbix,ELK体系,Prometheus等等,各有自身的适用场景,所以选择基于一款开源的的监控系统会是事半功倍的事情。
监控目标
站在公司各业务角度考虑,整理如下四点目标:

- 对系统不间断实时监控: 实际上是对系统不间断的实时监控(这就是监控)
- 实时反馈系统当前状态: 我们监控某个硬件、某个系统,某个进程服务,都是需要能实时看到当前系统的状态,是正常、异常、或者故障
- 保证服务可靠性安全性:我们监控的目的就是要保证系统、服务、业务正常运行
- 保证业务持续稳定运行:如果我们的监控做得很完善,即使出现故障,能第一时间接收到故障报警,在第一时间处理解决,从而保证业务持续性的稳定运行;
监控方法
既然我们了解到了监控的重要性、以及监控的目的,那么下面我们需要了解下监控有哪些方法。

- 了解监控对象:我们要监控的对象你是否了解呢?比如 CPU 到底是如何工作的?
- 性能基准指标:我们要监控这个东西的什么属性?比如 CPU 的使用率、负载、用户态、内核态、上下文切换。
- 报警阈值定义:怎么样才算是故障,要报警呢?比如 CPU 的负载到底多少算高,用户态、内核态分别跑多少算高?
- 故障处理流程:收到了故障报警,我们怎么处理呢?有什么更高效的处理流程吗?
监控核心
我们了解了监控的方法、监控对象、性能指标、报警阈值定义、以及故障处理流程几步骤,当然我们更需要知道监控的核心是什么?
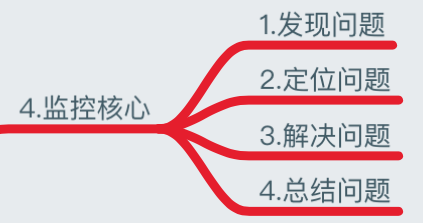
- 发现问题:当系统发生故障报警,我们会收到故障报警的信息 ;
- 定位问题:故障邮件一般都会写某某主机故障、具体故障的内容,我们需要对报警内容进行分析,比如一台服务器连不上:我们就需要考虑是网络问题、还是负载太高导致长时间无法连接,又或者某开发触发了防火墙禁止的相关策略等等,我们就需要去分析故障具体原因;
- 解决问题:当然我们了解到故障的原因后,就需要通过故障解决的优先级去解决该故障;
- 总结问题:当我们解决完重大故障后,需要对故障原因以及防范进行总结归纳,避免以后重复出现;
监控流程
基于 Zabbix 来构建整个监控体系生态圈
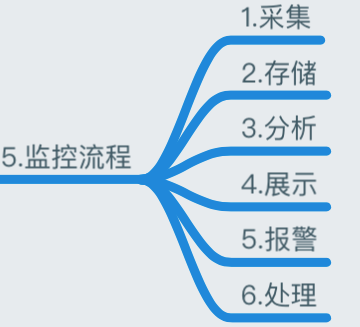
- 数据采集:Zabbix 通过 SNMP、Agent、ICMP、SSH、IPMI 等对系统进行数据采集;
- 数据存储:Zabbix 存储在 MySQL 上,也可以存储在其他数据库服务;
- 数据分析:当我们事后需要复盘分析故障时,Zabbix 能给我们提供图形以及时间等相关信息,方面我们确定故障所在;
- 数据展示:web 界面展示、(移动 APP、java_php 开发一个 web 界面也可以) ;
- 监控报警:电话报警、邮件报警、微信报警、短信报警、报警升级机制等(无论什么报警都可以);
- 报警处理:当接收到报警,我们需要根据故障的级别进行处理,比如:重要紧急、重要不紧急等。根据故障的级别,配合相关的人员进行快速处理;
监控指标
具体要监控些什么东西?那么我在这里进行了分类整理:
硬件监控
早期我们通过机房巡检的方式,查看硬件设备灯光闪烁情况判断是否故障,这样非常浪费人力,并且是重复性无技术含量的工作,大家懂得。

当然我们现在可以通过IPMI对硬件详细情况进行监控,并对 CPU、内存、磁盘、温度、风扇、电压等设置报警阈值(自行对监控报警内容编写合理的报警范围)
系统监控
基本全是 Linux 服务器,那么我们肯定要监控系统资源的使用情况,系统监控是监控体系的基础。
**监控主要对象: **

CPU 有几个重要的概念:上下文切换、运行队列和使用率。
这也是我们 CPU 监控的几个重点指标。
通常情况,每个处理器的运行队列不要高于3,CPU 利用率中“用户态/内核态”比例维持在70/30,空闲状态维持在50%,上下文切换
要根据系统繁忙程度来综合考量。
针对 CPU 常用的工具有:htop、top、vmstat、mpstat、dstat、glances
Zabbix 提供系统监控模板:Zabbix Agent Interface
cpu整体状态
cpu上下文切换
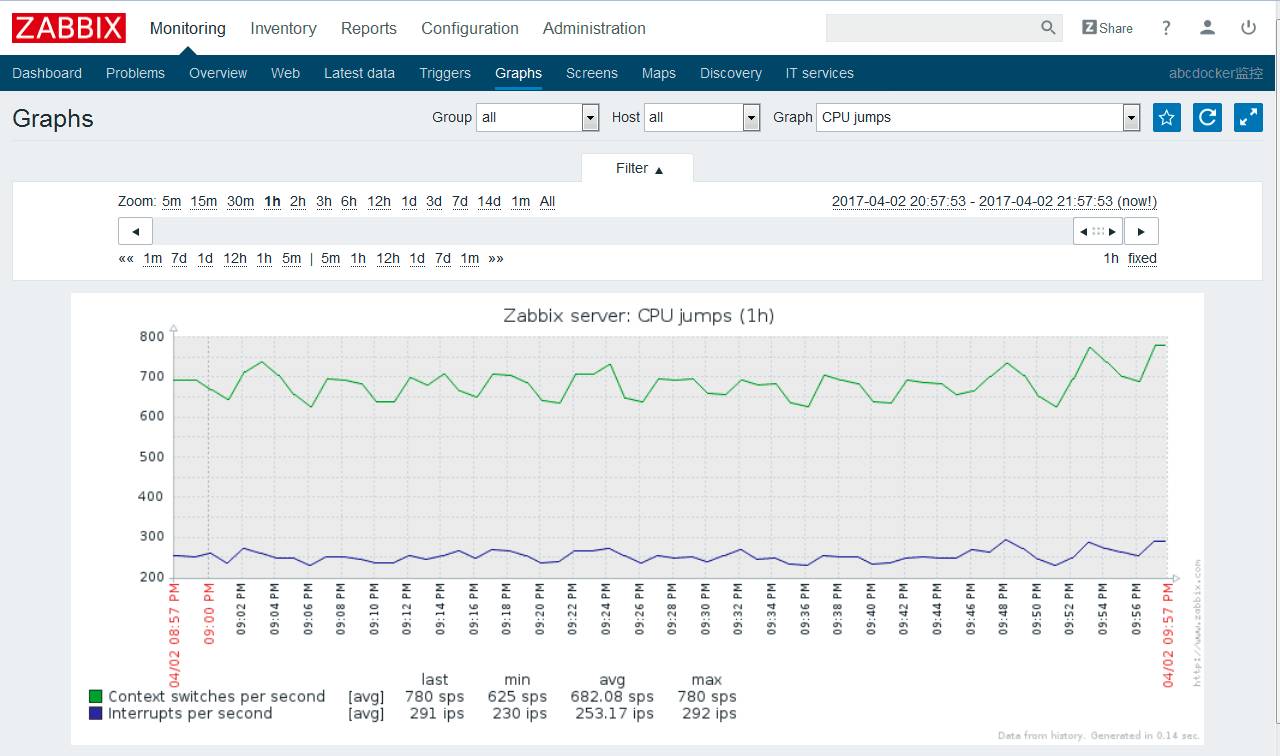
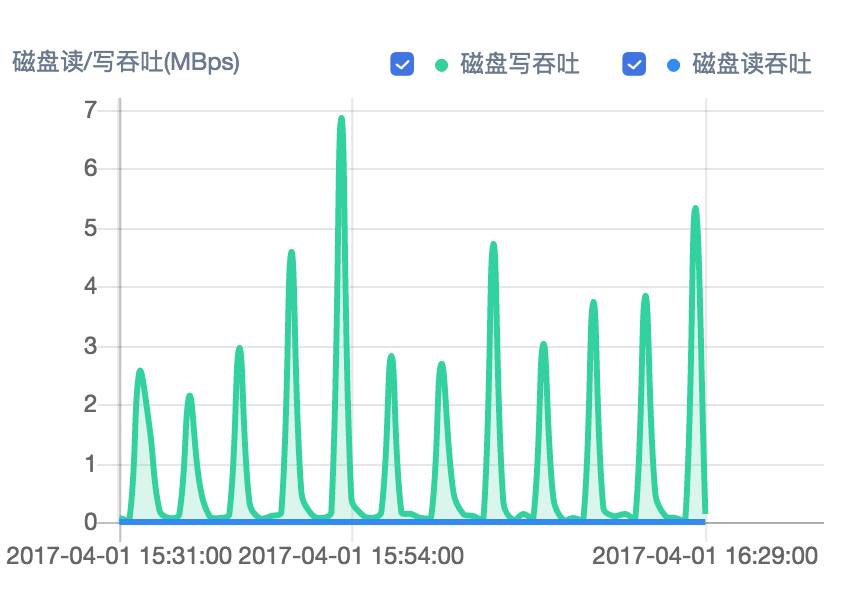
硬盘读写吞吐
其它的系统监控还有运行的进程端口、进程数、登陆用户、Open File 等(详细查看 zabbix 自带 OS Linux 模板)
应用监控
把硬件监控和系统监控研究明白后,我们进一步操作是需要登陆到服务器上查看服务器运行了哪些服务,都需要监控起来。 应用服务监控也是监控体系中比较重要的内容,例如:LVS、Haproxy、Docker、Nginx、PHP、Memcached、Redis、MySQL、Rabbitmq 等等,相关的服务都需要使用zabbix监控起来。
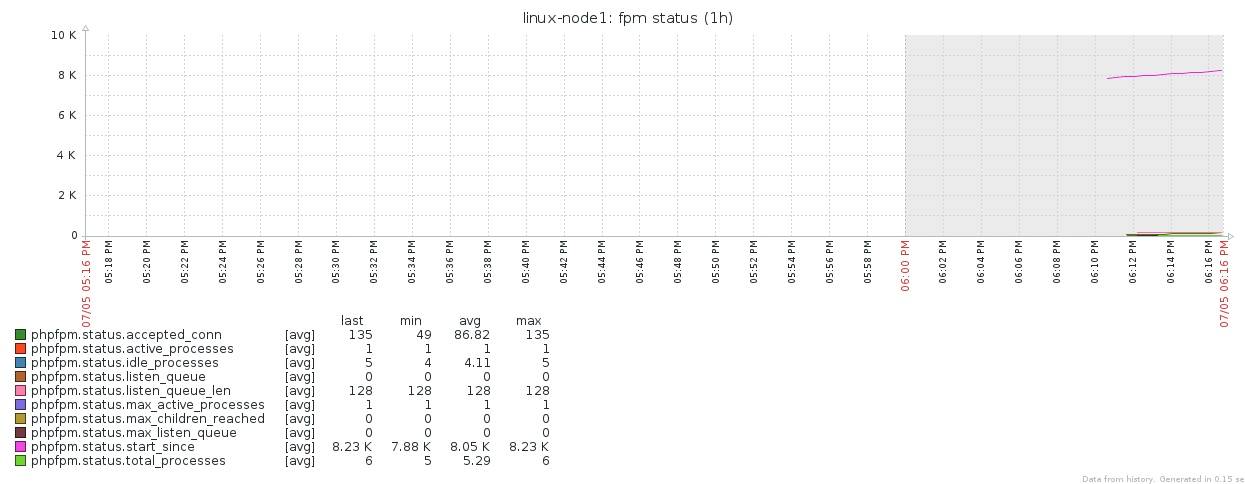
PHP-FPM状态
redis状态
Zabbix 提供应用服务监控:Zabbix Agent UserParameter Zabbix 提供的Java监控:Zabbix JMX Interface percona 提供 MySQL 数据库监控:percona-monitoring-plulgins
网络监控
网络监控是我们构建监控平台时必须要考虑的,尤其是针对有多个机房的场景,各个机房之间的网络状态,机房和全国各地的网络状态都是我们需要重点关注的对象。
需要借助于网络监控工具 Smokeping监控机房链路。
Smokeping 是 rrdtool 的作者 Tobi Oetiker 的作品,是用 Perl 写的,主要是监视网络性能,www 服务器性能,dns 查询性能等,使用 rrdtool 绘图,而且支持分布式,直接从多个 agent 进行数据的汇总。
CDN监控。。。对接第三方接口
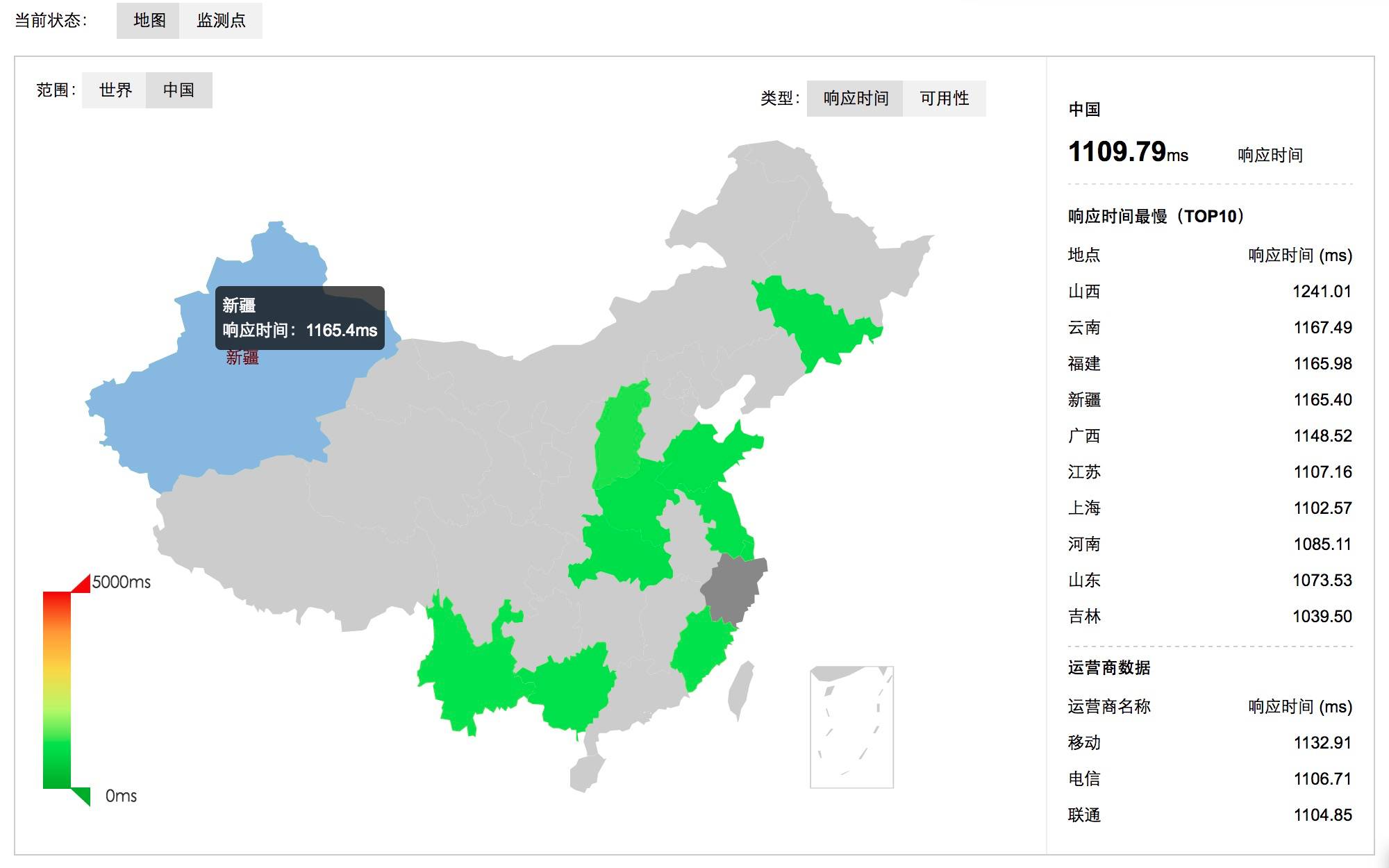
流量分析
网站流量分析对于运维人员来说,更是一门必须掌握的知识了。比如对于300.cn站点来说:
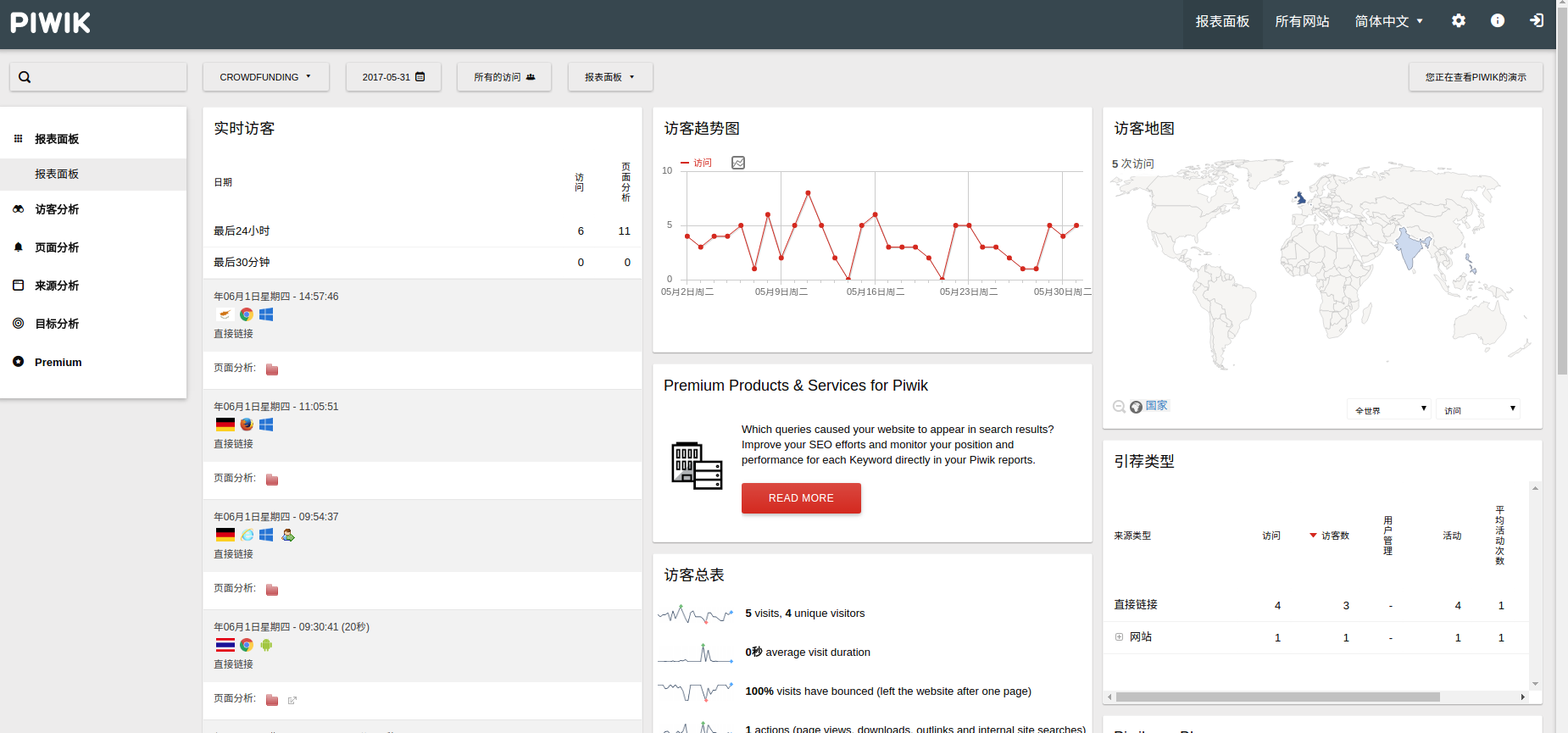
通过对网站来源的统计和分析,可以了解我们在某个网站上的广告投入有没有收到预期的效果。 可以区分不同地区的访问人数、甚至产品交易额等。 百度统计、google 分析、站长工具等等,只需要在页面嵌入一个js即可,但是,数据始终是在对方手中,个性化定制不方便,推荐使用google的piwik开源网站访问统计系统。
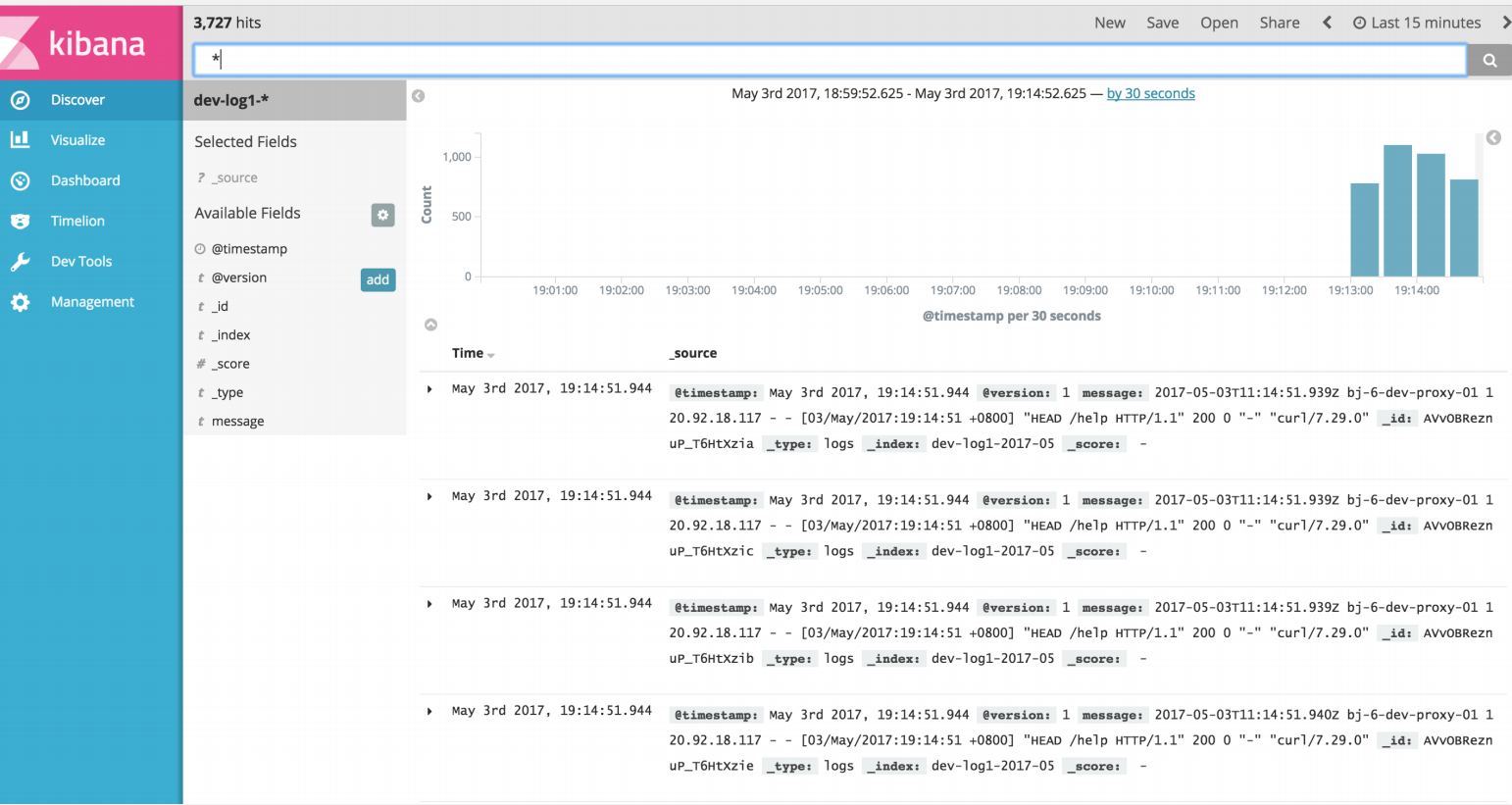
日志监控
通常情况下,随着系统的运行,操作系统会产生系统日志,应用程序会产生应用程序的访问日志、错误日志、运行日志、网络日志,我们可以使用 ELK 来进行日志监控。
对于日志监控来说,最见的需求就是收集、存储、查询、展示。
开源社区正好有相对应的开源项目: logstash(收集) + elasticsearch(存储+搜索) + kibana(展示) 我们将这三个组合起来的技术称之为 ELK Stack,所以说 ELK Stack 指的是 Elasticsearch、Logstash、Kibana 技术栈的结合。
如果收集了日志信息,那么如果部署更新有异常出现,可以立即在 kibana 上看到。
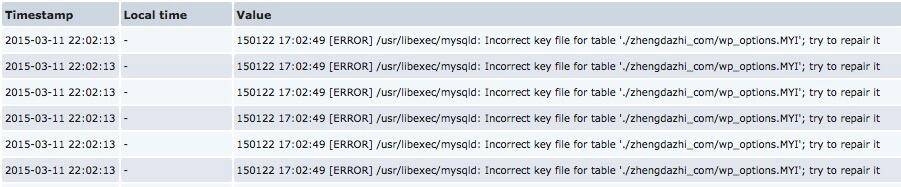
当然也可以通过Zabbix过滤错误日志来进行告警。
安全监控
虽然Linux开源的安全产品不少,比如四层 iptables,七层WEB防护 Nginx+lua 实现 WAF,最后将相关的日志都收至 ELK Stack,通过图形化进行不同的攻击类型展示。但是始终是一件比较耗费时间的事情,并且个人认为效果并不是很好。
API监控
由于微服务架构的推行, API 变得越来越重要,很显然我们也需要这样的数据来分辨我们提供的 API 是否能够正常运作。
监控 API 接口 GET、POST、PUT、DELETE、HEAD、OPTIONS 的请求, 可用性、正确性、响应时间为三大重性能指标

性能监控
全面监控网页性能,DNS 响应时间、HTTP 建立连接时间、页面性能指数、响应时间、可用率、元素大小等
Zabbix 提供 URL监控:Zabbix Web 监控
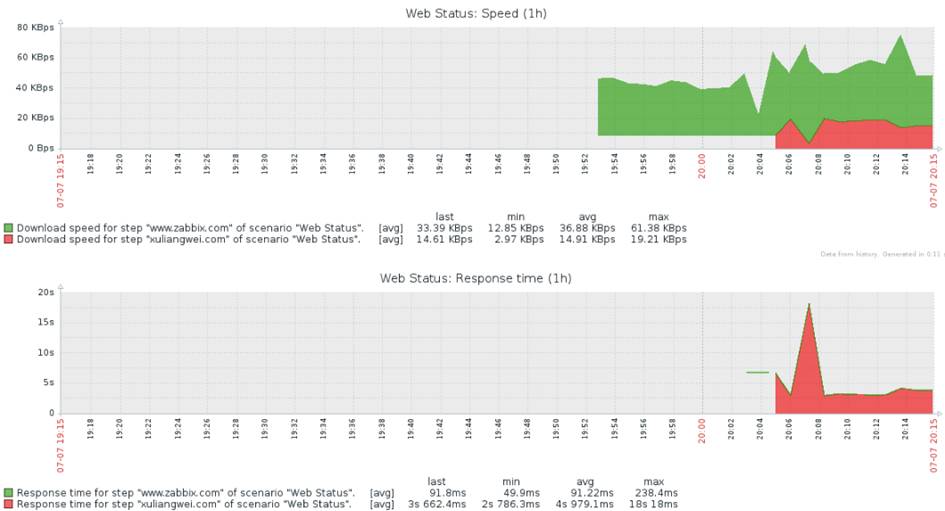
业务监控
没有业务指标监控的监控平台,不是一个完善的监控平台,通常在我们的监控系统中,必须将我们重要的业务指标进行监控,并设置阈值进行告警通知。
例如一个产品集群:
- 每天产生多少订单;
- 每天注册多少用户;
- 每天有多少活跃用户;
- 每天有多少推广活动;
- 推广活动引入多少用户;
- 推广活动引入多少流量;
- 推广活动引入多少利润;
等等 重要指标都可以加到 Zabbix 上,然后通过 screen 展示。
监控报警
故障报警通知的方式有很多种,当然我们最常用的还是短信,邮件
报警处理
一般报警后我们故障如何处理,首先,我们可以通过告警升级机制先自动处理,比如 Nginx 服务 down 了,可以设置告警升级自动启动 Nginx。
但是如果一般业务出现了严重故障,我们通常根据故障的级别,故障的业务,来指派不同的运维人员进行处理。 当然不同业务形态、不同架构、不同服务可能采用的方式都不同,这个没有一个固定的模式套用。
总结
- 监控是一个长期持续的项目, 需要特定的1-2人跟踪改进;
- 监控使用方是业务和运维;
- 业务方应提供监控项获取方法;
- 如果有投诉,先找监控项目组,没有做到“事先”发现问题,监控项目组应该承担其责任;
- 对外提供api,供业务方使用
3.3 - Github开源项目的正确贡献姿势
常见的开源项目贡献指导里都是差不多的样子:
* 要先fork
* 然后change something
* 再然后fetch,rebase
* push origin, 最后发起pull request
具体到不同的项目,可能会要求更多的细节步骤,但大体如上。
这些都没错,但实际操作起来,和习惯不符。因为我一般是先clone一个项目,然后使用中发现有问题,会尝试去修改,fix OK的话,才会想着去贡献代码 可事情到了这一步,再按照一开始的方式操作,会平白无辜耗费很多时间,还涉及到已经修改完代码如何同步过去的问题。 以下是我个人总结的一套方法,屡试不爽乎。
这里我以k8s项目的贡献经历来举例,以备不时之需。git这个东西,不常用,会忘记的,即使你已经理解原理了。。。
-
首先clone K8s的项目代码。
git clone https://github.com/kubernetes/kubernetes.git -
然后自行编译 make, 使用中发现一些问题
就会去github的issue里找找看。。。竟然没人提这个问题,问问同事或同行,人家表示没碰到过你的问题, 好吧,自己尝试去修改... 不断编译 ... 测试... 最终OK了,我要贡献代码!!! 完啦,没有按照最佳习惯来,改动前忘记新建分支了。。。(这个习惯很重要,可以省掉很多麻烦) 只能如此操作了,可以来个大挪移到新建分支上
git stash git checkout -b fix_something git stash apply -
此时去github上fork下原项目,拿到fork后的项目地址,再来个偷天换日。
git remote rename origin upstream git remote add origin git@github.com:xiaoping378/kubernetes.git -
再然后就可以按一开始介绍的,fetch, rebase, push origin, 发起PR了。
git fetch upstream git rebase upstream/master # 有冲突就git mergetool git push origin fix_something # 然后去github页面发起pull request即可。 -
注意事项 值的注意的是,以后在master分支上git pull,就是从upstream/master那里拉取的,和一般情况不一样的地方。 这样会少了烦人的merge msg(-ff可以解决), 还可以用简单的pull来同步上游代码。 更可以意淫自己是原项目的核心开发人员了。。。 以后本地同步fork的项目到上游的最新状态,这样操作:
git checkout master git pull git push origin master其实github上那个fork的项目,只是用来提PR的,这样可以在原项目的分支上任意玩耍了。当然你也可以用来备份一些比较大的feature
-
最后记录下个人的git global配置
# cat ~/.gitconfig [user] email = xiaoping378@163.com name = xiaoping378 [merge] tool = meld [push] default = simple [core] quotepath = false
3.4 - Golang开发-glog日志库
基于Golang 1.7.5版本
软件项目里的日志输出是很重要的环节,可以用于日后BI分析,或者线上调试(万能调试大法printf)等等。
对于当年刚入软件行业时,自己的printf("11111\n")的做法,记忆犹新呀,调试完再删掉自己胡乱加的打印语句,偶尔还有漏删的情况,就commit,push上去了。
golang语言里有个golang/glog包,是类似google内部glog的开源实现,其可以做到无侵入式调试程序,主要是通过启动时命令行传参来控制打印级别。
有以下特性,
- 有四个级别的打印 Info, Warning, Error, Fatal,级别越来越高,分别都支持格式化输出Infof, Warningf, Errorf, Fatalf
- 支持 -v传参,指定打印级别
- 支持 -vmodule=file=2, 指定特殊文件开启打印,避免日志输出过多。
- 支持 -log_dir="", 指定日志输出目录, 默认会按级别输出/tmp目录下, 高级别的会记录到低级别里日志文件里
下面举个简单的例子
//file name: glog.go
package main
import (
"flag"
"github.com/golang/glog"
)
func main() {
flag.Parse()
//flag.Set("logtostderr", "true")
defer glog.Flush()
glog.Info("这里是Info级别的日志")
glog.Warning("这里是Warning级别的日志")
glog.Errorf("这里是Error级别的日志: %s", "error")
glog.V(3).Infoln("级别3的日志")
}
代码如上运行,你需要执行go get github.com/golang/glog下载依赖包, 然后运行
➜ go run glog.go -v 3
E0408 09:35:38.703186 8663 glog.go:15] This is a Error log error
-
Error级别的会输出到标准输出,并记录到文件,
-
日志默认输出到/tmp目录, 每次执行都会记录新的文件,日志文件如下样式命名, glog是文件名,air13是主机名,xxp是用户名
➜ ls /tmp/glog.* -l -rw-rw-r-- 1 xxp xxp 260 4月 8 10:11 /tmp/glog.air13.xxp.log.ERROR.20170408-101153.12771 -rw-rw-r-- 1 xxp xxp 405 4月 8 10:11 /tmp/glog.air13.xxp.log.INFO.20170408-101153.12771 -rw-rw-r-- 1 xxp xxp 334 4月 8 10:11 /tmp/glog.air13.xxp.log.WARNING.20170408-101153.12771 lrwxrwxrwx 1 xxp xxp 46 4月 8 10:11 /tmp/glog.ERROR -> glog.air13.xxp.log.ERROR.20170408-101153.12771 lrwxrwxrwx 1 xxp xxp 45 4月 8 10:11 /tmp/glog.INFO -> glog.air13.xxp.log.INFO.20170408-101153.12771 lrwxrwxrwx 1 xxp xxp 48 4月 8 10:11 /tmp/glog.WARNING -> glog.air13.xxp.log.WARNING.20170408-101153.12771``
-
-v 3指定运行时的记录的日志级别,因为3>=3, 这样V(3).Infoln会输出, 如果是传入-v 2, 则不会 -
go run glog.go -v 2 -logtostderr=true, 则会关闭记录文件,输出到标准输出。 当然可以在程序里加上flag.Set("logtostderr", "true")来关闭记录文件。
总之,glog包对日志的控制非常实用和灵活,大型Golang项目必备包之一。
3.5 - VSCode-开发已有的java项目
个人经验记录:
-
install deps
-
clean workspace
代开设置 Ctrl+Shift+P, 输入
clean java workspaceand restart -
support lombok
java代码出了名的冗长,lombok可以优雅解决此类问题,如果项目依赖了lombok, vsocde打开java项目就会显示各种
cannot be resloved错误,下面是我个人的配置,其中
java.jdt.ls.vmargs的配置(看个人项目maven依赖和安装路径了),会消除错误,并可以支持跳转:{ "window.menuBarVisibility": "toggle", "window.zoomLevel": 1, "explorer.confirmDelete": false, "workbench.colorTheme": "Solarized Dark", "files.associations": { "default": "toml" }, "editor.fontLigatures": true, "java.configuration.checkProjectSettingsExclusions": false, "go.autocompleteUnimportedPackages": true, "java.jdt.ls.vmargs":"-javaagent:/home/xxp/.m2/repository/./org/projectlombok/lombok/1.16.20/lombok-1.16.20.jar -Xbootclasspath/a:/home/xxp/.m2/repository/./org/projectlombok/lombok/1.16.20/lombok-1.16.20.jar" }
参考链接
3.6 - MongoDB之初见
- 手动启动
# 下载二进制
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.4.9.tgz
tar -zxvf mongodb-linux-x86_64-3.4.9.tgz
ln -s $PWD/mongodb-linux-x86_64-3.4.9/bin/* /home/xxp/Software/bin
# 创建数据存储目录
mkdir mongodb
sudo chown -R $USER ./mongodb
mongod -dbpath=$PWD/mongodb
默认监听27017, 根据情况选择关闭warning。
- 推荐调试方法
默认可以使用mongo进入shell交互模式,
亦可使用图形管理界面,推荐robo3T, 目前1.1.1版本在ubuntu桌面上有crash问题,需要如下操作:
curl -O https://download.robomongo.org/1.1.1/linux/robo3t-1.1.1-linux-x86_64-c93c6b0.tar.gz
tar zxvf robo3t-1.1.1-linux-x86_64-c93c6b0.tar.gz
mkdir ~/robo-backup
mv robo3t-1.1.1-linux-x86_64-c93c6b0/lib/libstdc++* ~/robo-backup/
robo3t-1.1.1-linux-x86_64-c93c6b0/bin/robo3t
- 基本使用
shell里敲mongo进入交互界面,
手续推荐查看mongodb中文文档
3.7 - Openldap之拨云见日
很早就听说LDAP/AD之流的企业级概念,认为是做统一用户认证的,具体怎么使用对接,一直有点儿糊涂,今天决定搞明白这些,并深入实践下openldap。
未完...TODO
3.8 - Casbin的权限管理解读
项目一般都要包含权限管理功能,或集成IAM,或自身实现。本文介绍一个强大、高效的开源访问控制框架--Casbin。
基本介绍
Casbin的由来,是出自开源作者罗杨的一篇论文《PML:一种基于Interpreter的Web服务访问控制策略语言》,该论文的主要摘要如下:
为了保护云资源的安全,防止数据泄露和非授权访问,必须对云平台的资源访问实施访问控制.然而,目前主流云平台通常采用自己的安全策略语言和访问控制机制,从而造成两个问题:
- (1)云用户若要使用多个云平台,则需要学习不同的策略语言,分别编写安全策略;
- (2)云服务提供商需要自行设计符合自己平台的安全策略语言及访问控制机制,开发成本较高.
对此,提出一种基于元模型的访问控制策略描述语言PML及其实施机制PML-EM. PML支持表达BLP、RBAC、ABAC等访问控制模型. PML-EM实现了3个性质:
- 策略语言无关性
- 访问控制模型无关性
- 程序设计语言无关性
从而降低了用户编写策略的成本与云服务提供商开发访问控制机制的成本. 在OpenStack云平台上实现了PML-EM机制.实验结果表明,PML策略支持从其他策略进行自动转换, 在表达云中多租户场景时具有优势.性能方面,与OpenStack原有策略相比,PML策略的评估开销为4.8%.PML-EM机制的侵入性较小,与云平台原有代码相比增加约0.42%.
目前Casbin的权限策略管理支持主流的ACL、RBAC、ABAC、RESTful等模型,实现的编程语言主要有Go、java、Nodejs、PHP、Python、.Net、C++、Rust等。目前Go和Java的实现最为全面。
先介绍下主流的访问控制模型:
- ACL(access control list):是一种与访问对象关联的权限列表,在基础设施领域应用非常广泛:
- 文件系统:用户(组)对文件或进程等的访问权限控制
- 网络:常见的有防火墙(安全组、路由器、交换机)内的对目的IP和端口的规则控制
- SQL:库、表的权限管理
- LDAP:层级结构的实体权限管理:网络域权限管理...
- RBAC(role-based access control):基于角色的权限控制,围绕角色和权限定义的策略中立的访问控制机制,和组ACL等价,具体表现为在用户和权限之间加了一层角色,先建立具有某种权限的角色,然后用角色和用户绑定,目前多用于管控类业务系统的权限管理,还支持支持角色权限继承。
- ABAC(Attribute-based access control):基于属性的权限控制,属性可以是用户侧(所属组织、访问IP、访问时间)或资源侧(帖子的评论开关、留言再编辑)的,因为用户或资源的属性是动态的,不像前面两个(需要预先定义好策略,略显死板,,,)被称为是“下一代”的权限模型,可以实现更多元化的策略策略,比如
- 限制用户在什么固定时间段才可以编辑自己的帖子
- 用户只能修改自己项目下的某些资源等
和Casbin结合,使用的基本示意图如下:
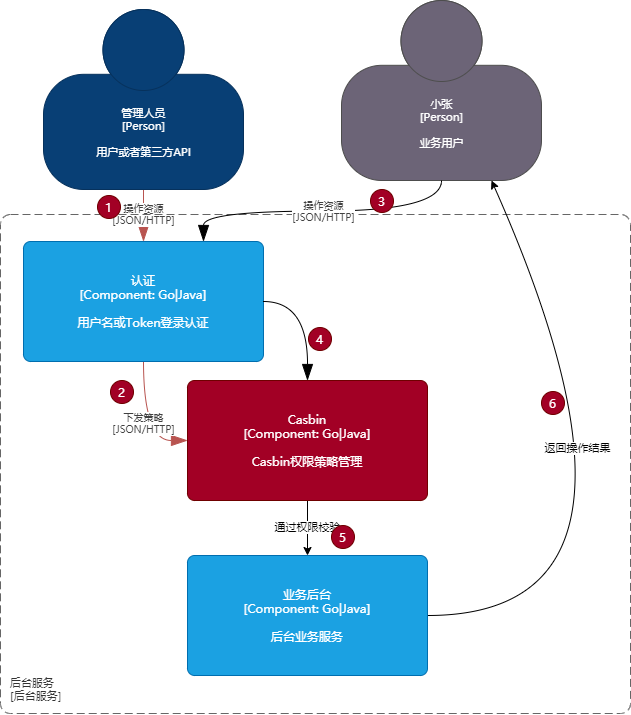
- 1-2为管理人员下发权限策略
- 3-6为用户日常操作资源的简易流程,实际应用场景一般如下:
@startuml
!theme aws-orange
用户 -> 认证中心: 登录操作
认证中心 -> 缓存: 存放(key=token+ip,value=token)token
用户 <- 认证中心 : 认证成功返回token
用户 -> 认证中心: 下次访问头部携带token认证
认证中心 <- 缓存: key=token+ip获取token
Casbin <- 认证中心: 存在且校验成功,则进入授权校验
Casbin -> 其他服务: 权限合规,则跳转到用户请求的其他服务
其他服务 -> 用户: 信息
@enduml
抽象模型
正如上面提到的,要支持这么多的权限模型,,所以Casbin基于开头提到的PML(PERM modeling language)引入一种抽象的元模型控制,其中PERM是指的Policy, Effect, Request, Matchers,具体工作流如下:
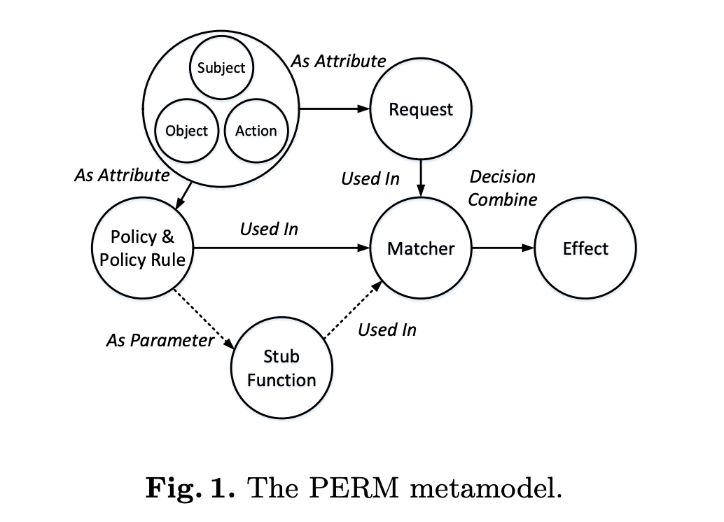
这里的PERM是Casbin在启动时要加载的抽象校验模型,可以理解成一种权限校验模板。 简单说个场景串下这里的概念:
- 管理员分配给用户权限Policy,可以得到
谁能操作什么资源的信息 - 用户发起请求Request,可以得到
谁要操作什么资源的信息 - Casbin拿到Request和Policy做匹配Matcher,也支持自定义函数匹配。
- 根据匹配结果Effect来决定是否允许用户的操作
实际场景中,用户可能被分配了多个权限(角色),那具体权限校验如下:
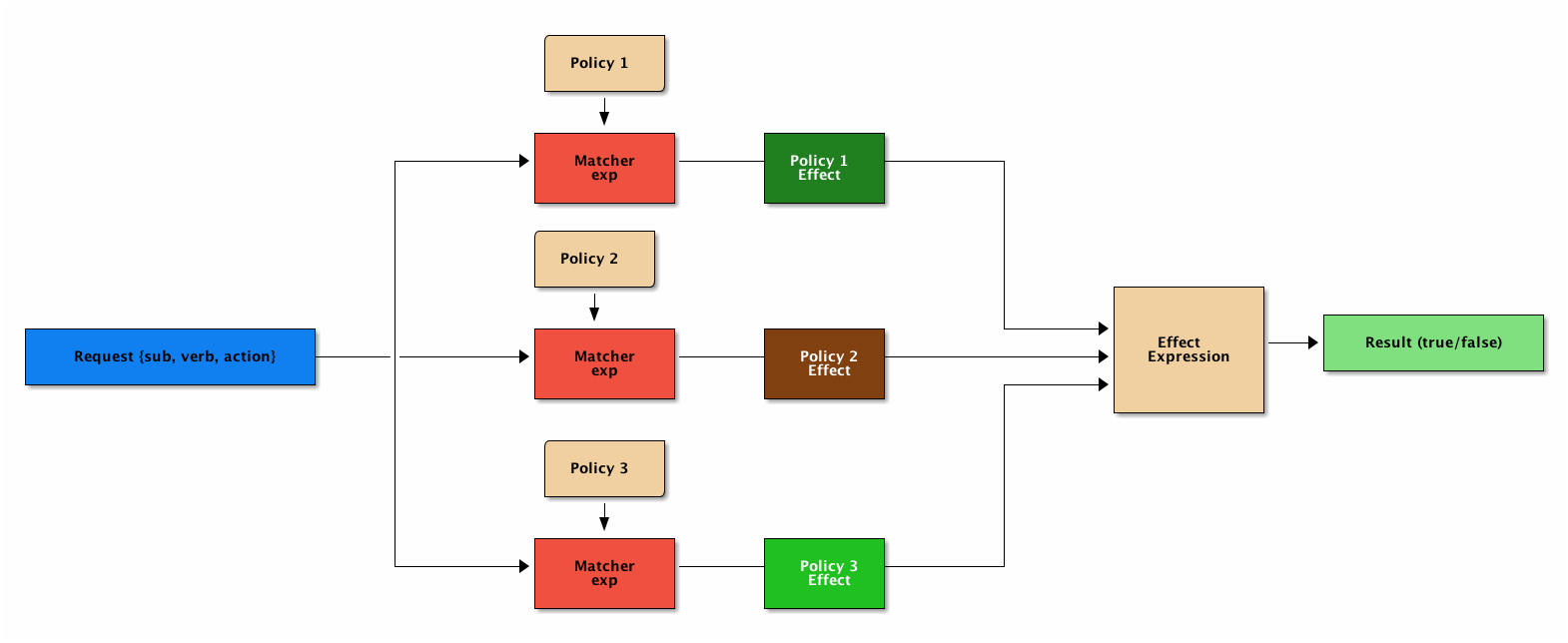
既然是一种语言,就是有语法的,PERM语法至少要有四部分:[request_definition], [policy_definition], [policy_effect], [matchers]。
具体就不展开介绍了,可自行官网详读,effect部分具备SQL背景可能好理些,,,理解不了也没关系,目前就内置了5种:
| Effect | 含义 | 样例 |
|---|---|---|
| some(where (p.eft == allow)) | allow-override | ACL, RBAC, etc. |
| !some(where (p.eft == deny)) | deny-override | Deny-override |
| some(where (p.eft == allow)) && !some(where (p.eft == deny)) | allow-and-deny | Allow-and-deny |
| priority(p.eft) || deny | priority | Priority |
| subjectPriority(p.eft) | priority base on role | Subject-Priority |
奉劝各位看官,既然是语法,就不要纠结里面的命名和写法,较真...就是这么定义的,知道能都有哪些写法就可以了...,实际使用中往往改动Macter的部分。
按场景举例
ACL模型
先定义Casbin要加载的PERM Model,我使用在线编辑器定义一个ACL典型模型:
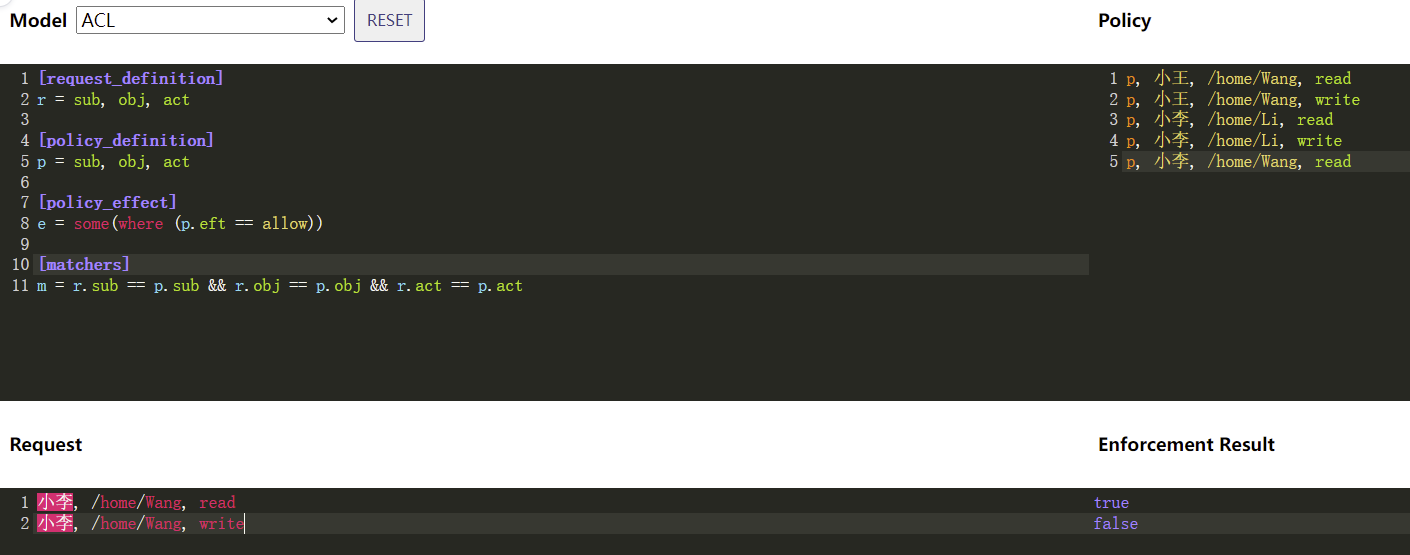
解读如下:
- 左上侧为Casbin启动时要加载的标准ACL Model配置,不需要改动
- 右上侧为Policy部分,属于管理员要分配权限时要改动的部分:示例中定义了5条规则,小王和小李对自己的Home目录可以读写,而小李额外可以读取小王的Home目录
- 左下角Request表明用户的请求,一般是从用户实际发起的请求中获取信息,组合好格式后,用API发起校验,示例中小李发起读和写小王的操作
- 右下角为权限校验结果:示例中小李的写操作被拒绝了
RBAC模型
下图模式的在线编辑地址
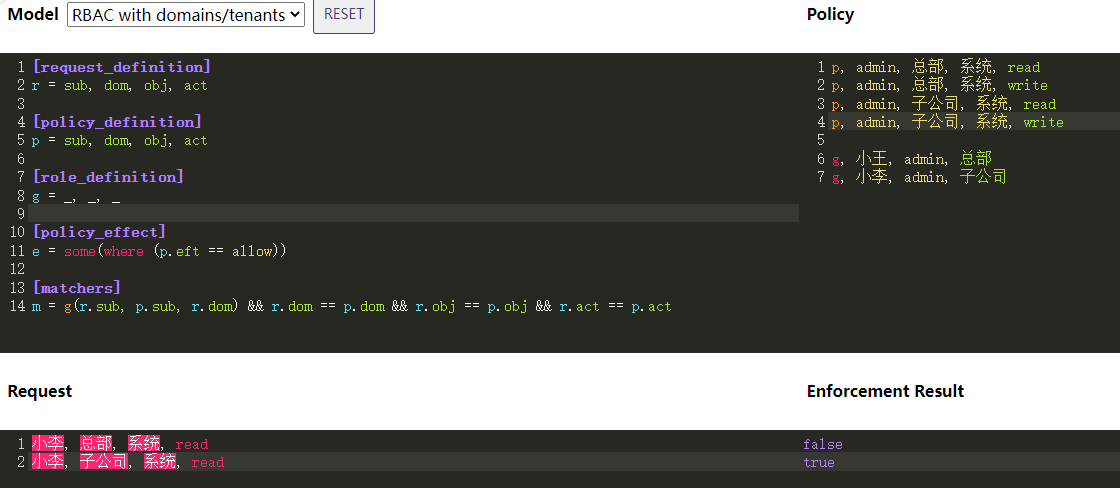
Macters里的g(r.sub, p.sub, r.dom) 将检查用户 r.sub 在域内 r.dom 是否具有角色 p.sub ,这是该匹配器的工作方式。
ABAC模型
上图中RBAC中的Matcher如下修改,即实现了ABAC的模型校验。表明用户必须是被访问资源的Owner才可以操作符合角色权限内的资源。
m = r.obj.Owner == r.sub && (g(r.sub, p.sub, r.dom) && r.dom == p.dom && r.obj == p.obj && r.act == p.act)
总结
Casbin提供了非常灵活的权限校验模型,还提供了丰富的API,方便更便捷的实现业务场景功能, 后面会针对具体的项目开展更贴地气的解读。
参考
3.9 - Windows Terminal终端入坑指南
为了这个东西,重新安装了系统,目前是在windows LTSC 2021版本下的使用指南。 在IT界Terminal和Console差不多是一个意思,同属于界面层面的,不少人老和Shell搞混了,特此说明下Shell一般是指的Bash、zsh、PowerShell、cmd等。
安装
为了使用Windows Terminal,在春节期间,重新安装了LTSC 2021版本的系统(之前一直用的LTSC 2019)。
它对操作系统内部版本的最低要求为
18362.0,通过Win+R输入winver可以确认本机系统是否支持。
目前有三种办法安装(本人选用的第二种):
-
是在应用商店中搜索
Windows Terminal,安装即可。 -
通过Github release页面下载安装包,
Add-AppxPackage Microsoft.WindowsTerminal_<versionNumber>.msixbundle
- 通过命令行winget、Chocolatey 、Scoop 安装,下面以winget为例:
winget install --id=Microsoft.WindowsTerminal -e
配置
现在基本可以图形界面配置了,按照自己的习惯图形操作即可,网上一坨坨的教程,此处不表。
默认配置保存在了%LOCALAPPDATA%\Packages\Microsoft.WindowsTerminal_8wekyb3d8bbwe\LocalState\settings.json
技巧
- 快捷键
- 新建终端 --
Ctrl+Shift+t - 切换终端 --
Alt + Num, (我这里修改过了)
- 新建终端 --
- Quake窗口
- 快捷键是Win + ` , 可以快速从屏幕上半区换出终端窗口
GitBash
本人环境VSCode和git-bash都是绿色版本了,免去了每次重装系统,都进行各种重复的配置操作.
没有环境的可以自行通过上面的连接下载GitBash,后面有时间会尝试下
WSL和WSL2。
中文乱码
需要添加环境变量到~/.bashrc或者~/.zshrc中。
export LANG=zh_CN.UTF-8
绿色改造
绿色改造的核心,一个是安装时不默认安装在C盘,另一个就是设置HOME的系统环境变量,Git-Bash每次启动是可以根据HOME变量,决定加载配置的路径的。
设置系统环境变量,两种办法:
-
图形界面操作:
Win+x-> 系统 -> 高级系统设置 -> 环境变量, 自行添加HOME变量。 -
在PowerShell命令行中设置环境变量,执行完即可生效。
[Environment]::SetEnvironmentVariable("HOME", "D:\xxp", "User")
我这里是D:\xxp目录,这样的话,那些ssh、git、vscode、bash、zsh的自定义配置,都可以免去重装再来一次的痛苦了。
还可以把日常用到exe小工具,也放到$HOME/bin目录下,再加到PATH环境变量里。
[Environment]::SetEnvironmentVariable("Path", [Environment]::GetEnvironmentVariable("Path", "User") + ";D:\xxp\bin","User")
oh-my-zsh主题改造
现在有人直接把zsh装上,然后再安装github上的oh-my-zsh主题,但是启动速度会慢一些,本来bash就比cmd启动慢了,,,
我是在bash的基础上改造下主题,修改Git\etc\profile.d\git-prompt.sh文件,详见这里
之前一直是Bash的基础上,修改了下主题凑活用着。其实可以直接使用zsh的,记录下大致操作。
之前在网上看过的的教程大多是在
bashrc里再启动zsh,会慢上加慢的,我就一直没弄,后来觉得是可以做个Git-zsh环境的。
- 下载zsh二进制
现在msys2上的安装包,都变成zst格式(Facebook家出的)的压缩包了,还需要下载解压工具,我平常使用的就是7z,这里找了个7z with ZS的工具。
解压到GitBash安装的根目录上。主要是/etc/zsh和/usr目录。
- 安装oh-my-zsh主题
sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
- terminal和vscode中使用zsh.exe
- 直接指定
zsh.exe的路径 - 还需要在
~/.zshrc的PATH里添加/mingw64/bin,不然会提示找不到git,
如下是Terminal的配置:
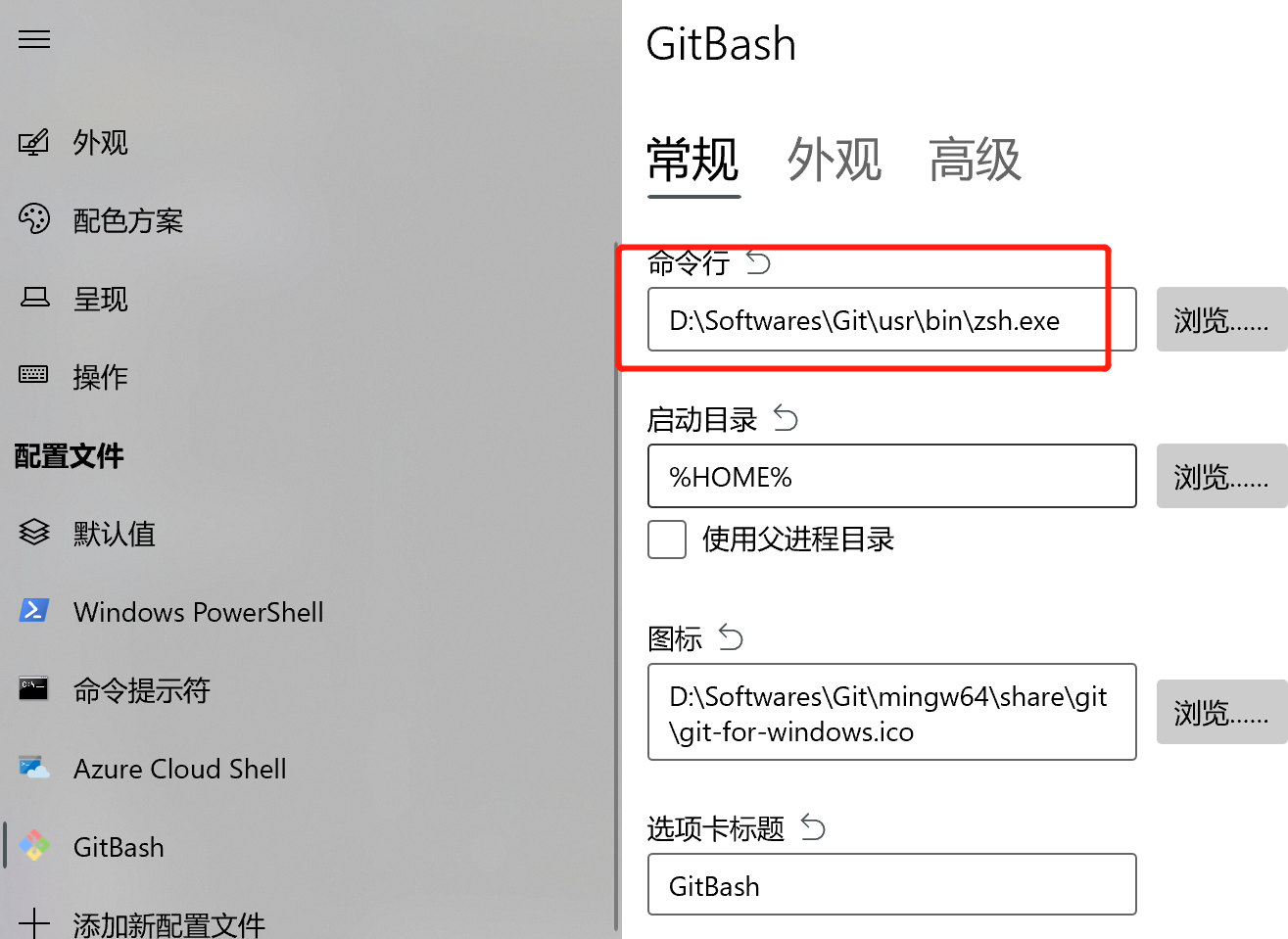
如下是vscode中的配置:
"terminal.integrated.profiles.windows": {
"git-bash": {
"path": "D:\\Softwares\\Git\\usr\\bin\\zsh.exe",
"args": []
}
},
"terminal.integrated.defaultProfile.windows": "git-bash",
3.10 - TiDB分布式数据库
主要介绍TiDB周边生态和实践体验
3.10.1 - TiDB初体验
安装
安装环境要求:
- Mac或者单机Linux环境
- 可以连接外网
- 执行命令安装
TiUP工具,官方运维管理工具。
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
命令会有关键信息输出:添加了证书、修改了PATH变量等,需要声明下环境变量,以使tiup命令能被找到。
- 声明系统环境变量
# 因个人环境,此处会有差异
source ~/.zshrc
可以echo $PATH下,看到/root/.tiup/bin被加到了最前面。
- 启动单实例集群
直接执行tiup playground命令默认会运行最新版本的TiDB集群,其中TiDB Server、TiKV、PD 和 TiFlash 实例各 1 个:
tiup playground
具体如下图所示,需要另开一个终端,使用mysql发起连接:
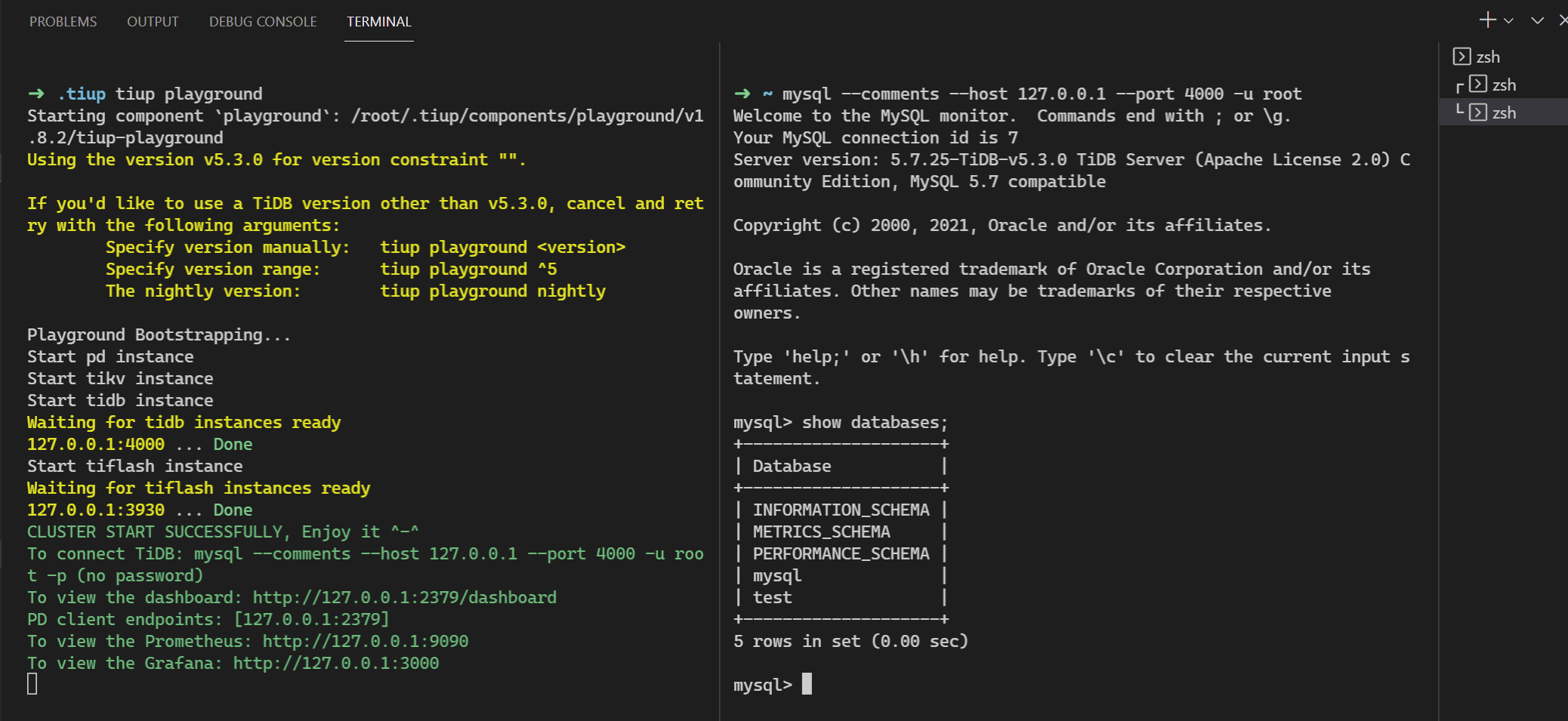
目前tidb playground默认启动监听在127的地址,可以通过--host参数更改,但还不能更改端口(经查代码是写死了端口)。
- 其他可修改参数,可通过
tiup playground -h查看。 - dashboard的默认root用户没有密码,如果是公网暴露了,建议如下添加密码(我这里设置了root密码为
tidb):
mysql -h127.0.0.1 -P4000 -uroot
alter user 'root' identified by 'tidb';
- grafana的登录密码,默认为admin/admin
tiup update --self可升级tiup命令
mysql客户端可通过
yum install -y mysql或者apt install mysql-client安装。
集群
没有多节点的环境,折腾了一下,要单机玩这个模式的话,需要hack的东西太多,,,目前还不建议这么搞,等有时间看能不能提个PR.
TIDB Server
处理client的SQL请求.
PD
提供全局时钟和Region调度和管理(扩缩容)。
TIKV
使用rocksDB实现数据持久化,基于此实现了分布式存储引擎,其中的核心点可以理解为以下三点:
- 事务
- MVCC
- Raft
分布式事务Percolator
基于时间戳的两阶段提交事务解决方案。
MVCC多版本并发控制
COW的本质。默认revision大的为最新值,
多副本Raft一致性
Leader选举:
Term状态变化,follower -> (random timeout) -> candidate -> leader. 此过程因为网络延迟问题,很可能是进行多轮选举。
@startuml
!theme aws-orange
TiKV1 -> TiKV1: 随机选举时间到,切换为candidate角色,进入term2,发出选举信息
TiKV1 -> TiKV2: 发起选举,term=2
TiKV1 -> TiKV3: 发起选举,term=2
TiKV2 -> TiKV2: 对比term(非拜占庭环境,大家默认信任term大的)
TiKV3 -> TiKV3: 对比term
TiKV2 -> TiKV1: 投一票
TiKV3 -> TiKV1: 投一票
TiKV1 -> TiKV1: 超过一半投票(2x+1),成为Leader
TiKV1 -> TiKV2: 心跳保活
TiKV1 -> TiKV3: 心跳保活
TiKV1 -> TiKV1: 异常了
TiKV2 -> TiKV2: 心跳超时,切换candidate角色,进入term3
TiKV2 -> TiKV3: 发起选举
TiKV3 -> TiKV2: 对比term,并投一票
TiKV2 -> TiKV2: 加上自己的一票,超过一半投票,成为Leader
@enduml
leader负责读写请求,follower负责数据多副本复制。日常心跳保活,出问题后,重新选举。
数据写入:
- propose -> append (local) -> Replicate (remote append) -> commited -> apply
@startuml
!theme aws-orange
用户 -> TiDB_Server: 发起事务数据写入
TiDB_Server -> TiDB_Server: 解析语句,SQL -> KV
TiDB_Server -> PD: 获取KV元信息
PD -> TiDB_Server: 告知该key的range leader信息(TiKV1)
TiDB_Server -> TiKV1: 发起propose
TiKV1 -> TiKV1: 本地append为raft_log
TiKV1 -> TiKV2: 发起Replicate复制
TiKV1 -> TiKV3: 发起Replicate复制
TiKV2 -> TiKV2: 本地append为raft_log
TiKV3 -> TiKV3: 本地append为raft_log
TiKV2 -> TiKV1: 反馈已记录成功
TiKV3 -> TiKV1: 反馈已记录成功
TiKV1 -> TiKV1: 收到大多数节点反馈,进入commited状态
TiKV1 -> TiKV2: 发起commited确认
TiKV1 -> TiKV3: 发起commited确认
TiKV2 -> TiKV1: 进入commited
TiKV3 -> TiKV1: 进入commited
TiKV1 -> TiKV1: 收到大多数节点反馈,进入apply状态,此时业务数据才算真正落盘
TiKV1 -> TiKV2: 发起apply确认
TiKV1 -> TiKV3: 发起apply确认
TiKV2 -> TiKV1: 进入apply
TiKV3 -> TiKV1: 进入apply
TiKV1 -> TiDB_Server: 收到一个apply成功反馈,即可反馈用户写入成功
TiDB_Server -> 用户: 反馈写入成功
@enduml
SQL事务的commit对应到这里的apply,这里的commited是指raft中记录上用户的数据更新了(多数据节点记录上用户的写入请求了)。
数据读取:
- tidb server解析SQL语句 -> 从pd获取对应key的tikv节点信息 ->
3.11 - Golang单仓monorepo协作的设计与实践
什么是monorepo
多代码仓合一就是nomorepo,目前在前端领域比较火热,国外大厂如Google、Facebook、Microsoft内也在公司级采用此模式,国内的浮躁,是个项目就上微服务架构的现状,导致代码仓动辄就上几十个,感觉也适合此模式。这东西说起来简单,实际运转起来,需要相应的支撑工具,如代码仓管理、CI/CD适配等,本文主要设计一套可行的方案及记录实践关键过程。
这里说下背景:为什么要研究这个,最近接手一个项目,发现团队积累几乎没有、需求响应进度慢、新成员接手难度大,另外该项目竟然有上百个仓库,哪些和线上正在运行的服务对应,也没有说明,,,相应的协作管理手段也薄弱,总之就是乱,。个人是信服
康威定律(组织沟通方式会通过系统设计表达出来,反之亦成立)的,所以打算尝试下单仓的协作模式,一来可以梳理下以前的需求实现,二来促进组员交流沟通,制定些开发规范和统一框架之类的也好落地。
代码目录结构
CODEOWNERS机制
CI/CD机制
工具实践Lighthouse
4 - 云原生
云原生领域,持续深耕中...
自15年开始接触容器,当时容器就是Docker,Docker就是容器,当然现在docker仍是主流的容器runtime方案,但随着k8s带起来的云原生生态规模落地和全球企业数字化转型的战略倡导,如今也发生了太多变化...此篇会把以前编写的一些文章挪移到此处,顺便开启新的认知。
4.1 - 容器篇
容器基础界还在不断向前发展,持续更新认知。
自15年开始接触容器,当时容器就是Docker,Docker就是容器,当然现在docker仍是主流的容器runtime方案,随着k8s的规模落地,生态也在潜移默化的变化着,此篇会把以前编写的一些文章挪移到此处,顺便开启新的认知。
4.1.1 - 百宝箱脚本
- 备份所有docker镜像
mkdir -p images && cd images
for image in `docker images | grep -v REPOSITORY | awk '{print $1":"$2}'`; do
echo "saving the image of ${image}"
docker save ${image} > ${image////-}.tar
echo -e "finished saving the image of \033[32m ${image} \033[0m"
done
- 批量加载本地tar镜像
for image in `ls *.tar`; do
echo "loading the image of ${image}"
docker load < ${image}
echo -e "finished loading the image of \033[32m ${image} \033[0m"
done
- 批量杀死僵尸进程
ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]' | awk '{print $2}' | xargs kill -9
4.1.2 - docker网络
自去年就开始推动公司业务使用docker了, 至今也一年多了,但对docker网络的认知一直一知半解。。。
主要是太忙,加上线上业务也没出过关于网络吞吐性能方面的问题,就没太大动力去搞明白, 现在闲下来了,搞之!
环境声明
- 以下内容只针对OS: Ubuntu16.04 docker: 1.10.3的环境, 写本文时docker最新的release版本是1.11.2,还有什么CoreOS,Unikernel 之类的(表示都没玩过)。
docker更新迭代速度太快了,公司业务只用到基本功能,所以没动力跟进它的更新了 各种新时代下的产物频出啊, CoreOS为linux的发行版, 没需求,好遗憾.
docker的网络模式
一开始安装完docker, 它就会默认创建3个网络, 使用__docker network ls__查看
➜ blog git:(master) docker network ls
NETWORK ID NAME DRIVER
46416a43fbc6 bridge bridge
45398901e9f0 none null
9440a8140e68 host host
当启动一个容器时, 默认使用bridge模式, 可以通过 --net 指定其它模式。
下面先简要说明下各自的概念
- bridge 模式
容器间之所以能通信,就靠宿主机上的docker0了, docker0就是bridge模式下默认创建的虚拟设备名称
➜ blog git:(master) ✗ ifconfig docker0
docker0 Link encap:Ethernet HWaddr 02:42:49:56:7c:3b
inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:49ff:fe56:7c3b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:78103 errors:0 dropped:0 overruns:0 frame:0
TX packets:47578 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:17485434 (17.4 MB) TX bytes:82163889 (82.1 MB)
ifocnfig可以看到很多信息, mac地址,IP等这些也可以通过参数指定成别的。
- none模式
none网络模式下的容器里是缺少网络接口的,例如eth0等,但会有一个lo设备。
没用过也没见过这样的业务场景, 不做过多说明
- host模式
容器直接操作宿主机的网络栈, 无疑是性能最好的网络模式, 可以认为是无带宽损耗的。
细说bridge模式
这也是我们线上正在在用的网络模式。
bridge模式主要利用了iptables的Masquerading和DNAT功能。
未完。。。
4.1.3 - Swarm篇
Docker内置容器编排方案
当年的swarm、k8s、mesos三大系统竞争之激烈,现在都归于k8s了。
4.1.3.1 - 构建生产环境级的docker Swarm集群-1
此文档适用于低于1.12版本的docker,之后swarm已内置于docker-engine里。
- 硬件需求
至少5台PC服务器, 分别如下作用
- manager0
- manager1
- consul0
- node0
- node1
- 每台PC上安装docker-engine
一台一台的ssh上去执行,或者使用ansible批量部署工具。
安装docker-engine
curl -sSL https://get.docker.com/ | sh
启动之,并使之监听2375端口
sudo docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
亦可修改配置,使之永久生效
mkdir /etc/systemd/system/docker.service.d
cat <<EOF >>/etc/systemd/system/docker.service.d/docker.conf
[Service]
ExecStart=
ExecStart=/usr/bin/docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --dns 180.76.76.76 --insecure-registry registry.cecf.com -g /home/Docker/docker
EOF
- 启动discovery后台
在consul0上启动consul服务,manager用其来认证node连接并存储node状态, 理应建立discovery的高可用,这里简化之
docker run -d -p 8500:8500 --name=consul progrium/consul -server -bootstrap
- 创建Swarm集群
在manager0上创建the primary manager, 自行替换manager0_ip和consul0_ip的真实IP地址。
docker run -d -p 4000:4000 swarm manage -H :4000 --replication --advertise <manager0_ip>:4000 consul://<consul0_ip>:8500
在manager1上启动replica manger
docker run -d -p 4000:4000 swarm manage -H :4000 --replication --advertise <manager1_ip>:4000 consul://<consul0_ip>:8500
--replication
- 在node上执行加入集群操作
分别在node0和node1上执行加入集群操作
docker run -d swarm join --advertise=<node_ip>:2375 consul://<consul0_ip>:8500
- 在manger0上查看集群状态
docker -H :4000 info
4.1.3.2 - 构建生产环境级的docker Swarm集群-2
此文档适用于不低于1.12版本的docker,因为swarm已内置于docker-engine里。
- 硬件需求
这里以5台PC服务器为例, 分别如下作用
- manager0
- manager1
- node0
- node1
- node2
- 每台PC上安装docker-engine
一台一台的ssh上去执行,或者使用ansible批量部署工具。
安装docker-engine
curl -sSL https://get.docker.com/ | sh
启动之,并使之监听2375端口
sudo docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
亦可修改配置,使之永久生效
mkdir /etc/systemd/system/docker.service.d
cat <<EOF >>/etc/systemd/system/docker.service.d/docker.conf
[Service]
ExecStart=
ExecStart=/usr/bin/docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --dns 180.76.76.76 --insecure-registry registry.cecf.com -g /home/Docker/docker
EOF
如果开启了防火墙,需要开启如下端口
- TCP port 2377 for cluster management communications
- TCP and UDP port 7946 for communication among nodes
- TCP and UDP port 4789 for overlay network traffic
- 创建swarm
docker swarm init --advertise-addr <MANAGER-IP>
我的实例里如下:
[root@manager0 ~]# docker swarm init --advertise-addr 10.42.0.243
Swarm initialized: current node (e5eqi0lue90uidzsfddeqwfl8) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-3iskhw3lsc9pkdtijj1d23lg9tp7duj18f477i5ywgezry7zlt-dfwjbsjleoajcdj13psu702s6 \
10.42.0.243:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
使用 --advertise-addr 来声明manager0的IP,其他的nodes必须可以和此IP互通,
一旦完整初始化,此node即是manger又是worker node.
通过docker info来查看
$ docker info
Containers: 2
Running: 0
Paused: 0
Stopped: 2
...snip...
Swarm: active
NodeID: e5eqi0lue90uidzsfddeqwfl8
Is Manager: true
Managers: 1
Nodes: 1
...snip...
通过docker node ls来查看集群的node信息
[root@manager0 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
e5eqi0lue90uidzsfddeqwfl8 * manager0 Ready Active Leader
这里的*来指明docker client正在链接在这个node上。
- 加入swarm集群
执行在manager0上产生docker swarm init产生的结果即可
如果当时没记录下来,还可以在manager上补看 想把node以worker身份加入,在manager0上执行下面的命令来补看。
docker swarm join-token worker
想把node以manager身份加入,在manager0上执行下面的命令来来补看。
docker swarm join-token manager
为了manager的高可用,我这里需要在manager1上执行
docker swarm join \
--token SWMTKN-1-3iskhw3lsc9pkdtijj1d23lg9tp7duj18f477i5ywgezry7zlt-86dk7l9usp1yh4uc3rjchf2hu \
10.42.0.243:2377
我这里就是依次在node0-2上执行
docker swarm join \
--token SWMTKN-1-3iskhw3lsc9pkdtijj1d23lg9tp7duj18f477i5ywgezry7zlt-dfwjbsjleoajcdj13psu702s6 \
10.42.0.243:2377
这样node就会加入之前我们创建的swarm集群里。
再通过docker node ls来查看现在的集群情况, swarm的集群里是以node为实例的
[root@manager0 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
0tr5fu8ebi27cp2ot210t67fx manager1 Ready Active Reachable
46irkik4idjk8rjy7pqjb84x0 node1 Ready Active
79hlu1m7x9p4cc4npa4xjuax3 node0 Ready Active
9535h8ow82s8mzuw5kud2mwl3 consul0 Ready Active
e5eqi0lue90uidzsfddeqwfl8 * manager0 Ready Active Leader
这里MANAFER标明各node的身份,空即为worker身份。
- 部署服务
Usage: docker service COMMAND
Manage Docker services
Options:
--help Print usage
Commands:
create Create a new service
inspect Display detailed information on one or more services
ps List the tasks of a service
ls List services
rm Remove one or more services
scale Scale one or multiple services
update Update a service
部署示例如下:
docker service create --replicas 2 --name helloworld alpine ping 300.cn
docker service ls罗列swarm集群的所有services
docker service ps helloworld查看service部署到了哪个node上
docker service inspect helloworld 查看service 资源、状态等具体信息
docker servcie scale helloworld=5来扩容service的个数
docker service rm helloworld 来删除service
docker service update 来实现更新service的各项属性,包括滚动升级等。
可更新的属性包含如下:
Usage: docker service update [OPTIONS] SERVICE
Update a service
Options:
--args string Service command args
--constraint-add value Add or update placement constraints (default [])
--constraint-rm value Remove a constraint (default [])
--container-label-add value Add or update container labels (default [])
--container-label-rm value Remove a container label by its key (default [])
--endpoint-mode string Endpoint mode (vip or dnsrr)
--env-add value Add or update environment variables (default [])
--env-rm value Remove an environment variable (default [])
--help Print usage
--image string Service image tag
--label-add value Add or update service labels (default [])
--label-rm value Remove a label by its key (default [])
--limit-cpu value Limit CPUs (default 0.000)
--limit-memory value Limit Memory (default 0 B)
--log-driver string Logging driver for service
--log-opt value Logging driver options (default [])
--mount-add value Add or update a mount on a service
--mount-rm value Remove a mount by its target path (default [])
--name string Service name
--publish-add value Add or update a published port (default [])
--publish-rm value Remove a published port by its target port (default [])
--replicas value Number of tasks (default none)
--reserve-cpu value Reserve CPUs (default 0.000)
--reserve-memory value Reserve Memory (default 0 B)
--restart-condition string Restart when condition is met (none, on-failure, or any)
--restart-delay value Delay between restart attempts (default none)
--restart-max-attempts value Maximum number of restarts before giving up (default none)
--restart-window value Window used to evaluate the restart policy (default none)
--stop-grace-period value Time to wait before force killing a container (default none)
--update-delay duration Delay between updates
--update-failure-action string Action on update failure (pause|continue) (default "pause")
--update-parallelism uint Maximum number of tasks updated simultaneously (0 to update all at once) (default 1)
-u, --user string Username or UID
--with-registry-auth Send registry authentication details to swarm agents
-w, --workdir string Working directory inside the container
4.1.3.3 - 构建生产环境级的docker Swarm集群-3
如前文所述,默认已经搭建好环境,基于docker1.12版本。
[root@manager0 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
0bbmd3r7aphs374qaea4zcieo node2 Ready Active
3qmxzyauc0bz4kjqvld9uogz5 manager1 Ready Active Reachable
5ewbdtvaopj4ltwqx0a4i65nt * manager0 Ready Drain Leader
5oxxpgk69fnwe5w210kovrqi9 node1 Ready Active
7s1ilay2wkjgt09bp2z0743m7 node0 Ready Active
- 创建第一个服务,以redis为例 swarm里容器间通信需要使用overlay模式,所以需要提前建立一个
docker network create -d overlay --subnet 10.254.0.0/16 --gateway 10.254.0.1 mynet1
docker service create --name redis --network mynet1 redis
- 在manager上查看服务部署情况
[root@manager0 ~]# docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
9avksjfqr2gxm413dfrezrmgr redis.1 redis node1 Running Running 17 seconds ago
实例里,同样可以去node1上用docker ps查看
以上只是最基本的集群创建服务的用法,从中可见,swarm的的调度基本单元是task, 没有pod的概念,一个task可以简单理解成一个docker run的结果。目前swarm里也不支持compose。
docker官方称,以后会支持vm、pod的调度单元,具体日期未知。
- 服务调度策略
使用docker service create创建服务, 这其中选择再哪个节点部署,docker 提供了三种调度策略;
- spread: 默认策略,尽量均匀分布,找容器数少的结点调度
- binpack: 和spread相反,尽量把一个结点占满再用其他结点
- random: 随机
- 服务的高可用和load-balance
通过--replicas参数可以设置服务容器的数量,已达到高可用状态;
#创建多副本
docker service update --replicas 4 redis
#查看副本部署情况
[root@manager0 ~]# docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
9avksjfqr2gxm413dfrezrmgr redis.1 redis node1 Running Running 13 minutes ago
0olv1sfz6d79wdnorw7jgoyri redis.2 redis manager1 Running Running about a minute ago
f3n6deesjlkxu4k48lzabieus redis.3 redis node2 Running Preparing 3 minutes ago
80bzarvkiytpv1690sla6unt2 redis.4 redis node0 Running Running about a minute ago
#验证多可用, 总共4个副本,docker内置的DNS服务会默认使用round-robin调度策略来解析主机。
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> set user 1
OK
redis:6379> exit
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> get user
(nil)
redis:6379> set user 2
OK
redis:6379> exit
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> get user
(nil)
redis:6379> set user 3
OK
redis:6379> exit
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> get user
(nil)
redis:6379> set user 4
OK
redis:6379> exit
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> get user
"1"
redis:6379>
4.1.4 - 从docker迁移到containerd
记录个人从docker迁移到containerd的事项
介绍
https://github.com/containerd/containerd
TODO.
安装containerd
下载必要组件:https://github.com/containerd/nerdctl/releases,
4.2 - Kubernetes
主要介绍k8s的核心功能和周边生态
4.2.1 - 源码部署K8S
此文应该不能运行成功了,,,陈年老文,有待验证。
一. 先介绍最省事的部署方法,直接从官网下release版本安装:
git clone 代码步骤省略 ...
- 下载各依赖的release版本
通过修改配置文件 cluster/centos/config-build.sh, 可自定义(k8s, docker, flannel, etcd)各自的下载地址和版本, 不同的版本的依赖可能会需要小改下脚本(版本变更有些打包路径发生了变化,兼容性问题)
cd cluster/centos && ./build.sh all
- 安装并启动k8s集群环境
通过修改配置文件 cluster/centos/config-default.sh,定义你环境里的设备的IP和其他参数,推荐运行脚本前先通过ssh-copy-id做好免密钥认证;
export KUBERNETES_PROVIDER=centos && cluster/kube-up.sh
二. 源码级编译安装
本步骤基于上一大步来说, 先来看下载各依赖的release后,cluster/centos下目录发生了什么变化
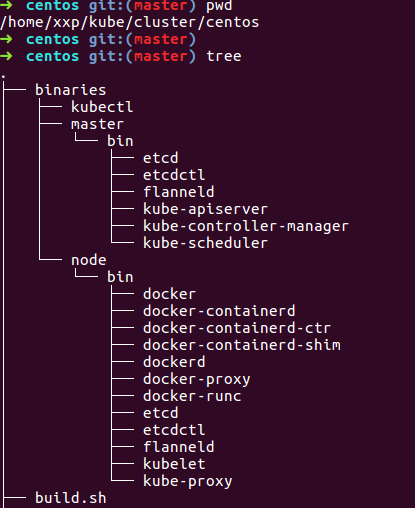
多了一个binaries的目录,里面是各master和minion上各依赖的二进制文件, 所以我们只要源码编译的结果,替换到这里来, 然后继续上一大步的第2小步即可。
这里说下,本地编译k8s的话,需要设置安装godep,然后命令本地化。
export PATH=$PATH:$GOPATH/bin
最后只需要去源码根目录下执行, 编译结果在_output目录下
make
替换到相应的binaries目录下,重新运行kube-up.sh即可。
4.2.2 - 离线安装kubernetes
虽然距离当前主流版本已经差之千里,但其中的思想仍记得借鉴。
经常遇到全新初始安装k8s集群的问题,所以想着搞成离线模式,本着最小依赖原则,提高安装速度
基于Centos7-1511-minimal, 非此版本脚本应该会运行出错,自行修改吧
本离线安装所有的依赖都打包放到了百度网盘
为了便于维护,已建立独立项目k8s-deploy
第一步
基本思路是,在k8s-deploy目录下,临时启个http server, node节点上会从此拉取所依赖镜像和rpms
# python -m SimpleHTTPServer
Serving HTTP on 0.0.0.0 port 8000 ...
windows上可以用hfs临时启个http server, 自行百度如何使用
master侧
运行以下命令,初始化master
192.168.56.1:8000 是我的http-server, 注意要将k8s-deploy.sh 里的HTTP-SERVER变量也改下
curl -L http://192.168.56.1:8000/k8s-deploy.sh | bash -s master
minion侧
视自己的情况而定
curl -L http://192.168.56.1:8000/k8s-deploy.sh | bash -s join --token=6669b1.81f129bc847154f9 192.168.56.100
总结
整个脚本实现比较简单, 坑都在脚本里解决了。脚本文件在这里
就一个master-up和node-up, 基本一个函数只做一件事,很清晰,可以自己查看具体过程。
1.5 与 1.3给我感觉最大的变化是网络部分, 1.5启用了cni网络插件 不需要像以前一样非要把flannel和docker绑在一起了(先启flannel才能启docker)。
具体可以看这里 https://github.com/containernetworking/cni/blob/master/Documentation/flannel.md
master侧如果是单核的话,会因资源不足, dns安装失败。
4.2.3 - k8s的各组件和特性扫盲
了解一个工具的特性可以从它的参数入手
api-server
在k8s内发挥的网关和api
CSR特性
网络
flannel
-
flannel的设计就是为集群中所有节点能重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址, 并让属于不同节点上的容器能够直接通过内网IP通信。
-
实际上就是给每个节点的docker重新设置容器上可分配的IP段,
--bip的妙用。 这恰好迎合了k8s的设计,即一个pod(container)在集群中拥有唯一、可路由到的IP,带来的好处就是减少跨主机容器间通信要port mapping的复杂性。 -
原理
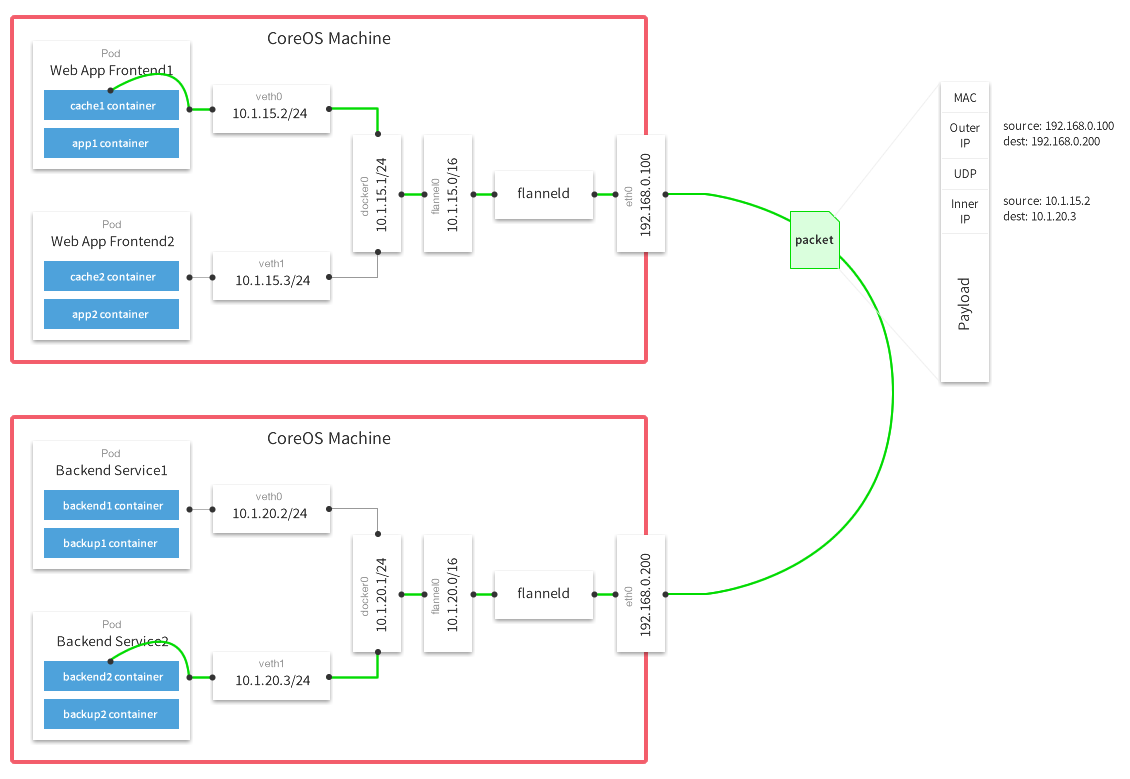
- flannle需要运行一个叫flanned的agent,其用etcd来存储网络配置、已经分配的子网、和辅助信息(主机IP),如下
[root@master1 ~]# etcdctl ls /coreos.com/network /coreos.com/network/config /coreos.com/network/subnets [root@master1 ~]# [root@master1 ~]# etcdctl get /coreos.com/network/config {"Network":"172.16.0.0/16"} [root@master1 ~]# [root@master1 ~]# etcdctl ls /coreos.com/network/subnets /coreos.com/network/subnets/172.16.29.0-24 /coreos.com/network/subnets/172.16.40.0-24 /coreos.com/network/subnets/172.16.60.0-24 [root@master1 ~]# [root@master1 ~]# etcdctl get /coreos.com/network/subnets/172.16.29.0-24 {"PublicIP":"192.168.1.129"}-
flannel0 还负责解封装报文,或者创建路由。 flannel有多种方式可以完成报文的转发。
- UDP
- vxlan
- host-gw
- aws-vpc
- gce
- alloc
下图是经典的UDP封装方式数据流图
4.2.4 - Helm模板介绍
概要
-
Helm是一个管理kubernetes集群内应用的工具,提供了一系列管理应用的快捷方式,例如 inspect, install, upgrade, delete等,经验可以沿用以前apt,yum,homebrew的,区别就是helm管理的是kubernetes集群内的应用。
-
还有一个概念必须得提,就是
chart, 它代表的就是被helm管理的应用包,里面具体就是放一些预先配置的Kubernetes资源(pod, rc, deployment, service, ingress),一个包描述文件(Chart.yaml), 还可以通过指定依赖来组织成更复杂的应用,支持go template语法,可参数化模板,让使用者定制化安装 charts可以存放在本地,也可以放在远端,这点理解成yum仓很合适。。。
这里有个应用市场 ,里面罗列了各种应用charts。由开源项目monocular支撑
下面主要介绍helm的基本使用流程和具体场景的实践。
初始化k8s集群v1.6.2
先来准备k8s环境,可以通过k8s-deploy项目来离线安装高可用kubernetes集群,我这里是单机演示环境。
kubeadm init --kubernetes-version v1.6.2 --pod-network-cidr 12.240.0.0/12
#方便命令自动补全
source <(kubectl completion zsh)
#安装cni网络
cp /etc/kubernetes/admin.conf $HOME/.kube/config
kubectl apply -f kube-flannel-rbac.yml
kubectl apply -f kube-flannel.yml
#使能master可以被调度
kubectl taint node --all node-role.kubernetes.io/master-
#安装ingress-controller, 边界路由作用
kubectl create -f ingress-traefik-rbac.yml
kubectl create -f ingress-traefik-deploy.yml
这样一个比较完整的k8s环境就具备了,另外监控和日志不在此文的讨论范围内。
初始化Helm环境
由于刚才创建的k8s集群默认启用RBAC机制,个人认为这个特性是k8s真正走向成熟的一大标志,废话不表,为了helm可以安装任何应用,我们先给他最高权限。
kubectl create serviceaccount helm --namespace kube-system
kubectl create clusterrolebinding cluster-admin-helm --clusterrole=cluster-admin --serviceaccount=kube-system:helm
初始化helm,如下执行,会在kube-system namepsace里安装一个tiller服务端,这个服务端就是用来解析helm语义的,后台再转成api-server的API执行:
➜ helm init --service-account helm
$HELM_HOME has been configured at /home/xxp/.helm.
Tiller (the helm server side component) has been installed into your Kubernetes Cluster.
Happy Helming!
➜ helm version
Client: &version.Version{SemVer:"v2.4.1", GitCommit:"46d9ea82e2c925186e1fc620a8320ce1314cbb02", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.4.1", GitCommit:"46d9ea82e2c925186e1fc620a8320ce1314cbb02", GitTreeState:"clean"}
#命令行补全
➜ source <(helm completion zsh)
安装第一个应用
初始化Helm后,默认就导入了2个repos,后面安装和搜索应用时,都是从这2个仓里出的,当然也可以自己通过helm repo add添加本地私有仓
➜ helm repo list
NAME URL
stable https://kubernetes-charts.storage.googleapis.com
local http://127.0.0.1:8879/charts
其实上面的repo仓的索引信息是存放在~/.helm/repository的, 类似/etc/yum.repos.d/的作用
helm的使用基本流程如下:
- helm search: 搜索自己想要安装的应用(chart)
- helm fetch: 下载应用(chart)到本地,可以忽略此步
- helm install: 安装应用
- helm ls: 查看已安装的应用情况
这里举例安装redis
➜ helm install stable/redis --set persistence.enabled=false
如上,如果网络给力的话,很快就会装上最新的redis版本,Helm安装应用,目前有四种方式:
helm install stable/mariadb通过chart仓来安装helm install ./nginx-1.2.3.tgz通过本地打包后的压缩chart包来安装helm install ./nginx通过本地的chart目录来安装helm install https://example.com/charts/nginx-1.2.3.tgz通过绝对网络地址来安装chart压缩包
实战演示
主要从制作自己的chart, 构建自己的repo, 组装复杂应用的实战三方面来演示
制作自己的chart
helm有一个很好的引导教程模板, 如下会自动创建一个通用的应用模板
➜ helm create myapp
Creating myapp
➜ tree myapp
myapp
├── charts //此应用包的依赖包定义(如果有的话,也会是类似此包的目录结构)
├── Chart.yaml // 包的描述文件
├── templates // 包的主体目录
│ ├── deployment.yaml // kubernetes里的deployment yaml文件
│ ├── _helpers.tpl // 模板里如果复杂的话,可能需要函数或者其他数据结构,这里就是定义的地方
│ ├── ingress.yaml // kubernetes里的ingress yaml文件
│ ├── NOTES.txt // 想提供给使用者的一些注意事项,一般提供install后,如何访问之类的信息
│ └── service.yaml // kubernetes里的service yaml文件
└── values.yaml // 参数的默认值
2 directories, 7 files
如上操作,我们就有了一个myapp的应用,目录结构如上,来看看看values.yaml的内容, 这个里面就是模板里可定制参数的默认值
很容易看到,kubernetes里的rc实例数,镜像名,servie配置,路由ingress配置都可以轻松定制。
# Default values for myapp.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
replicaCount: 1
image:
repository: nginx
tag: stable
pullPolicy: IfNotPresent
service:
name: nginx
type: ClusterIP
externalPort: 80
internalPort: 80
ingress:
enabled: false
# Used to create Ingress record (should used with service.type: ClusterIP).
hosts:
- chart-example.local
annotations:
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
tls:
# Secrets must be manually created in the namespace.
# - secretName: chart-example-tls
# hosts:
# - chart-example.local
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 100m
memory: 128Mi
note.
一般拿到一个现有的app chart后,这个文件是必看的,通过
helm fetch myapp会得到一个类似上面目录的压缩包
我们可以通过 --set或传入values.yaml文件来定制化安装,
# 安装myapp模板: 启动2个实例,并可通过ingress对外提供myapp.192.168.31.49.xip.io的域名访问
➜ helm install --name myapp --set replicaCount=2,ingress.enabled=true,ingress.hosts={myapp.192.168.31.49.xip.io} ./myapp
➜ helm ls
NAME REVISION UPDATED STATUS CHART NAMESPACE
exasperated-rottweiler 1 Wed May 10 13:58:56 2017 DEPLOYED redis-0.5.2 default
myapp 1 Wed May 10 21:46:51 2017 DEPLOYED myapp-0.1.0 default
#通过传入yml文件来安装
#helm install --name myapp -f myvalues.yaml ./myapp
构建私有charts repo
通过 helm repo list, 得知默认的local repo地址是http://127.0.0.1:8879/charts, 可以简单的通过helm serve来操作,再或者自己起个web server也是一样的。
这里举例,把刚才创建的myapp放到本地仓里
➜ helm search myapp
No results found
➜
➜ source <(helm completion zsh)
➜
➜ helm package myapp
➜
➜ helm serve &
[1] 10619
➜ Regenerating index. This may take a moment.
Now serving you on 127.0.0.1:8879
➜ deis helm search myapp
NAME VERSION DESCRIPTION
local/myapp 0.1.0 A Helm chart for Kubernetes
目前个人感觉体验不太好的是,私有仓里的app必须以tar包的形式存在。
构建复杂应用
透过例子学习,会加速理解,我们从deis里的workflow应用来介绍
➜ ~ helm repo add deis https://charts.deis.com/workflow
"deis" has been added to your repositories
➜ ~
➜ ~ helm search workflow
NAME VERSION DESCRIPTION
deis/workflow v2.14.0 Deis Workflow
➜ ~
➜ ~ helm fetch deis/workflow --untar
➜ ~ helm dep list workflow
NAME VERSION REPOSITORY STATUS
builder v2.10.1 https://charts.deis.com/builder unpacked
slugbuilder v2.4.12 https://charts.deis.com/slugbuilder unpacked
dockerbuilder v2.7.2 https://charts.deis.com/dockerbuilder unpacked
controller v2.14.0 https://charts.deis.com/controller unpacked
slugrunner v2.3.0 https://charts.deis.com/slugrunner unpacked
database v2.5.3 https://charts.deis.com/database unpacked
fluentd v2.9.0 https://charts.deis.com/fluentd unpacked
redis v2.2.6 https://charts.deis.com/redis unpacked
logger v2.4.3 https://charts.deis.com/logger unpacked
minio v2.3.5 https://charts.deis.com/minio unpacked
monitor v2.9.0 https://charts.deis.com/monitor unpacked
nsqd v2.2.7 https://charts.deis.com/nsqd unpacked
registry v2.4.0 https://charts.deis.com/registry unpacked
registry-proxy v1.3.0 https://charts.deis.com/registry-proxy unpacked
registry-token-refresher v1.1.2 https://charts.deis.com/registry-token-refresher unpacked
router v2.12.1 https://charts.deis.com/router unpacked
workflow-manager v2.5.0 https://charts.deis.com/workflow-manager unpacked
➜ ~ ls workflow
charts Chart.yaml requirements.lock requirements.yaml templates values.yaml
如上操作,我们会得到一个巨型应用,实际上便是deis出品的workflow开源paas平台,具体这个平台的介绍下次有机会再分享
整个大型应用是通过 wofkflow/requirements.yaml组织起来的,所有依赖的chart放到charts目录,然后charts目录里就是些类似myapp的小应用
更复杂的应用,甚至有人把openstack用helm安装到Kubernetes上,感兴趣的可以参考这里
4.2.5 - k8s的监控方案
方案选型
如果已存在完善的监控系统的话,推荐使用k8s原生的heapster,比较轻量,容易集成。
我选择的是prometheus, 它是比较完善的云平台级监控方案,继k8s之后同样已被列入云计算基金会项目, 除了具备heapster的能力之外,还支持监控广泛的应用(mysql, JMX, HAProxy等)和灵活的告警的能力,并具备多IDC federation的能力,兼容多种开源监控系统(StatsD, Ganglia, collectd, nagios等)。
本文主要参考
下面分别介绍下两种方案
heapster
-
heapster的介绍:
通过向kubelet拉取stats的方式, 可提供15分钟内的缓存供k8s的dashboard用,也支持第三方存储,如influxdb等,还具备REST API(经我实验,这个API还不完善 缺少diskIO API).
-
heapster的监控范围
可监控的内容包括集群内的Container, Pod, Node 和 Namespace的性能或配置信息, 目前container级别还不支持网络和硬盘信息,具体性能项如下
| Metric Name | Description |
|---|---|
| cpu/limit | CPU hard limit in millicores. |
| cpu/node_capacity | Cpu capacity of a node. |
| cpu/node_allocatable | Cpu allocatable of a node. |
| cpu/node_reservation | Share of cpu that is reserved on the node allocatable. |
| cpu/node_utilization | CPU utilization as a share of node allocatable. |
| cpu/request | CPU request (the guaranteed amount of resources) in millicores. |
| cpu/usage | Cumulative CPU usage on all cores. |
| cpu/usage_rate | CPU usage on all cores in millicores. |
| filesystem/usage | Total number of bytes consumed on a filesystem. |
| filesystem/limit | The total size of filesystem in bytes. |
| filesystem/available | The number of available bytes remaining in a the filesystem |
| memory/limit | Memory hard limit in bytes. |
| memory/major_page_faults | Number of major page faults. |
| memory/major_page_faults_rate | Number of major page faults per second. |
| memory/node_capacity | Memory capacity of a node. |
| memory/node_allocatable | Memory allocatable of a node. |
| memory/node_reservation | Share of memory that is reserved on the node allocatable. |
| memory/node_utilization | Memory utilization as a share of memory allocatable. |
| memory/page_faults | Number of page faults. |
| memory/page_faults_rate | Number of page faults per second. |
| memory/request | Memory request (the guaranteed amount of resources) in bytes. |
| memory/usage | Total memory usage. |
| memory/working_set | Total working set usage. Working set is the memory being used and not easily dropped by the kernel. |
| network/rx | Cumulative number of bytes received over the network. |
| network/rx_errors | Cumulative number of errors while receiving over the network. |
| network/rx_errors_rate | Number of errors while receiving over the network per second. |
| network/rx_rate | Number of bytes received over the network per second. |
| network/tx | Cumulative number of bytes sent over the network |
| network/tx_errors | Cumulative number of errors while sending over the network |
| network/tx_errors_rate | Number of errors while sending over the network |
| network/tx_rate | Number of bytes sent over the network per second. |
| uptime | Number of milliseconds since the container was started. |
Prometheus
Prometheus集成了数据采集,存储,异常告警多项功能,是一款一体化的完整方案。 它针对大规模的集群环境设计了拉取式的数据采集方式、多维度数据存储格式以及服务发现等创新功能。
功能特点:
* 多维数据模型(有metric名称和键值对确定的时间序列)
* 灵活的查询语言
* 不依赖分布式存储
* 通过pull方式采集时间序列,通过http协议传输
* 支持通过中介网关的push时间序列的方式
* 监控数据通过服务或者静态配置来发现
* 支持多维度可视化分析和dashboard等
组件介绍:
这个生态里包含的组件,大多是可选的: * 核心prometheus server提供收集和存储时间序列数据 * 大量的client libraries来支持应用业务代码的探针 * 适用于短时任务的push gateway * 基于Rails/SQL语句的可视化分析 * 特殊用途的exporter(包括HAProxy、StatsD、Ganglia等) * 用于报警的alertmanager * 支持命令行查询的工具 * 其他工具 大多数的组件都是用Go语言来完成的,使得它们方便构建和部署。
架构图:
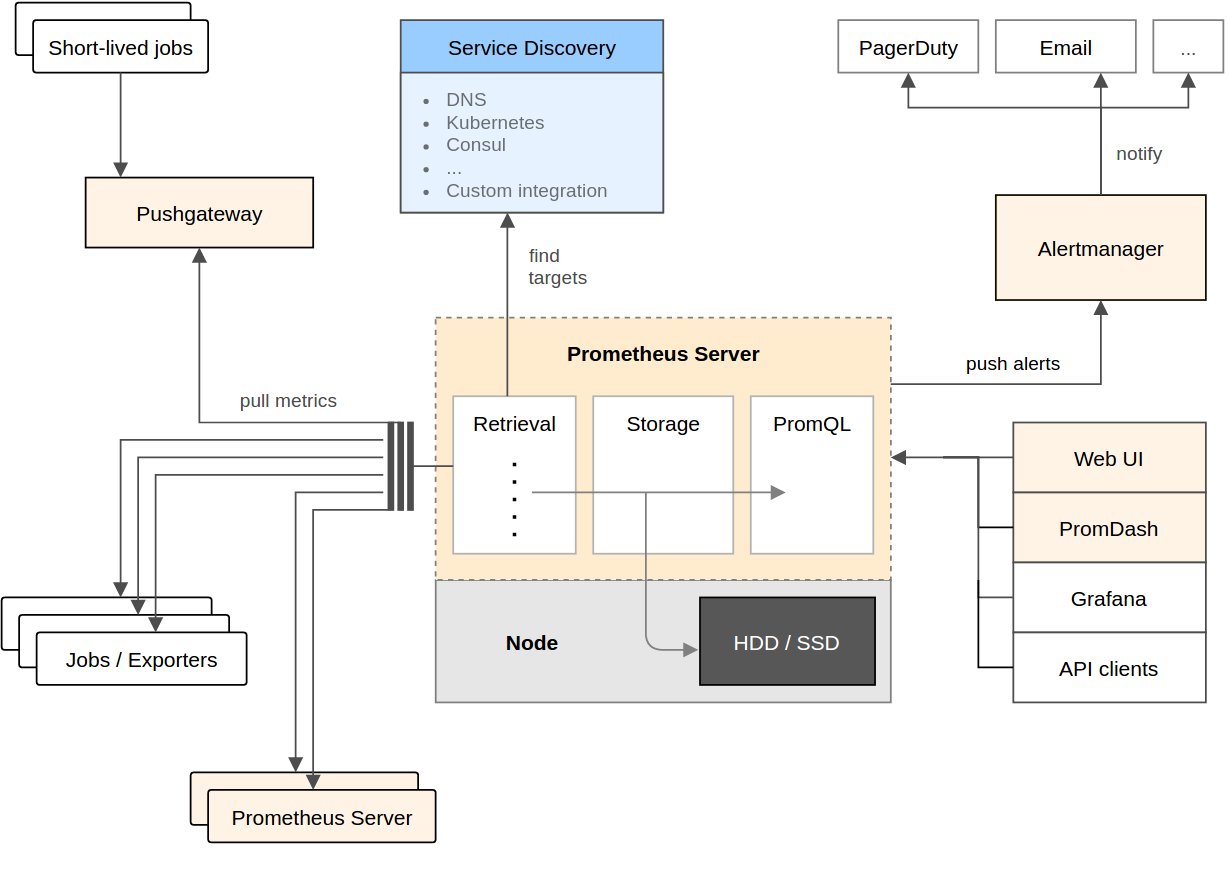
Promethues直接或通过短期Jobs的中介网关拉取收集指标。 它在本地存储所有抓取的数据样本,并对数据进行规则匹配检测,这样可以基于现有数据创建新的时间系列指标或生成警报。 PromDash或其他API使用者对收集的数据进行可视化。
引入Prometheus对k8s的影响
下图是Redhat研发人员的回答
并不会对k8s产生太大的影响,其主要是通过api-server来发现需要监控的目标,然后会周期性的通过各个Node上kubelet来拉取数据。 更详细的讨论见这里
部署Prometheus
下文是基于k8s-monitor项目来说的
Prometheus is an open-source monitoring solution that includes the gathering of metrics, their storage in an internal time series database as well as querying and alerting based on that data.
It offers a lot of integrations incl. Docker, Kubernetes, etc.
Prometheus can also visualize your data. However, in this recipe we include another open-source tool, Grafana, for the visualization part, as it offers a more powerful and flexible way to generate visuals and dashboards.
If you just want to get Prometheus and Grafana up and running you can deploy the whole recipe with a single command instead of going through all steps detailed out below:
kubectl create --filename manifests/
Deploying Prometheus
First, we need to create the configuration for our Prometheus. For this we use a Config Map, which we later mount into our Prometheus pod to configure it. This way we can change the configuration without having to redeploy Prometheus itself.
kubectl create --filename manifests/prometheus-core-configmap.yaml
Then, we create a service to be able to access Prometheus.
kubectl create --filename manifests/prometheus-core-service.yaml
Finally, we can deploy Prometheus itself.
kubectl create --filename manifests/prometheus-core-deployment.yaml
Further, we need the Prometheus Node Exporter deployed to each node. For this we use a Daemon Set and a fronting service for Prometheus to be able to access the node exporters.
kubectl create --filename manifests/prometheus-node-exporter-service.yaml
kubectl create --filename manifests/prometheus-node-exporter-daemonset.yaml
Wait a bit for all the pods to come up. Then Prometheus should be ready and running. We can check the Prometheus targets at https://mycluster.k8s.gigantic.io/api/v1/proxy/namespaces/default/services/prometheus/targets
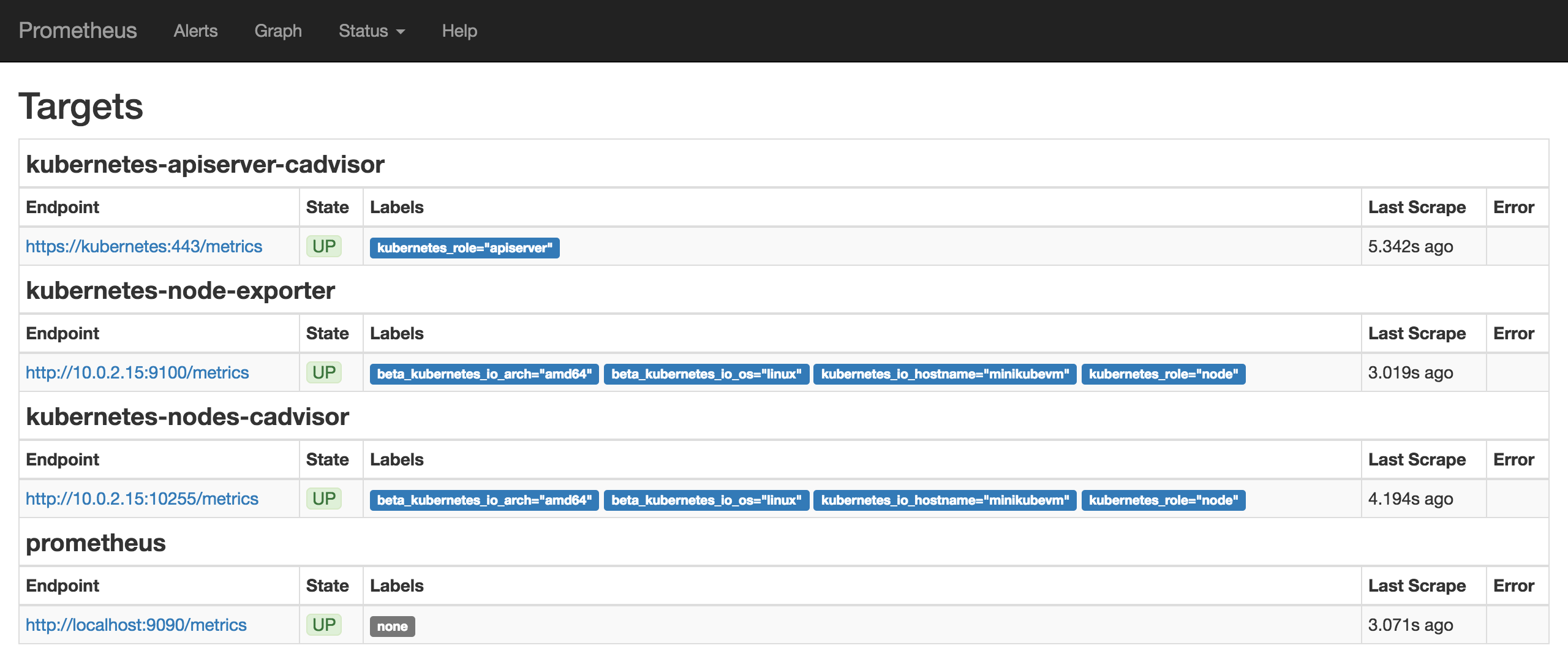
Deploying Alertmanager
we need to create the configuration for our Alertmanager. For this we use a Config Map, which we later mount into our Alertmanager pod to configure it. This way we can change the configuration without having to redeploy Alertmanager itself.
kubectl create --filename manifests/prometheus-alert-configmap.yaml
Then, we create a service to be able to access Alertmanager.
kubectl create --filename manifests/prometheus-alert-service.yaml
Finally, we can deploy Alertmanager itself.
kubectl create --filename manifests/prometheus-alert-deployment.yaml
Wait a bit for all the pods to come up. Then Alertmanager should be ready and running. We can check the Alertmanager targets at https://mycluster.k8s.gigantic.io/api/v1/proxy/namespaces/default/services/alertmanager/
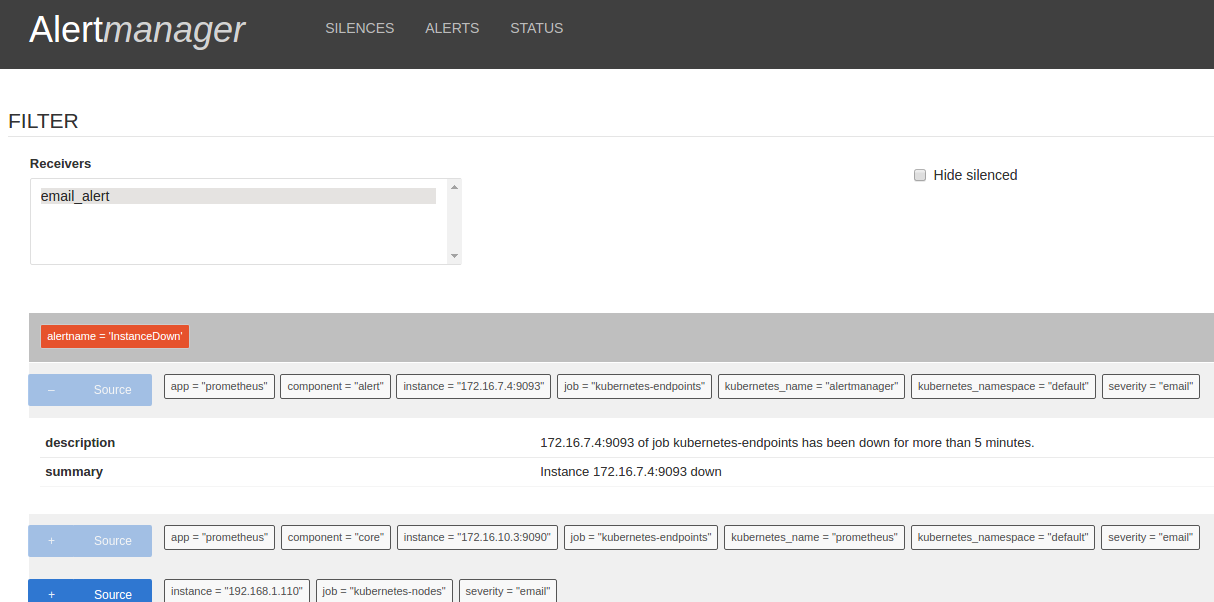
Deploying Grafana
Now that we have Prometheus up and running we can deploy Grafana to have a nicer frontend for our metrics.
Again, we create a service to be able to access Grafana and a deployment to manage the pods.
kubectl create --filename manifests/grafana-services.yaml
kubectl create --filename manifests/grafana-deployment.yaml
Wait a bit for Grafana to come up. Then you can access Grafana at https://mycluster.k8s.gigantic.io/api/v1/proxy/namespaces/default/services/grafana/
Setting Up Grafana
TLDR: If you don't want to go through all the manual steps below you can let the following job use the API to configure Grafana to a similar state.
kubectl create --filename manifests/grafana-import-dashboards-job.yaml
Once we're in Grafana we need to first configure Prometheus as a data source.
Grafana UI / Data Sources / Add data sourceName:prometheusType:PrometheusUrl:http://prometheus:9090Add
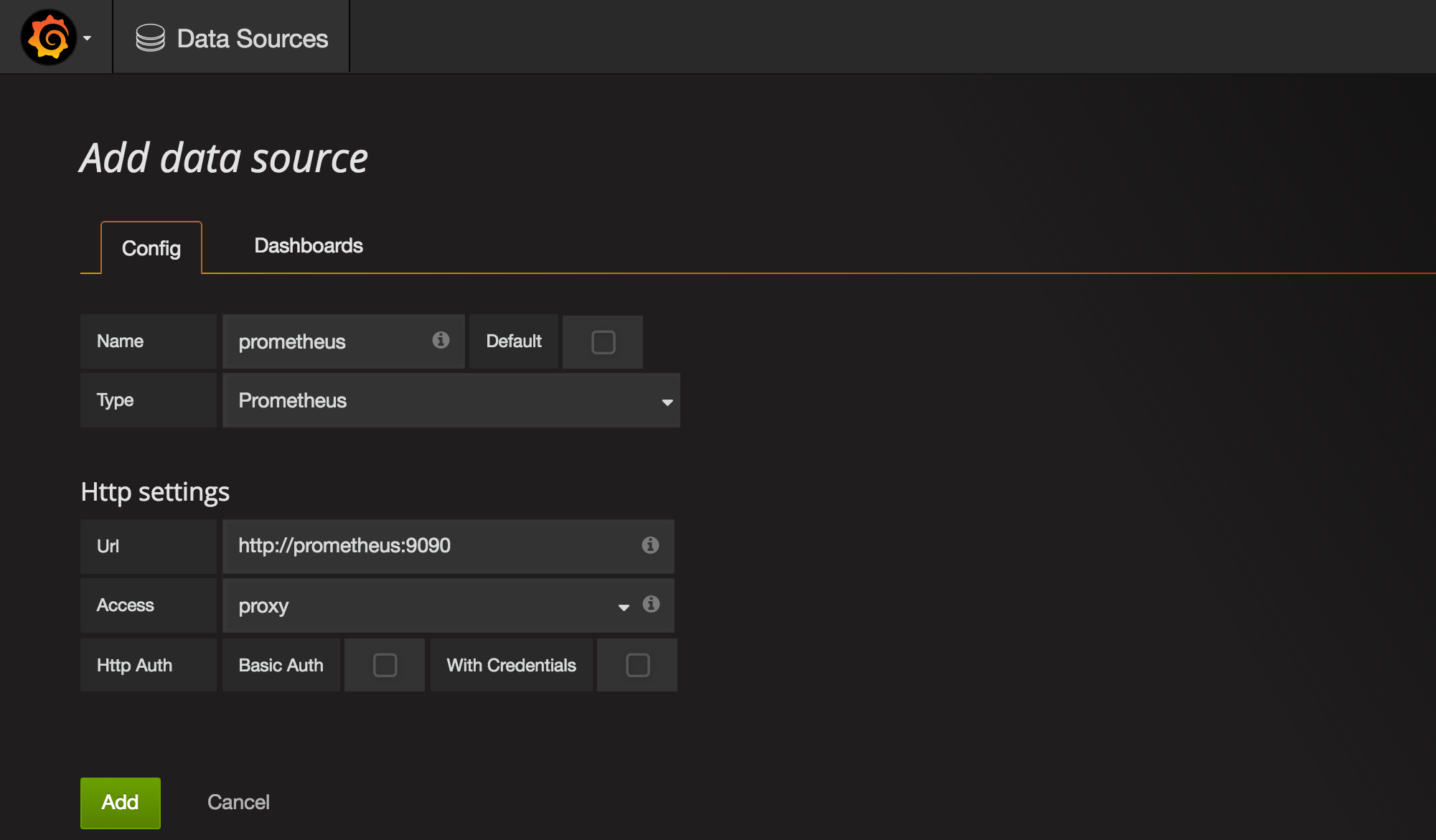
Then go to the Dashboards tab and import the Prometheus Stats dashboard, which shows the status of Prometheus itself.
You can check it out to see how your Prometheus is doing.
Last, but not least we can import a sample Kubernetes cluster monitoring dashboard, to get a first overview over our cluster metrics.
Grafana UI / Dashboards / ImportGrafana.net Dashboard:https://grafana.net/dashboards/597LoadPrometheus:prometheusSave & Open
Voilá. You have a nice first dashboard with metrics of your Kubernetes cluster.
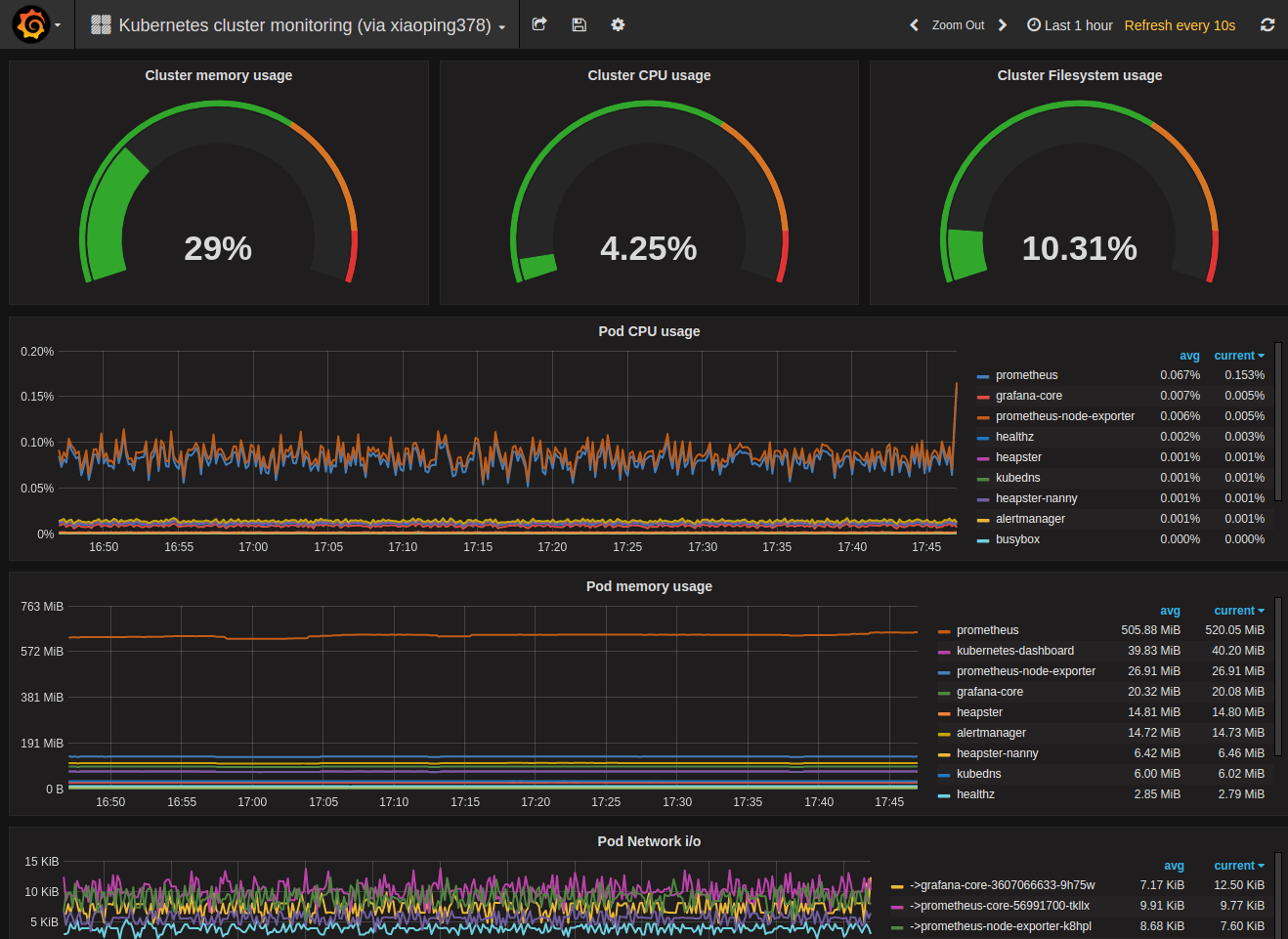
Next Steps
Next, you should get into the Grafana and Prometheus documentations to get to know the tools and either build your own dashboards or extend the samples from above.
You can also check out grafana.net for some more example dashboards and plugins.
More Alertmanager documentations in here
4.2.6 - 配置harbor默认https访问
因为使用自签证书(reg.300.cn),所以需要把中间过程生成的ca.crt拷贝到需要pull/push的node上 (懒的翻译了,很详细的文档,已验证OK)
Because Harbor does not ship with any certificates, it uses HTTP by default to serve registry requests. This makes it relatively simple to configure. However, it is highly recommended that security be enabled for any production environment. Harbor has an Nginx instance as a reverse proxy for all services, you can configure Nginx to enable https.
##Getting a certificate
Assuming that your registry's hostname is reg.yourdomain.com, and that its DNS record points to the host where you are running Harbor. You first should get a certificate from a CA. The certificate usually contains a .crt file and a .key file, for example, yourdomain.com.crt and yourdomain.com.key.
In a test or development environment, you may choose to use a self-signed certificate instead of the one from a CA. The below commands generate your own certificate:
- Create your own CA certificate:
openssl req \
-newkey rsa:4096 -nodes -sha256 -keyout ca.key \
-x509 -days 365 -out ca.crt
- Generate a Certificate Signing Request:
If you use FQDN like reg.yourdomain.com to connect your registry host, then you must use reg.yourdomain.com as CN (Common Name). Otherwise, if you use IP address to connect your registry host, CN can be anything like your name and so on:
openssl req \
-newkey rsa:4096 -nodes -sha256 -keyout yourdomain.com.key \
-out yourdomain.com.csr
- Generate the certificate of your registry host:
On Ubuntu, the config file of openssl locates at /etc/ssl/openssl.cnf. Refer to openssl document for more information. The default CA directory of openssl is called demoCA. Let's create necessary directories and files:
mkdir demoCA
cd demoCA
touch index.txt
echo '01' > serial
cd ..
If you're using FQDN like reg.yourdomain.com to connect your registry host, then run this command to generate the certificate of your registry host:
openssl ca -in yourdomain.com.csr -out yourdomain.com.crt -cert ca.crt -keyfile ca.key -outdir .
If you're using IP to connect your registry host, you may instead run the command below:
echo subjectAltName = IP:your registry host IP > extfile.cnf
openssl ca -in yourdomain.com.csr -out yourdomain.com.crt -cert ca.crt -keyfile ca.key -extfile extfile.cnf -outdir .
##Configuration of Nginx After obtaining the yourdomain.com.crt and yourdomain.com.key files, change the directory to Deploy/config/nginx in Harbor project.
cd Deploy/config/nginx
Create a new directory cert/, if it does not exist. Then copy yourdomain.com.crt and yourdomain.com.key to cert/, e.g. :
cp yourdomain.com.crt cert/
cp yourdomain.com.key cert/
Rename the existing configuration file of Nginx:
mv nginx.conf nginx.conf.bak
Copy the template nginx.https.conf as the new configuration file:
cp nginx.https.conf nginx.conf
Edit the file nginx.conf and replace two occurrences of harbordomain.com to your own host name, such as reg.yourdomain.com . If you use a customized port rather than the default port 443, replace the port "443" in the line "rewrite ^/(.*) https://$server_name:443/$1 permanent;" as well. Please refer to the installation guide for other required steps of port customization.
server {
listen 443 ssl;
server_name harbordomain.com;
...
server {
listen 80;
server_name harbordomain.com;
rewrite ^/(.*) https://$server_name:443/$1 permanent;
Then look for the SSL section to make sure the files of your certificates match the names in the config file. Do not change the path of the files.
...
# SSL
ssl_certificate /etc/nginx/cert/yourdomain.com.crt;
ssl_certificate_key /etc/nginx/cert/yourdomain.com.key;
Save your changes in nginx.conf.
##Installation of Harbor Next, edit the file Deploy/harbor.cfg , update the hostname and the protocol:
#set hostname
hostname = reg.yourdomain.com
#set ui_url_protocol
ui_url_protocol = https
Generate configuration files for Harbor:
./prepare
If Harbor is already running, stop and remove the existing instance. Your image data remain in the file system
docker-compose stop
docker-compose rm
Finally, restart Harbor:
docker-compose up -d
After setting up HTTPS for Harbor, you can verify it by the following steps:
-
Open a browser and enter the address: https://reg.yourdomain.com . It should display the user interface of Harbor.
-
On a machine with Docker daemon, make sure the option "-insecure-registry" does not present, and you must copy ca.crt generated in the above step to /etc/docker/certs.d/yourdomain.com(or your registry host IP), if the directory does not exist, create it. If you mapped nginx port 443 to another port, then you should instead create the directory /etc/docker/certs.d/yourdomain.com:port(or your registry host IP:port). Then run any docker command to verify the setup, e.g.
docker login reg.yourdomain.com
If you've mapped nginx 443 port to another, you need to add the port to login, like below:
docker login reg.yourdomain.com:port
##Troubleshooting
-
You may get an intermediate certificate from a certificate issuer. In this case, you should merge the intermediate certificate with your own certificate to create a certificate bundle. You can achieve this by the below command:
cat intermediate-certificate.pem >> yourdomain.com.crt -
On some systems where docker daemon runs, you may need to trust the certificate at OS level. On Ubuntu, this can be done by below commands:
cp youdomain.com.crt /usr/local/share/ca-certificates/reg.yourdomain.com.crt update-ca-certificatesOn Red Hat (CentOS etc), the commands are:
cp yourdomain.com.crt /etc/pki/ca-trust/source/anchors/reg.yourdomain.com.crt update-ca-trust
4.2.7 - k3s实践-01
本文主要介绍k3s的安装和核心组件解读。
k3s是all-in-one的轻量k8s发行版,把所有k8s组件打包成一个不到100M的二进制文件了。具备如下显著特点:
- 打包成单一二进制
- 默认集成了sqlite3来替代etcd,也可以指定其他数据库:etcd3、mysql、postgres。
- 默认内置Coredns、Metrics Server、Flannel、Traefik ingress、Local-path-provisioner等
- 默认启用了TLS加密通信。
安装
官方提供了一键安装脚本install.sh ,执行curl -sfL https://get.k3s.io | sh -可一键安装server端。此命令会从https://update.k3s.io/v1-release/channels/stable取到最新的稳定版安装,可以通过INSTALL_K3S_VERSION环境变量指定版本,本文将以1.19为例。
启动 k3s server端(master节点).
curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION=v1.19.16+k3s1 sh -
由于网络原因,可能会失败,自行想办法下载下来,放置
/usr/local/bin/k3s,附上执行权限chmod a+x /usr/local/bin/k3s, 然后上面的命令加上INSTALL_K3S_SKIP_DOWNLOAD=true再执行一遍即可。
安装里log里会输出一些重要信息:
kubectl、crictl、卸载脚本、systemd service
不出意外,k3s server会被systemd启动,执行命令查看systemctl status k3s或者通过软链的kubectl验证是否启动成功:
➜ kubectl get no
NAME STATUS ROLES AGE VERSION
gitlab-server Ready master 6m43s v1.19.16+k3s1
(Optional) 启动 k3s agent端 (添加worker节点).
curl -sfL https://get.k3s.io | K3S_URL=https://172.25.11.130:6443 K3S_TOKEN=bulabula INSTALL_K3S_VERSION=v1.19.16+k3s1 sh -
K3S_TOKEN内容需要从server端的/var/lib/rancher/k3s/server/node-token文件取出K3S_URL中的IP是master节点的IP。
集群访问
默认kubectl通过localhost访问本地集群,所以上文敲kubectl是没问题的,如果要被外部访问或者纳管的话,可以把kubeconfig文件拷走,默认路径是 /etc/rancher/k3s/k3s.yaml
。记得修改文件内的server字段,改成外部可访问到的IP。
架构说明
TODO.
4.2.8 - k8s controllers工程化实践
controllers工程化
工程化的目标
controller工程化的定义,建立一个可持续迭代的工程,包括但不限于以下目标。
- 支持多group资源(多个controller)
- 更改CR字段后,可无缝升级(重新生产CR和API)
- API文档化
- CR部署初始化
- ARM多架构编译和镜像构建
- 单元测试覆盖率,golang-ci代码扫描。
- 暴露关键的监控指标和事件日志
- 高可用
- 关注规模性能
- 安全问题
- webhook证书,统一管理
- 组件Token权限
- CR幂等性
创建一个Operator
利用kubebuilder初始化一个Operator,背后依赖controller-runtime和controller-gen
mkdir -p ~/app && cd ~/app
kubebuilder init --domain cebpaas.io --repo cebpaas.io/appmanager
# Writing kustomize manifests for you to edit...
# Writing scaffold for you to edit...
# Get controller runtime:
# $ go get sigs.k8s.io/controller-runtime@v0.11.2
# Update dependencies:
# $ go mod tidy
# Next: define a resource with:
# $ kubebuilder create api
#可选命令, 本处执行的话,可省略下文的“多个controller合并”
#kubebuilder edit --multigroup=true
kubebuilder create api --group apps --version v1 --kind Application
# Create Resource [y/n]
# y
# Create Controller [y/n]
# y
# Writing kustomize manifests for you to edit...
# Writing scaffold for you to edit...
# api/v1/application_types.go
# controllers/application_controller.go
# Update dependencies:
# $ go mod tidy
# Running make:
# $ make generate
# mkdir -p /root/app/bin
# GOBIN=/root/app/bin go install sigs.k8s.io/controller-tools/cmd/controller-gen@v0.8.0
# /root/app/bin/controller-gen object:headerFile="hack/boilerplate.go.txt" paths="./..."
# Next: implement your new API and generate the manifests (e.g. CRDs,CRs) with:
# $ make manifests
make manifests
# /root/app/bin/controller-gen rbac:roleName=manager-role crd webhook paths="./..." output:crd:artifacts:config=config/crd/bases
多个group controller合并
开启多controller操作,
# 开启多controller
kubebuilder edit --multigroup=true
# 手动修复之前默认创建的单仓,apps是之前示例中创建的group
mkdir apis/apps
mv api/* apis/apps
# After ensuring that all was moved successfully remove the old directory `api/`
rm -rf api/
mkdir controllers/apps
mv controllers/* controllers/apps/
# 修改之前go文件的import错误和package名称(controllers->apps)
# 修改`controllers/<group>/suite_test.go`文件中的CRDDirectoryPaths路径错误
# CRDDirectoryPaths: []string{filepath.Join("..", "..", "config", "crd", "bases")},
如上修改完毕,就可以添加新的group资源了.
kubebuilder create api --group cronhpacontroller --version v1 --kind Cronhpa
最终的目录结构
tree -L 2
.
├── apis
│ ├── apps # 同group多个kind资源,会默认生成在此目录
│ └── cronhpacontroller # 此处为新添加的group
├── bin
│ └── controller-gen
├── config
│ ├── crd
│ ├── default
│ ├── manager
│ ├── prometheus
│ ├── rbac
│ └── samples
├── controllers
│ ├── apps
│ └── cronhpacontroller
├── Dockerfile
├── go.mod
├── go.sum
├── hack
│ └── boilerplate.go.txt
├── main.go
├── Makefile
├── PROJECT
└── README.md
小计
-
controller-runtime架构

-
controller-gen, 根据go文件里的标记注释,按规则自动生成DeepCopy代码、CR manifest、Webhook、Role等对象。
bin/controller-gen -hh查看命令可用参数,内置5类生成器。bin/controller-gen crd -ww查看各类生成器支持的标记注释。
-
code-generator
- KCP使用了该工具,该工具集成在k8s主仓库中,内置多种生成器(deepcopy、informers、listers、clientsets、openapi等),相对更底层,需要自己封装实现controller-runtime的功能,官方给出了可参考的示例
sample-controller。 - ClientSet提供了如k8s内置资源的便捷操作方法,可避免使用DynamicClient去操作非结构化数据结构。
- client-go支持RESTClient、ClientSet、DynamicClient、DiscoveryClient四种客户端。
- KCP使用了该工具,该工具集成在k8s主仓库中,内置多种生成器(deepcopy、informers、listers、clientsets、openapi等),相对更底层,需要自己封装实现controller-runtime的功能,官方给出了可参考的示例
-
Operator开发有多种方案
Kubebuilder(controller-runtime + controller-gen)Code-generator+ sample-controllerOperator SDK基于kubebuidler扩展了更多的企业级功能,如OLM、OperatorHub和其他技术栈(ansible、helm)的Operator能力。- 其他
-
目前ACP中,前两种都用到了,推测主要原因是kubebuilder v2版本不支持mutli-group特性。
-
kubebuilder自动创建api时,可以选择是否生产controller,如果只选择生成resource,相当于只创建CR注册和安装初始化的内容(生成apis目录下的 _types.go和deepcopy代码)。
4.2.9 - DEIS 开源PAAS平台实践
DEIS(目前已被微软收购)的workflow是开源的Paas平台,基于kubernetes做了一层面向开发者的CLI和接口,做到了让开发者对容器无感知的情况下快速的开发和部署线上应用。
workflow是 on top of k8s的,所有组件默认全是跑在pod里的,不像openshift那样对k8s的侵入性很大。
特性如下:
- S2I(自动识别源码直接编译成镜像)
- 日志聚合
- 应用管理(发布,回滚)
- 认证&授权机制
- 边界路由
下面从环境搭建,安装workflow及其基本使用做个梳理。
初始化k8s集群
可以通过k8s-deploy项目来离线安装高可用kubernetes集群,我这里是单机演示环境。
kubeadm init --kubernetes-version v1.6.2 --pod-network-cidr 12.240.0.0/12
#方便命令自动补全
source <(kubectl completion zsh)
#安装cni网络
cp /etc/kubernetes/admin.conf $HOME/.kube/config
kubectl apply -f kube-flannel-rbac.yml
kubectl apply -f kube-flannel.yml
#使能master可以被调度
kubectl taint node --all node-role.kubernetes.io/master-
#安装ingress-controller, 边界路由作用
kubectl create -f ingress-traefik-rbac.yml
kubectl create -f ingress-traefik-deploy.yml
初始化helm
helm相当于kubernetes里的包管理器,类似yum和apt的作用,只不过它操作的是charts(各种k8s yaml文件的集合,额外还有Chart.yaml -- 包的描述文件)可以理解为基于k8s的应用模板管理类工具, 后面会用它来安装workflow到上面跑起来的k8s集群里。
从k8s 1.6之后,kubeadm安装的集群,默认会开启RBAC机制,为了让helm可以安装任何应用,我们这里赋予tiller cluster-admin权限
kubectl create serviceaccount helm --namespace kube-system
kubectl create clusterrolebinding cluster-admin-helm --clusterrole=cluster-admin --serviceaccount=kube-system:helm
初始化helm:
➜ helm init --service-account helm
$HELM_HOME has been configured at /home/xxp/.helm.
Tiller (the helm server side component) has been installed into your Kubernetes Cluster.
Happy Helming!
➜ helm version
Client: &version.Version{SemVer:"v2.4.1", GitCommit:"46d9ea82e2c925186e1fc620a8320ce1314cbb02", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.4.1", GitCommit:"46d9ea82e2c925186e1fc620a8320ce1314cbb02", GitTreeState:"clean"}
安装后,默认导入了2个repos,后面安装和搜索应用时,都是从这2个仓里出的,当然也可以自己通过helm repo add添加本地私有仓
➜ helm repo list
NAME URL
stable https://kubernetes-charts.storage.googleapis.com
local http://127.0.0.1:8879/charts
helm的使用基本流程如下:
- helm search: 搜索自己想要安装的应用(chart)
- helm fetch: 下载应用(chart)到本地,可以忽略此步
- helm install: 安装应用
- helm list: 查看已安装的应用情况
安装workflow
添加workflow的repo仓
helm repo add deis https://charts.deis.com/workflow
开始安装workflow,因为RBAC的原因,同样要赋予workflow各组件相应的权限,yml文件在[这里](https://gist.github.com/xiaoping378/798c39e0b607be4130db655f4873bd24)
kubectl apply -f workflow-rbac.yml --namespace deis
helm install deis/workflow --name workflow --namespace deis \
--set global.experimental_native_ingress=true,controller.platform_domain=192.168.31.49.xip.io
其中会拉取所需镜像,不出意外会有如下结果:
➜ kubectl --namespace=deis get pods
NAME READY STATUS RESTARTS AGE
deis-builder-1134410811-11xpp 1/1 Running 0 46m
deis-controller-2000207379-5wr10 1/1 Running 1 46m
deis-database-244447703-v2sh9 1/1 Running 0 46m
deis-logger-2533678197-pzmbs 1/1 Running 2 46m
deis-logger-fluentd-08hms 1/1 Running 0 42m
deis-logger-redis-1307646428-fz1kk 1/1 Running 0 46m
deis-minio-3195500219-tv7wz 1/1 Running 0 46m
deis-monitor-grafana-59098797-mdqh1 1/1 Running 0 46m
deis-monitor-influxdb-168332144-24ngs 1/1 Running 0 46m
deis-monitor-telegraf-vgbr9 1/1 Running 0 41m
deis-nsqd-1042535208-40fkm 1/1 Running 0 46m
deis-registry-2249489191-2jz3p 1/1 Running 2 46m
deis-registry-proxy-qsqc2 1/1 Running 0 46m
deis-router-3258454730-3rfpq 1/1 Running 0 41m
deis-workflow-manager-3582051402-m11zn 1/1 Running 0 46m
注册管理用户
由于我们是本地ingress-controller, 必须保障deis-builder.$host可以被解析, 自行创建ingress of deis-builder.
kubectl apply -f deis-buidler-ingress.yml
确保traefik有如下状态:
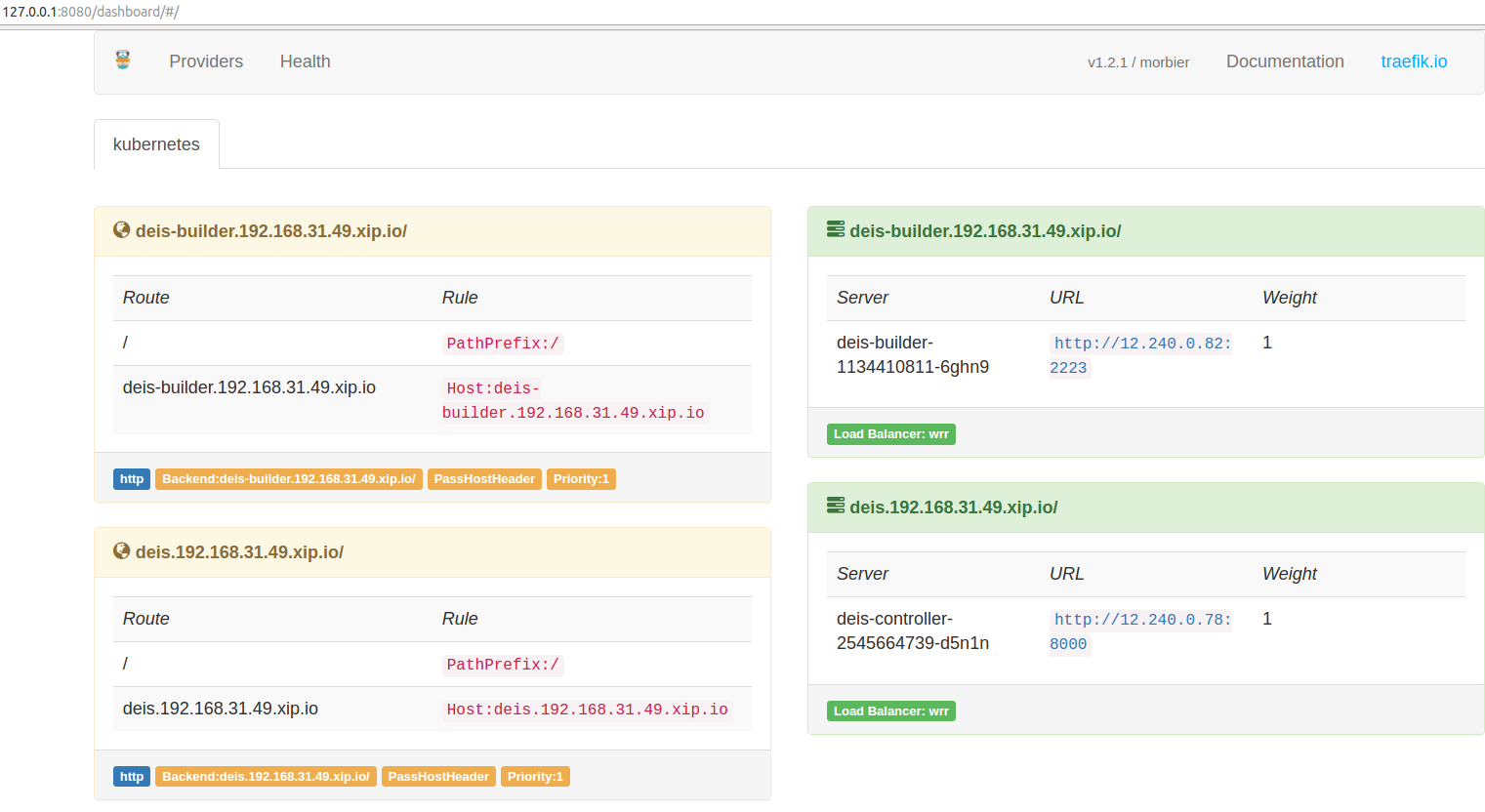
如下操作注册,默认第一个用户为管理员用户,可操作所有其他用户。
➜ ~ kubectl get --namespace deis ingress
NAME HOSTS ADDRESS PORTS AGE
builder-api-server-ingress-http deis-builder.192.168.31.49.xip.io 80 18m
controller-api-server-ingress-http deis.192.168.31.49.xip.io 80 1h
➜ ~
➜ ~ deis register deis.192.168.31.49.xip.io
username: admin
password:
password (confirm):
email: xiaoping378@163.com
Registered admin
Logged in as admin
Configuration file written to /home/xxp/.deis/client.json
➜ ~
➜ ~ deis whoami
You are admin at http://deis.192.168.31.49.xip.io
部署第一个应用
4.2.10 - kubeshere 自研-01
kubesphere 自研环境篇
心态
首先调整心态,这是一个新的生态,秉承学习的心态。
准备环境
- clone代码
git clone https://github.com/kubesphere/kubesphere.git
- 准备开发环境
4.2.11 - TKEStack all-in-one入坑指南
本文主要介绍当前最新版本TkeStack 1.8.1 的TKEStack的all-in-one安装、多租户和多集群管理功能解读。
安装实录
官方推荐至少需要2节点方可安装,配置如下,硬盘空间一定要保障。也支持ALL-in-ONE的方式安装,但有BUG。
启动init服务
启动init服务,即安装tke-installer和registry服务,安装命令行如下:
arch=amd64 version=v1.8.1 \
&& wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} \
&& sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 \
&& chmod +x tke-installer-linux-$arch-$version.run \
&& ./tke-installer-linux-$arch-$version.run
如上命令执行后,会下载8G左右的安装包,并执行解压后的install.sh脚本,启动3个容器:1个为tke-installer和另2个为registry仓,且为containerd容器,需要使用nerdctl [images | ps]等命令查看相关信息。
通过查看脚本,上文启动的本地registry的启动命令等效如下:
nerdctl run --name registry-https -d --net=host --restart=always -p 443:443 \
-v /opt/tke-installer/registry:/var/lib/registry \
-v registry-certs:/certs \
-e REGISTRY_HTTP_ADDR=0.0.0.0:443 \
-e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/server.crt \
-e REGISTRY_HTTP_TLS_KEY=/certs/server.key \
tkestack/registry-amd64:2.7.1
还有个http 80的registry,这里不贴了,后面的部分坑,就是这里埋下的,预先占用了节点的80和443端口,后面tke的gateway pod会启动失败。
启动TKE集群
上章节执行完后,会启动tke-installer(一个web操作台),通过访问本地8080端口,可访问界面操作安装global集群。按照官方指引操作就行,此处不表。另外需要说明的是在安装过程中,如果要查看本地容器,不能使用docker ps了,需要使用nerdctl -n k8s.io ps。整个安装过程是使用ansible和kubeadm完成的,kubelet是通过systemd启动的,k8s组件为静态pod。
因为我是使用的ALL-in-ONE安装,遇到了不少问题,可详见FAQ如何解决。安装成功后会提示如下指引:
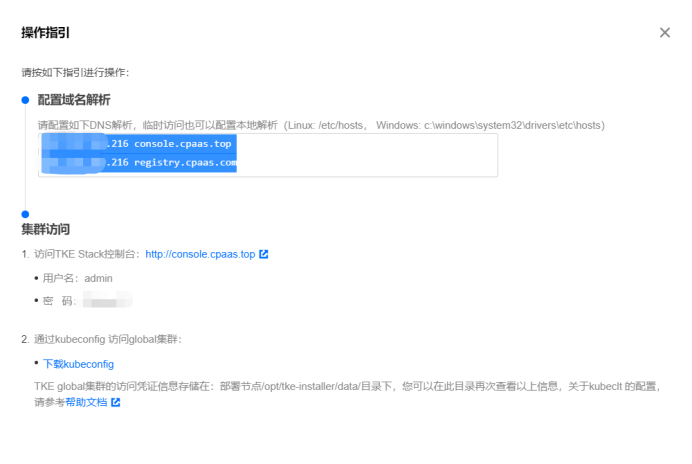
默认初始安装后,很多pod是双副本的,我这里仅是验证功能使用,全部改成了单副本。
多租户管理
tkestack采用Casbin框架实现的权限管理功能,默认集成的Model,查看源码得知:
[request_definition]
r = sub, dom, obj, act
[policy_definition]
p = sub, dom, obj, act, eft
[role_definition]
g = _, _, _
[policy_effect]
e = some(where (p.eft == allow)) && !some(where (p.eft == deny))
[matchers]
m = g(r.sub, p.sub, r.dom) && keyMatchCustom(r.obj, p.obj) && keyMatchCustom(r.act, p.act)
实现了多租户级的RBAC权限模型。
FAQ
安装过程出现循环等待apiserver启动
2022-01-19 14:43:32.225 error tke-installer.ClusterProvider.OnCreate.EnsureKubeadmInitPhaseWaitControlPlane check healthz error {"statusCode": 0, "error": "Get \"https://****:6443/healthz?timeout=30s\": net/http: TLS handshake timeout"}
我这里是因为在installer上指定的master的IP为外网IP(我使用外网IP是有原因的,穷... 后面需要跨云厂商组集群),通过查看kubelet日志提示本机找不到IP,如下开启网卡多IP,可通过。
ip addr add 118.*.*.* dev eth0
Gateway POD启动失败
我这里是因为init节点和gobal master节点,共用了一个,本registry服务占用了80和443端口,需要修改gateway hostNetwork为false,另外可以通过修改svc 为nodePort,还需要修改targetPort,官方现在这里有bug,不知道为指到944*的端口上,我这里设置的30080来访问安装好的集群。
页面登录错误Unregistered redirect_uri
官方没有相关说明,一切都是ALL-in-ONE的原因,我改动了默认集群console的访问端口为30080。。。 通过查看源码发现是每次认证时dex会校验tke-auth-api向它注册过的合法client地址。于是我就修改了tke命名空间下tke-auth-api的相关configmap:
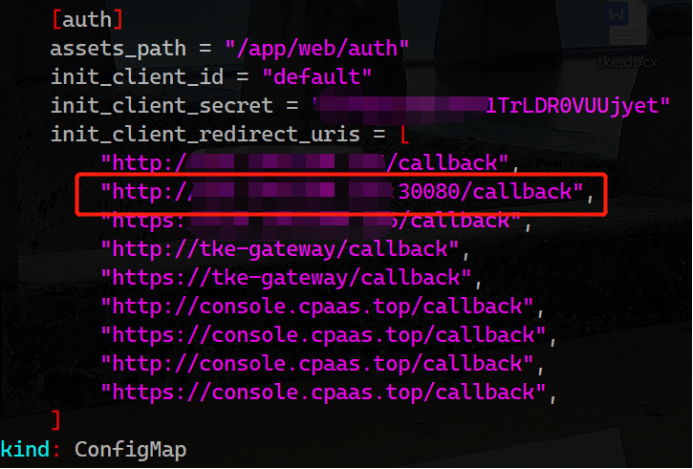
重启tke-auth-api后,问题依旧存在,继续源码走查,发现这玩意儿叫init真的只发挥一次作用,改完配置,不会重新读取,细读逻辑发现etcd中不存在这个key,会重新读取写入一次,于是决定删除etcd中的相关key。
etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/apiserver-etcd-client.crt --key=/etc/kubernetes/pki/apiserver-etcd-client.key del /tke/auth-api/client/default --prefix
添加节点的过程中failed,无法删除节点重试
ssh信息设置完后,如果中间出问题,会陷入无限重试...
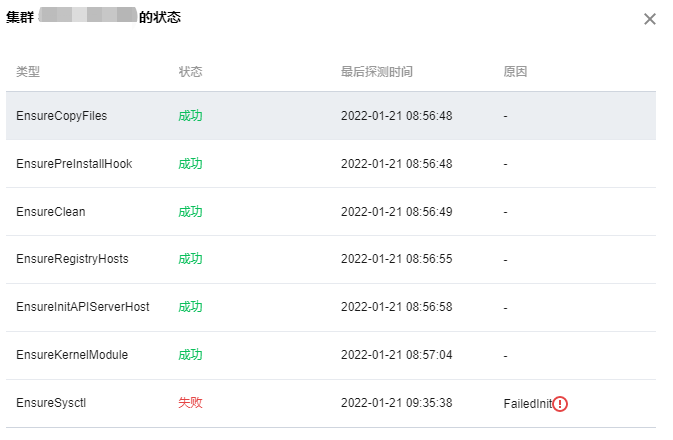
遇事不决,看日志,找不到日志,看源码...
通过翻找源码,发现是platform相关组件在负责,查看相关日志kubectl -n logs tke-platform-controller-*** --tail 100 -f,定位问题,我这里是以前各种安装的残留信息,导致添加节点初始化失败。删除之... 解决。
为避免添加节点no clean再次出现问题,建议预先执行下clean.sh脚本。
小技巧
如下使用,可以愉快的敲命令了,因为我是用oh-my-zsh的shell主题(没有自动加载kubectl plugin),kubectl的命令补全使用zsh,可根据实际情况调整。
source <(nerdctl completion bash)
source <(kubectl completion zsh)
4.3 - Openshift
主要记录介绍以前个人的Openshfit实践总结。
4.3.1 - 快速安装
不知道为什么openshift在国内热度这么低,那些要做自己容器云的公司,不知道有openshift项目的存在么?完全满足我的需求。
docker负责应用的隔离打包,k8s提供集群管理和容器的编排服务,而openshfit则负责整个应用的生命周期:
- 源码管理,CI&CD能力
- 多租户管理, 支持LDAP和Oauth
- 集成监控日志于web console
先说下自接触到openshift项目就遇到的一个困惑,就是openshift origin/enterprise /online/dedicated/ocp之间的关系: orgin相当于Fedora, 其他的相当于RHEL
接下来谈下我用自己的笔记本实践的过程与感受:
- 快速安装
本人日常基于ubuntu16.04办公,所以用oc直接上, oc相当于kubectl
这里直接下载oc客户端,或者自行编译, 编译结果在_output目录下
git clone --depth=1 https://github.com/openshift/origin.git
cd origin && make
mv _output/local/bin/linux/amd64/oc /usr/local/bin
启动openshift, 默认开启监控并初始安装自最新版本,当前是v1.5.0-alpha.2
oc cluster up --metrics=true --version=latest --insecure-skip-tls-verify=true --public-hostname=air13
过程中会拉取所需镜像, 我这里显示比较多,之前已经做了些实验
➜ ~ docker images | grep openshift | awk '{print $1}'
openshift/node
openshift/origin-sti-builder
openshift/origin-docker-builder
openshift/origin-deployer
openshift/origin-gitserver
openshift/origin-docker-registry
openshift/origin-haproxy-router
openshift/origin
openshift/hello-openshift
openshift/openvswitch
openshift/origin-pod
openshift/origin-metrics-cassandra
openshift/origin-metrics-hawkular-metrics
openshift/origin-metrics-heapster
openshift/origin-metrics-deployer
openshift/mysql-55-centos7
openshift/origin-logging-curator
openshift/origin-logging-fluentd
openshift/origin-logging-deployment
openshift/origin-logging-elasticsearch
openshift/origin-logging-kibana
openshift/origin-logging-auth-proxy
启动后,会打印如下信息
OpenShift server started.
The server is accessible via web console at:
https://air13:8443
The metrics service is available at:
https://metrics-openshift-infra.192.168.31.49.xip.io
You are logged in as:
User: developer
Password: developer
To login as administrator:
oc login -u system:admin
打开浏览器,访问https://air13:8443,默认用developer登录,其实现在任意用户任意密码都可以的。
web console里是空空如野的,可以临时授权developer用户操作所有项目
oc adm policy add-cluster-role-to-user cluster-admin developer
2.技巧总结
- 命令行自动补全, 其实kubectl也可以如此
source <(oc completion bash)
-
默认监控占用的资源太大了,可以如下降低资源占用,当然也可以web操作限制资源利用率
oc env rc hawkular-cassandra-1 MAX_HEAP_SIZE=1024M -n openshift-infra #重建下变量才会生效 oc scale rc hawkular-cassandra-1 --replicas 0 -n openshift-infra oc scale rc hawkular-cassandra-1 --replicas 1 -n openshift-infra因为是rc,所以直接杀掉没关系,要不env不生效
-
自己编译离线文档
# 下载源文件 git clone --depth=1 https://github.com/openshift/openshift-docs.git # 编译 cd openshift-docs && asciibinder build # 结果会存放在 _preview下, cd _preview && python -m SimpleHTTPServer #打开浏览器访问127.0.0.1:8000推荐此人blog,有几篇干货
3.后面会重点说下权限/资源管理和整个app开发的流程
4.3.2 - 权限资源管理
重点介绍 project,limitRange,resourceQuta和 user, group, rule,role,policy,policybinding的关系, 我刚接触时,这几个概念老搞不太清楚,这里梳理下
资源管理说明
可以对计算资源的大小和对象类型的数量来进行配额限制。
ResourceQuota是面向project(namespace的基础上加了些注解)层面的,只有集群管理员可以基于namespace设置。
limtRange是面向pod和container级别的,openshift额外还可以限制 image, imageStream和pvc,
也是只有集群管理员才可以基于project设置,而开发人员只能基于pod(container)设置cpu和内存的requests/limits。
ResourceQuota
看看具体可以管理哪些资源,期待网络相关的也加进来.简单来讲,可以基于project来限制可消耗的内存大小和可创建的pods数量
// The following identify resource constants for Kubernetes object types
const (
// Pods, number
ResourcePods ResourceName = "pods"
// Services, number
ResourceServices ResourceName = "services"
// ReplicationControllers, number
ResourceReplicationControllers ResourceName = "replicationcontrollers"
// ResourceQuotas, number
ResourceQuotas ResourceName = "resourcequotas"
// ResourceSecrets, number
ResourceSecrets ResourceName = "secrets"
// ResourceConfigMaps, number
ResourceConfigMaps ResourceName = "configmaps"
// ResourcePersistentVolumeClaims, number
ResourcePersistentVolumeClaims ResourceName = "persistentvolumeclaims"
// ResourceServicesNodePorts, number
ResourceServicesNodePorts ResourceName = "services.nodeports"
// ResourceServicesLoadBalancers, number
ResourceServicesLoadBalancers ResourceName = "services.loadbalancers"
// CPU request, in cores. (500m = .5 cores)
ResourceRequestsCPU ResourceName = "requests.cpu"
// Memory request, in bytes. (500Gi = 500GiB = 500 * 1024 * 1024 * 1024)
ResourceRequestsMemory ResourceName = "requests.memory"
// Storage request, in bytes
ResourceRequestsStorage ResourceName = "requests.storage"
// CPU limit, in cores. (500m = .5 cores)
ResourceLimitsCPU ResourceName = "limits.cpu"
// Memory limit, in bytes. (500Gi = 500GiB = 500 * 1024 * 1024 * 1024)
ResourceLimitsMemory ResourceName = "limits.memory"
)
openshift额外支持的images相关的限制策略
// ResourceImageStreams represents a number of image streams in a project.
ResourceImageStreams kapi.ResourceName = "openshift.io/imagestreams"
// ResourceImageStreamImages represents a number of unique references to images in all image stream
// statuses of a project.
ResourceImageStreamImages kapi.ResourceName = "openshift.io/images"
// ResourceImageStreamTags represents a number of unique references to images in all image stream specs
// of a project.
ResourceImageStreamTags kapi.ResourceName = "openshift.io/image-tags"
此外,除了可以设置额度Quantity外,还可以指定配额的作用范围Scopes,其实就是作用于哪类pod上的:
- 是否是长期运行的pod
- 是否有资源上限的pod
目前只有pods数和计算资源(cpu,内存)才能指定作用域
// A ResourceQuotaScope defines a filter that must match each object tracked by a quota
type ResourceQuotaScope string
const (
// Match all pod objects where spec.activeDeadlineSeconds,这个是标明pod的运行时长参数
ResourceQuotaScopeTerminating ResourceQuotaScope = "Terminating"
// Match all pod objects where !spec.activeDeadlineSeconds , 长期运行的pod
ResourceQuotaScopeNotTerminating ResourceQuotaScope = "NotTerminating"
// Match all pod objects that have best effort quality of service, 只能用来描述资源无上限的pod数
ResourceQuotaScopeBestEffort ResourceQuotaScope = "BestEffort"
// Match all pod objects that do not have best effort quality of service, 资源有上限的pod
ResourceQuotaScopeNotBestEffort ResourceQuotaScope = "NotBestEffort"
)
下面举个例子
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources-long-running
spec:
hard:
pods: "4"
limits.cpu: "4"
limits.memory: "2Gi"
scopes:
- NotTerminating
上面的意思即是, 限制长期运行的pod最多只能创建4个,且共用4c和2G内存
如果不指定scopes的话,是描述的所有scopes的限制;
本文参考这里
可以看到,通过资源配额管理,可以帮助我们解决以下问题:
-
控制计算资源使用量
我们在实际生产环境中经常遇到的情况是,用户申请了过多的资源,用户应用的资源使用率太低,造成了资源的浪费。管理员通常会给集群设置超卖系数,来提高整个集群的资源使用率;另外管理员也会给用户设置资源配额上限,来限制用户使用资源的数量。通过上面的介绍我们可以看到,kubernetes的资源配额,我们可以从应用的层次上来进行配额管理,可以设置不同应用的资源配额上限。
-
控制besteffort类型POD资源使用量
如果POD中的所有容器都没有设置request和limit,那么这些POD的QoS类型是besteffort,这种类型的POD更方便kubernetes进行调度,但是存在的问题是,如果不对这些POD进行资源管理,那么就会导致这个kubernetes集群资源过载,会影响这个集群中的所有应用,所以通过将资源配额管理的作用范围设置成besteffort,kubernetes可以通过限制这些POD的资源,避免整个集群资源过载。
-
控制长期运行的应用和短暂运行的应用资源使用率
在实际使用中,在kubernetes集群中会同时存在两种类型的应用,一种是长期运行的应用,比如网站这种web应用,还有一种就是短暂运行的应用,比如编译网站的这种应用。通过资源配额管理,可以同时对这两种不同类型的应用设置资源使用上限,来控制不同应用的资源使用。
LimitRange
limtRange是面向pod和container级别的,为什么只能集群管理员才可设置呢,因为这个的提出是为了防止有些应用忘记加资源边界的限定,而占用过多的资源,那么有了limitRange就给它来个默认限制。
apiVersion: "v1"
kind: "LimitRange"
metadata:
name: "core-resource-limits"
spec:
limits:
- type: "Pod"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "200m"
memory: "6Mi"
- type: "Container"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "100m"
memory: "4Mi"
default:
cpu: "300m"
memory: "200Mi"
defaultRequest:
cpu: "200m"
memory: "100Mi"
maxLimitRequestRatio:
cpu: "10"
- type: "openshift.io/Image"
max:
storage: "1Gi"
- type: "openshift.io/ImageStream"
max:
openshift.io/image-tags: "10"
openshift.io/images: "12"
如上使用oc create后,会看到我们对某namespace下的pod和container做了默认的资源设置,

权限管理说明
这里不涉及到认证登录的介绍,openshfit支持很多认证方式,比如AllowAll,CA认证, HTPasswd, KeyStone, LDAP, Oauth等,这里为了简化,用默认的AllowAll来做权限控制的说明
权限管理,即访问API资源之前,必须要经过的访问策略校验,主要分为5种: AlwaysDeny、AlwaysAllow(默认)、ABAC、RBAC、Webhook
主要说明user, group, rule,role,policy,policybinding之间的关系,以及提出这些概念,各自是为了解决什么问题
- user和group
说到user其实就是一个用户账号(userAccount),用它来和k8s集群做交互(登录,kubectl等), 但还有一个容易混淆的概念就是sercieAccount,有了userAccount为什么还又来个serviceAccount的设计, 这两者有什么区别 ? 以下是kubernetes官方对两者的解释
user account是为人类设计的,而service account则是为跑在pod里的进程用的,运行在pod里的进程需要调用Kubernetes API以及非Kubernetes API的其它服务(如image repository/被mount到pod上的NFS volumes中的file等);
user account是global的,即跨namespace使用;而service account是namespaced内的,即仅在所属的namespace下使用;
user account可能会涉及到很多权限设定和商业逻辑在里面,而后者是更轻量级的,是集群用户针对某namespace内的服务使用的,一般遵循最小特权原则,如监控服务需要访问APIsever等;
useraccount需要借助第三方实现,后者系统都会默认在namesspace里创建default,亦可自定义
两者大部分流程是一致的,都是要先认证通过再校验权限,然后才是action, 实际上一般是由userAccount来控制serviceAccount来完成特定的任务, 比如一个用户A自建了服务1和服务2, 但只想把服务2开发给用户B,这样的serviceAccount就可以排上用场了, 又或者我有几个服务,有了serviceAccount就可以来限制用户的访问权限(list, watch, update, delete)了.
说到group就是方便对user的权限批量操作而设计;
用户可以被分配到一个或多个组,每个组代表一组特定的用户。组在同时向多个用户管理权限时非常有用。
- rule和role
rule是规则, 是对一组对象上被允许的动作(get, list, create, update, delete, deletecollection 和 watch)描述,可操作对象主要是 container,images,pod,servcie, project, user, build, imagestream, dc, route, templeate。
role 就是规则的集合,俗称角色, 不同对象上的不同动作,可以任意组成各种角色,系统默认的有 admin basic-user cluster-admin cluster-admin edit self-provisioner view;
policy,是策略, 保存特定namespace的所有角色roles的对象。 每个命名空间最多只有一个Policy策略。
rolebinding, 就是把user或者group与角色role进行关联,注意. user和group可以被关联到多个roles
pollicybing, 就是就是多个rolebindings的描述;
这样看,policy的概念提出有点儿扯淡了,感觉没什么用,其实不然,policy的提出主要是为了区分cluster-policy和local-policy的。
cluster policy是适用于所有namespace的角色和绑定; local policy则是试用于具体的某个namespace的;
以上可以通过oc describe clusterPolicy default来看查看所有详细的信息;
小节:
可以通过oc policy can-i --list查看自己可以干些什么
还可以通过oc policy who-can <动作> <资源对象>, 比如说查看谁能get pod之类的,就是oc policy who-can get pod
➜ openshift-docs git:(master) ✗ oc policy who-can get pod
Namespace: myproject
Verb: get
Resource: pods
Users: developer
system:admin
system:serviceaccount:default:pvinstaller
system:serviceaccount:myproject:deployer
system:serviceaccount:openshift-infra:build-controller
system:serviceaccount:openshift-infra:deployment-controller
system:serviceaccount:openshift-infra:deploymentconfig-controller
system:serviceaccount:openshift-infra:endpoint-controller
system:serviceaccount:openshift-infra:namespace-controller
system:serviceaccount:openshift-infra:pet-set-controller
system:serviceaccount:openshift-infra:pv-binder-controller
system:serviceaccount:openshift-infra:pv-recycler-controller
Groups: system:cluster-admins
system:cluster-readers
system:masters
system:nodes
如果openshift自带的角色不能满足的话,还可以自定义角色role
$ oc get clusterrole view -o yaml > clusterrole_view.yaml
$ cp clusterrole_view.yaml localrole_exampleview.yaml
$ vim localrole_exampleview.yaml
# 1. Update kind: ClusterRole to kind: Role
# 2. Update name: view to name: exampleview
# 3. Remove resourceVersion, selfLink, uid, and creationTimestamp
$ oc create -f path/to/localrole_exampleview.yaml -n <project_you_want_to_add_the_local_role_exampleview_to>
下文介绍实战,结合实际场景,如何设置权限,即整个开发管理流程实践说明
4.3.3 - 项目开发实战
下面的所有操作,都可以通过cli,web console,RestFul API实现,默认使用cli说明
创建项目
这里是接着oc cluster up后,来说的, 默认oc whoami是 developer,拥有admin的Role角色,俗称项目经理(管理员)
- 删除默认创建的项目,并创建一个实际中的项目
oc delete project myproject
oc new-project eshop --display-name="电商项目" --description="一个神奇的网站"
现在项目管理员可以创建任意多个项目,从前面的源码可以看到目前是没法针对项目管理员去限制可创建项目上限的。
- 查看项目状态
#oc status
In project 电商项目 (eshop) on server https://192.168.31.49:8443
You have no services, deployment configs, or build configs.
Run 'oc new-app' to create an application.
空空如也,有提示语句提示可通过oc new-app去创建具体应用的
创建应用
前面也说过,openshift的核心就是围绕应用的整个生命周期来的,所以从new-app说起
new-app的入口是NewCmdNewApplication(), 大部分实现是 func (c *AppConfig) Run() (*AppResult, error) 感兴趣的可以根据源码来理解openshift的devops理念。
- 创建应用的方式 现在可以通过3种方式(源码, docker镜像, 模板)来创建一个应用。
# oc new-app -h
#此处省略。。。
Usage:
oc new-app (IMAGE | IMAGESTREAM | TEMPLATE | PATH | URL ...) [options]
#此处省略。。。
有很多灵活简便的方式来创建应用,甚至可以直接oc new-app mysql来创建一个mysql服务
比如下面的例子,是基于nodejs-ex项目的master分支,创建应用
oc new-app https://github.com/xiaoping378/nodejs-ex.git#master
接着上面的nodejs-ex项目来说, 实际上,oc new-app就做了两件事,先build, 再deploy。
new-app一般会先创建一个bc, bc会产出一个iamge,new-app典型的还会创建一个dc,去部署新生成的image,也会创建相应的service来负载均衡方访问刚部署上的镜像里的业务。
这一切都是自动完成的,因为openshift origin里面有一些检测机制和默认规则,下面就针对上面那条命令看看内部都发生了什么
-
首先openshift会执行
git ls-remote, 来查看此项目的所有remote分支,如果存在master分支,下一步则直接clone和checkout了
checkout后,接着就是根据解析规则来定义如何build了。
-
build策略
首先会探测nodejs-ex项目根目录下,是否有dockerfile或者jenkinsfile,如果两者都没有则会根据“典型文件”判断这个项目的开发语言, 举例
如果存在app.json或者package.json文件,则认为是nodejs类型的项目, 更多的典型文件如下:
这部分的代码实现主要在 detector.go
未完,待续。。。
4.3.4 - DevOps实战-0
主要涉及到一键发布,快速回滚,弹性伸缩,蓝绿部署方面。
-
启动openshift
oc cluster up --version=v1.5.0-rc.0 --metrics --use-existing-config=true默认负责监控的pods占用资源太大了,可以这样限制下,或者cluster up时不加
--metricsoc login -u system:admin oc env rc hawkular-cassandra-1 MAX_HEAP_SIZE=1024M -n openshift-infra #重建下,变量才会生效 oc scale rc hawkular-cassandra-1 --replicas 0 -n openshift-infra oc scale rc hawkular-cassandra-1 --replicas 1 -n openshift-infra -
建立本地Git仓
默认官方给出的例子基本都需要和Github结合,实在不好本地实战演示,所以本地要来一个
gogs代码仓。oc login -u devloper oc new-project ci #先拉取所依赖镜像 docker pull openshiftdemos/gogs:0.9.97 docker pull centos/postgresql-94-centos7 #创建gogs服务,并禁用webhook时的TLS校验,不然无法触发build oc new-app -f https://raw.githubusercontent.com/xiaoping378/gogs-openshift-docker/master/openshift/gogs-persistent-template.yaml -p SKIP_TLS_VERIFY=true -p HOSTNAME=gogs-ci.192.168.31.49.xip.io上面的HOSTNAME,注意要换成自己宿主机的IPv4地址,默认创建的其他服务的路由都是这个形式的,
有个有意思的地方,为什么默认路由会是这种
name+IP+xip.io形式呢,奥秘在 http://xip.io 的公共服务上。 这其实是个特殊的域DNS server,比如我们查询域名gogs-ci.192.168.31.49.xip.io时 ,会返回192.168.31.49的地址回来, 而这个地址恰好是我们Router的地址,这样子Router会根据route的配置负责负载到对应的POD上。自己试验下就知道怎么回事了。dig http://gogs-ci.192.168.31.49.xip.io +short只做功能性演示,先不考虑https加密安全访问,创建完后,访问gogs服务
http://gogs-ci.192.168.31.49.xip.io
这个项目,第一个注册用户即为管理员,比如我现在去页面注册一个叫
developer的用户。 -
找个项目来实战吧
-
克隆远程项目,并设置
git clone https://github.com/xiaoping378/nodejs-ex.git && cd nodejs-ex git remote add gogs http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git -
通过web页面,在gogs上创建一个
nodejs-ex仓库, 并如下push刚才克隆的项目$ git push gogs master Username for 'http://gogs-ci.192.168.31.49.xip.io': developer Password for 'http://developer@gogs-ci.192.168.31.49.xip.io': Counting objects: 431, done. Delta compression using up to 4 threads. Compressing objects: 100% (210/210), done. Writing objects: 100% (431/431), 145.16 KiB | 0 bytes/s, done. Total 431 (delta 159), reused 431 (delta 159) To http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git * [new branch] master -> mastergogs的页面上会如实反馈信息
OK,现在本地项目就有了,接下来进入正题
-
-
在openshift部署此nodejs应用
#创建web namespace oc new-project web #先拉取依赖镜像 docker pull centos/mongodb-32-centos7 docker pull centos/nodejs-4-centos7 #部署此项目,并启用国内npm源和对应的git仓 oc new-app nodejs-mongo-persistent --name=nodejs-ex -p NPM_MIRROR=https://registry.npm.taobao.org -p SOURCE_REPOSITORY_URL=http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git默认此模板会从指定的URL地址拉取代码,并根据预先的配置,采取
Source编译策略,基于istag nodejs:4镜像编译出nodejs-mongo-persistent:latest镜像,编译出来的镜像又会自动触发部署。 -
最基本的DevOps能力
即push代码通过webhook触发自动编译,继而滚动部署
要实现这个目标前,需要先把webhook填写到gogs里。
在openshift界面上复制webhook地址
然后在gogs上填加一个webhook
这里我们随意修改些,然后推送代码,就会自动触发编译并滚动升级
➜ nodejs-ex git:(master) vim views/index.html ➜ nodejs-ex git:(master) ✗ git add . ➜ nodejs-ex git:(master) ✗ git commit -m "这又是个测试" [master 082f05e] 这又是个测试 1 file changed, 1 insertion(+), 1 deletion(-) ➜ nodejs-ex git:(master) git push gogs master Username for 'http://gogs-ci.192.168.31.49.xip.io': developer Password for 'http://developer@gogs-ci.192.168.31.49.xip.io': Counting objects: 4, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (4/4), 365 bytes | 0 bytes/s, done. Total 4 (delta 2), reused 0 (delta 0) To http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git c3592e6..082f05e master -> master编译成功后,会产生新镜像,继而触发滚动升级的截图
现实中,如果项目没有很好的自动化测试的话,我们肯定不会这样操作的,除非想被开掉了。
其实可以简单的去掉webhook,采用手动触发build: 界面操作的话,去build界面点击
Start Build,命令行的话如下oc start-build nodejs-mongo-persistent另外,如果发现新版本的应用有重大缺陷,想回滚以前的部署版本,也有对应的界面和命令
oc rollback nodejs-mongo-persistent --to-version=3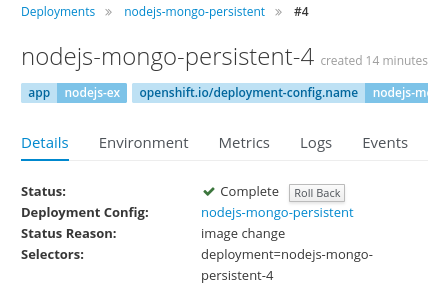
-
弹性伸缩
目前可以根据CPU使用率来进行弹性伸缩
有人问能不能基本mem进行弹性呢,其实这个是没什么意义的,一般应用都会自行缓存,内存基本只增不长, 所以cpu才能很好的实时反应业务的负载。
弹性伸缩前,要确保应用先行设置了cpu request,这点还没明白原因,为什么要这样,按理说,heapster一直会采集pod的资源使用情况的,HPA周期拿数据和设置的阈值对比就完了。
这里是部署界面的菜单栏,可以手动加上cpu request
添加 cpu request.
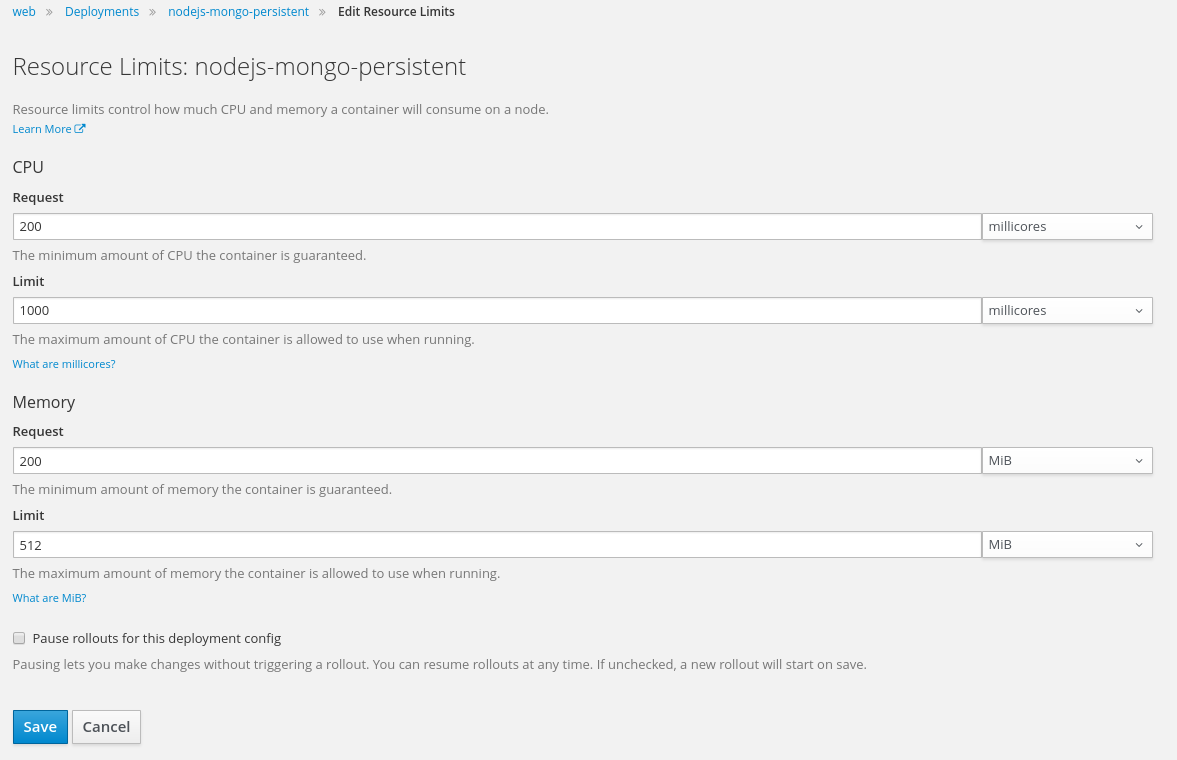
然后开启弹性伸缩特性,这里就不截图了,展示下命令行,我们设置成: 当cpu使用率达到80%时,就弹,最大可以弹出3个实例
oc autoscale dc/nodejs-mongo-persistent --max=3 --cpu-percent=80OK,之后我们通过ab工具简单做个压力模拟,因为环境在我的笔记本上,所以只模拟发送100万个连接,并发100的量
ab -n 1000000 -c 100 http://nodejs-mongo-persistent-web.192.168.31.49.xip.io/后台每1分钟采集一次cpu使用率,过不了一会儿,就会看到nodejs实例自动扩展了
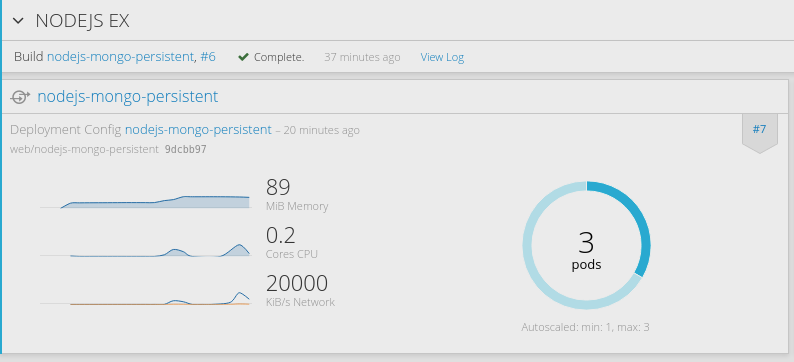
当业务量降下来时,会自动减少实例,是根据平均CPU使用率来操作的。
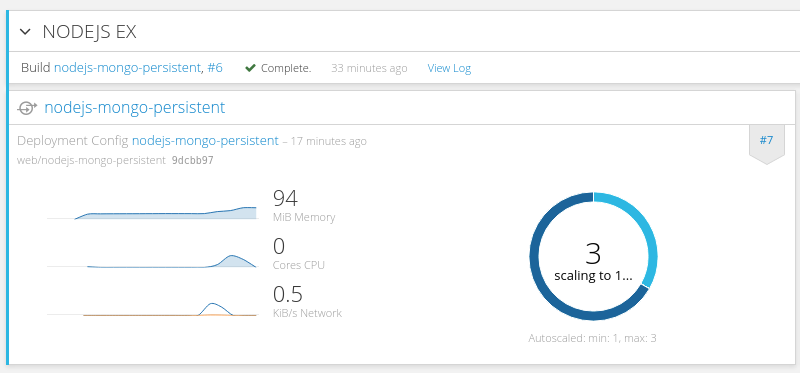
-
蓝绿部署
这个也是API级别的支持,不描述具体操作细节了,原理还是以前的,从负载均衡层面入手。 实现新旧版本同时存在。 并不是所有业务都适合蓝绿部署的,要看后台数据是否允许,新旧版本同时发生读写数据
在openshift里实现蓝绿部署的,就太简单了。具体就是在Route层面添加同一应用的多个版本的service,并设置分流权重 截图如下
界面设置,只是为了展示功能,我随便添加了个service
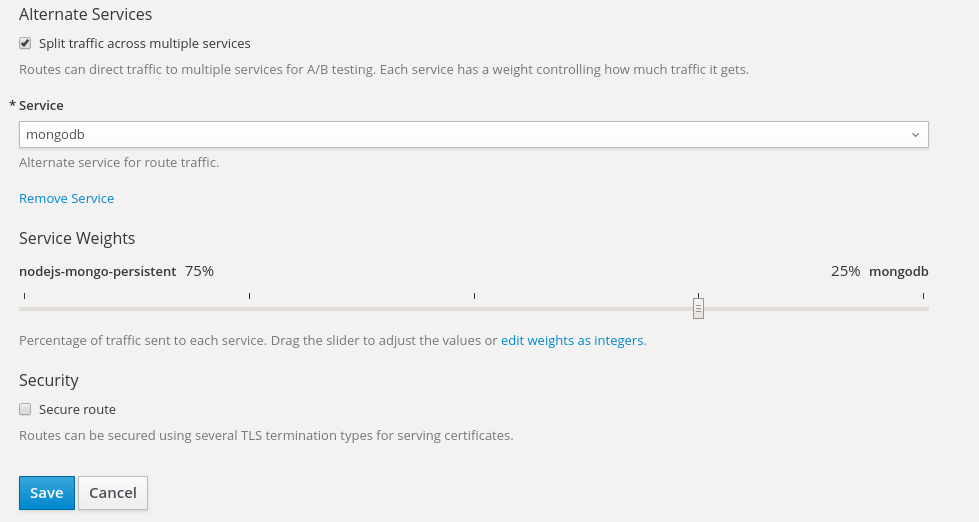
实际展示效果
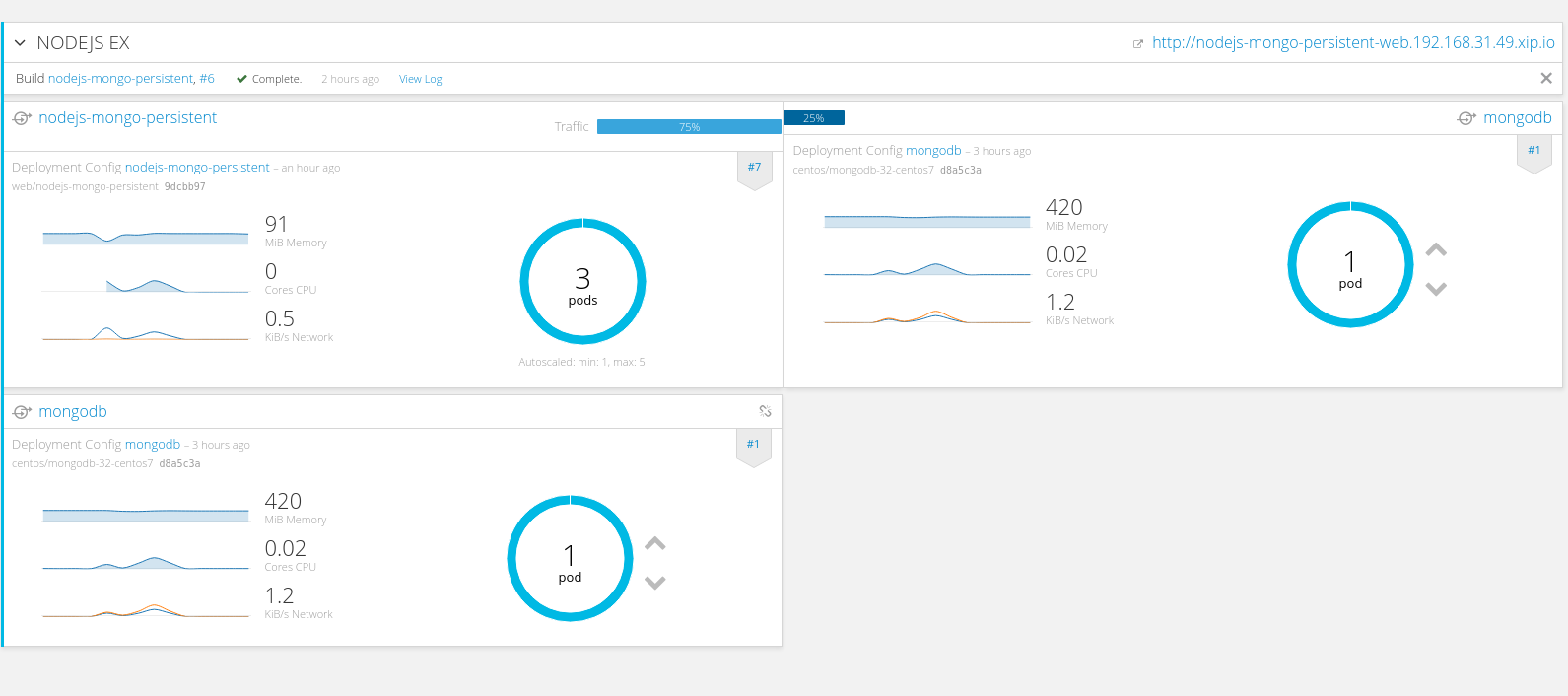
总结
Openshift平台本身在API层面实现了DevOps,所以基于它很容易做到DevOps as an service, 上面的演示可能与现实世界不太一样,
比如真实情况是有,测试,预发布,线上环境的,下次再分享: openshift基于jenkins pipeline如果实现更真实场景的需求。
4.3.5 - DevOps实战-1
本文主要介绍基于openshift如何完成开发->测试->线上场景的变更,这是一个典型的应用生产流程,来看看openshift是如何利用容器优雅的完成整个过程的吧
下文基于上篇DevOps实战-0 的nodejs-ex项目来说, 假设到这里,你本地已经有了nodejs-ex项目
准备3个project
用这3个project来模拟开发,测试,线上环境
现实中一般各个场景的服务器都是物理隔离的,这里可以利用--node-selector,来指定项目可以跑在哪些节点上。
oc login -u sysetm:admin
#晚上在笔记本上写此blog,没合适的环境,单机模拟多台 -- start
oc label node 192.168.31.49 web-prod=true web-dev=true web-test=true
#晚上在笔记本上写此blog,没合适的环境,单机模拟多台 -- end
#1.创建web-dev项目
#2.授权developer为开发组项目管理员
#3.授权测试和运维人员可以从开发组拉取镜像
oc adm new-project web-dev --node-selector='web-dev=true'
oc policy add-role-to-user admin developer
oc policy add-role-to-group system:image-puller system:serviceaccounts:web-test -n web-dev
oc policy add-role-to-group system:image-puller system:serviceaccounts:web-prod -n web-dev
oc adm new-project web-test --node-selector='web-test=true'
oc policy add-role-to-user admin tester
oc adm new-project web-prod --node-selector='web-prod=true'
oc policy add-role-to-user admin ops
-
你可能会注意到,这里用的
new-project前面还加了adm, 其实oc adm等效于oadm, 一般管理集群相关的用这个命令,这里是因为需要读取节点的标签(label)信息。 -
指定项目要运行那些节点,则是利用了注解-annotations, 即在原有的project结构上设置了注解,这样openshift在相应的项目里创建任何pod时,都对会自动注入node-selector
-
另外需要注意的,默认项目的管理员(developer)是没有权限读取node标签信息的,以前写过权限管理相关blog,集群管理员可以授权node访问权限,即使如此developer还是不能改写项目级别的标签的,举个例子: developer在开发环境的pod上指定了
--node-selector='web-dev=false', 最终这个pod的node-selector会是'web-dev=true, web-dev=flase', 导致最终不会被调度到任何节点上。 -
上面分别授权了3个用户,这里是不关心这些用户是否真实存在的,只是一个RABC的描述,因为是
oc cluster up起来的环境,默认使用anypassword的身份认证,所以登录时,任意用户名和密码都是可以登录OK的。 -
通过
oc describe policybinding -n web-dev可以查看授权情况, 如果觉得默认的role不满足需求的话,也可以自定义role,另外通过oc policy remove-role-from-group/user <Role> <name>可以移除相关授权,
初始化web-dev, web-test, web-prod环境
按照上篇DevOps实战-0里的方式
初始化我们的开发环境, 进入源码nodejs-ex目录
oc new-app -f openshift/template/nodejs-mongo-persistent.json --name=nodejs-ex \
-p NPM_MIRROR=https://registry.npm.taobao.org \
-p SOURCE_REPOSITORY_URL=http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git \
-n web-dev
初始化测试环境,相较于上一步的模板json,只是注掉bc和更改了triggers的is,后面会详细介绍之间的差异
oc new-app -f openshift/template/nodejs-mongo-persistent-test.json --name=nodejs-ex-test -n web-test
以tester登录web console,会发现只有mongodb部署上了,而前端nodejs还在等待依赖的镜像 web-dev/nodejs-mongo-persistent:test。
初始化生产环境, 这个生产的template.json有点儿简单,负载均衡和弹性伸缩都没有启用。
oc new-app -f openshift/template/nodejs-mongo-persistent-prod.json --name=nodejs-ex-prod -n web-prod
实战模拟,开发->测试->发布
-
developer开发完特性或者修复完bug,push代码到镜像仓。
这里分享一个很方便的技巧,就是
oc rsync, 这个可以实时的同步本地目录到容器了,避免了频繁编译镜像和临时挂载目录到镜像里的hack了。vim ... git add . git commit -m "fix bugs" git push gogs master如上,由于上篇中设置了webhook, developer提交代码会触发了自动编译并部署,确认部署后的环境是否修复了bug,如果单元测试通过,那就要通知测试团队(如今大部分公司,应该没有测试人员了吧,也可以直接变更到线上)
测试那边的环境里一直在等待这个镜像
web-dev/nodejs-mongo-persistent:test, 而默认developer配置成默认编译出来的是web-dev/nodejs-mongo-persistent:latestoc login -u developer oc tag web-dev/nodejs-mongo-persistent:latest web-dev/nodejs-mongo-persistent:v1.1 oc tag web-dev/nodejs-mongo-persistent:v1.1 web-dev/nodejs-mongo-persistent:test如上操作后,开发人员更新版本号,然后在web-dev环境里会打上一个test的镜像tag出来,操作完如下所示
➜ nodejs-ex git:(master) oc get is NAME DOCKER REPO TAGS UPDATED nodejs-mongo-persistent 172.30.1.1:5000/web-dev/nodejs-mongo-persistent test,v1.1,latest 49 seconds ago ➜ nodejs-ex git:(master) ➜ nodejs-ex git:(master) oc get istag NAME DOCKER REF UPDATED IMAGENAME nodejs-mongo-persistent:latest 172.30.1.1:5000/web-dev/nodejs-mongo-persistent@sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 3 minutes ago sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 nodejs-mongo-persistent:v1.1 172.30.1.1:5000/web-dev/nodejs-mongo-persistent@sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 2 minutes ago sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 nodejs-mongo-persistent:test 172.30.1.1:5000/web-dev/nodejs-mongo-persistent@sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 55 seconds ago sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7这样一来,测试环境里就会自动部署上刚才开发人员的环境了,再也不会有因为环境差异问题和测试吵吵了。
这一切都得益于openshift里新添加的imageStreams,它打通了编译和部署的环节,能自动通知对方,继而自动触发下一步动作。
测试通过后,通知Ops再重新tag成线上所需要的镜像tag,这样线上就会根据配置自动滚动升级了。
#假设一个叫ops的人负责上线,那首先ops得有具备web-dev项目里编辑is的能力 oc login -u developer #不该给ops这么高权限的,应该自定义一个只能tag is的role,这里为了简单演示 oc policy add-role-to-user edit ops -n web-dev如上操纵,ops就具备了tag web-dev项目的镜像的能力,也可以通过UI来查看和授权
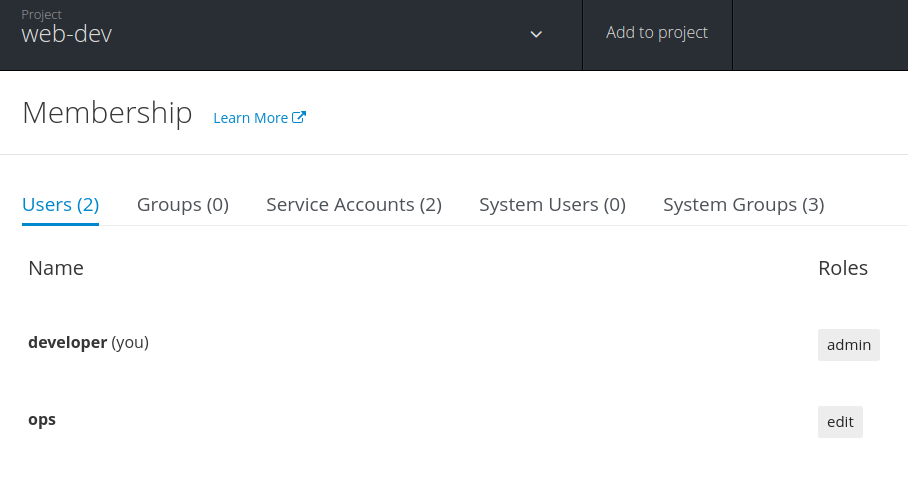
oc login -u ops oc tag web-dev/nodejs-mongo-persistent:v1.1 web-dev/nodejs-mongo-persistent:prod然后打上线上依赖的镜像tag即可,发布上线,这样就完成了开发->测试->发布一条线,很快捷的
人工干预上线了
总结
openshift 利用镜像tag的能力,来实现不同场景的同步,单纯基于docker也可以实现以上目标的,只是不够平台化,还是以前的脚本打天下,远不如openshift在API层面解决来的强大和灵活。
4.3.6 - 编译和目录结构介绍
介绍openshift的源码编译和目录结构组织,为了方便代码调试和了解大型Golang项目的构建方式
编译
无论是openshift还是Kubernetes等大型Golang项目都用到了Makefile, 所以有必要从此开始说起,这里只说项目里用到的makefile特性,想了解更多的可以参考跟我一起写Makefile
Makefile介绍
makefile 关系到了整个工程的编译规则。一个工程中的源文件不计数,其按类型、功能、 模块分别放在若干个目录中,makefile 定义了一系列的规则来指定,哪些文件需要先编译, 哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为 makefile 就像一个 Shell 脚本一样,其中也可以执行操作系统的命令。 makefile 带来的好 处就是——“自动化编译”,一旦写好,只需要一个 make 命令,整个工程完全自动编译, 极大的提高了软件开发的效率。
Makefile里的规则,就在做两件事,一个是指明依赖关系,另一个是生成目标的方法
Golang项目里用到的Makefile规则比较简单,基本就是定义一个目标的生成方法,下面的示例是Openshift项目里makefile中定义的第一个目标。
all build:
hack/build-go.sh $(WHAT) $(GOFLAGS)
.PHONY: all build
-
all build,是定义的目标,看到这个就知道可以在源码的根目录上执行make all build来编译了 -
第二行说明生成目标的方法,就是去hack目录下执行build-go.sh脚本,这里还支持传入一些参数
-
第三行
.PHONY,起到一个标识的作用,没什么实际意义,是用来告诉make命令,这里是个伪目标,也可以说成是默认目标,所以在openshift的根目录上直接执行make, 等效于make all build
还可以自己决定是否编译出镜像或者rpm包(make release, make build-rpms)
编译openshift
上边介绍了,直接敲make就可以自动编译出所有平台(linux, mac, windows)的二进制,编译前介绍两个hack方法,
-
在hack/build-go.sh的第二行加上
set -x, 这样的话,shell脚本在运行时,里面的所有变量和执行路径会全部打印出来,一目了然,不用自己一行一行的加echo debug了 -
如下修改hack/build-cross.sh,不然会编译出多平台的二进制,花的时间略长啊。。。
# by default, build for these platforms platforms=( linux/amd64 # darwin/amd64 # windows/amd64 # linux/386 )
下面简易说下执行make后,都发生了什么,只会捡关键点说。
➜ origin git:(xxpDev) ✗ make
hack/build-go.sh
# 初始化一大堆变量,关键函数都在common.sh里实现的
source hack/common.sh hack/util.sh hack/lib目录下的所有脚本
# 还会改动GOPATH,然后会在$GOPATH/src/github.com/openshift下建个软连指向origin目录
export GOPATH=_output/local/go
# 最终组合成下面一条最原始的命令,来进行编译
go install \
-pkgdir /home/xxp/Github/src/github.com/openshift/origin/_output/local/pkgdir/linux/amd64 \
-tags ' ' \
-ldflags '-X github.com/openshift/origin/pkg/bootstrap/docker.defaultImageStreams=centos7 \
-X github.com/openshift/origin/pkg/cmd/util/variable.DefaultImagePrefix=openshift/origin \
-X github.com/openshift/origin/pkg/version.majorFromGit=3 \
-X github.com/openshift/origin/pkg/version.minorFromGit=6+ \
-X github.com/openshift/origin/pkg/version.versionFromGit=v3.6.0-alpha.0+83e3250-176-dirty \
-X github.com/openshift/origin/pkg/version.commitFromGit=83e3250 \
-X github.com/openshift/origin/pkg/version.buildDate=2017-04-06T05:34:29Z \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.gitCommit=43a9be4 \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.gitVersion=v1.5.2+43a9be4 \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.buildDate=2017-04-06T05:34:29Z \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.gitTreeState=clean' \
github.com/openshift/origin/cmd/openshift \
github.com/openshift/origin/cmd/oc \
github.com/openshift/origin/pkg/sdn/plugin/sdn-cni-plugin \
github.com/openshift/origin/vendor/github.com/containernetworking/cni/plugins/ipam/host-local \
github.com/openshift/origin/vendor/github.com/containernetworking/cni/plugins/main/loopback
可以看到openshift会编译出5个二进制来,其中3个和网络CNI接口有关,最后会放置到_output/local/bin/linux/amd64, 并作相关的软链接(oadm, kubelet)
所以以后分析程序的切入点就从cmd/openshift和 cmd/oc入手就行了
来看下编译成果
➜ origin git:(xxpDev) ✗ _output/local/bin/linux/amd64/oc version
oc v3.6.0-alpha.0+83e3250-176-dirty
kubernetes v1.5.2+43a9be4
features: Basic-Auth
看到输出v3.6.0-alpha.0+83e3250-176-dirty, 这就是上面编译时传进去的参数。
-X github.com/openshift/origin/pkg/version.majorFromGit=3,意思是说编译文件github.com/openshift/origin/pkg/version.go时,对常量majorFromGit赋值为3
项目目录结构
-- 未完待续
4.3.7 - 多负载均衡方案
haproxy在openshift里默认有两种用处,一个种负责master的高可用,一种是负责外部对内服务的访问(ingress controller)
平台部署情况:
- 3台master,etcd
- 1台node
- 1台lb(haproxy)
haproxy负载均衡master的高可用
lb负责master间的负载均衡,其实负载没那么大,更多得是用来避免单点故障
Debug介绍
-
默认安装haproxy1.5.18版本,开启debug方法
# 默认systemd对haproxy做了封装,会以-Ds后台形式启动,debug信息是看不到的 systemctl stop harproxy # vi /etc/haproxy/haproxy.cfg log 127.0.0.1 local3 debug # 手动启动haproxy haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -d不知道是不是哪里还需要设置,打印出来的日志,信息并不是不太多
另外浏览
https://lbIP:9000, 可以看到统计信息
配置介绍
-
使用openshift-ansible部署后,harpxy的配置如下
[root@node4 ~]# cat /etc/haproxy/haproxy.cfg # Global settings #--------------------------------------------------------------------- global chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 20000 user haproxy group haproxy daemon log /dev/log local0 info #定义debug级别 # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults #默认配置,后面同KEY的设置会覆盖此处 mode http #工作在七层代理,客户端请求在转发至后端服务器之前将会被深度分板,所有不与RFC格式兼容的请求都会被拒绝,一些七层的过滤处理手段,可以使用。 log global #默认启用gloabl的日志设置 option httplog #默认日志类别为http日志格式 option dontlognull #不记录健康检查日志信息(端口扫描,空信息) # option http-server-close option forwardfor except 127.0.0.0/8 #如果上游服务器上的应用程序想记录客户端的真实IP地址,haproxy会把客户端的IP信息发送给上游服务器,在HTTP请求中添加”X-Forwarded-For”字段,但当是haproxy自身的健康检测机制去访问上游服务器时是不应该把这样的访问日志记录到日志中的,所以用except来排除127.0.0.0,即haproxy自身 option redispatch #代理的服务器挂掉后,强制定向到其他健康的服务器,避免cookie信息过时,仍可正常访问 retries 3 #3次连接失败就认为后端服务器不可用 timeout http-request 10s #默认客户端发送http请求的超时时间, 防DDOS攻击手段 timeout queue 1m #当后台服务器maxconn满了后,haproxy会把client发送来的请求放进一个队列中,一旦事件超过timeout queue,还没被处理,haproxy会自动返回503错误。 timeout connect 10s #haproxy与后端服务器连接超时时间,如果在同一个局域网可设置较小的时间 timeout client 300s #默认客户端与haproxy连接后,数据传输完毕,不再有数据传输,即非活动连接的超时时间 timeout server 300s #定义haproxy与后台服务器非活动连接的超时时间 timeout http-keep-alive 10s #默认新的http请求建立连接的超时时间,时间较短时可以尽快释放出资源,节约资源。和http-request配合使用 timeout check 10s #健康检测的时间的最大超时时间 maxconn 20000 #最大连接数 listen stats :9000 mode http stats enable stats uri / frontend atomic-openshift-api bind *:8443 default_backend atomic-openshift-api mode tcp #在此模式下,客户端和服务器端之前将建立一个全双工的连接,不会对七层(http)报文做任何检查 option tcplog backend atomic-openshift-api balance source #是基于请求源IP的算法,此算法对请求的源IP时行hash运算,然后将结果除以后端服务器的权重总和,来判断转发至哪台后端服务器,这种方法可保证同一客户端IP的请求始终转发到固定定的后端服务器。 mode tcp server master0 192.168.56.100:8443 check server master1 192.168.56.101:8443 check server master2 192.168.56.102:8443 check官方文档介绍的非常详细,感兴趣的可以继续深入研究
Router负责外部对内服务的访问
部署一个Router并实现高可用
router是由harpoxy来承担的, 可以理解成kubernetes里的ingress controller部分,默认跑在容器里。
-
使能 default项目下router,可以访问hostnetwork
oc adm policy add-scc-to-user hostnetwork system:serviceaccount:default:router -
使能其可以查看 label
oc adm policy add-cluster-role-to-user \ cluster-reader \ system:serviceaccount:default:router -
部署1个router, 选择具有标签
router=true的节点# 对节点设置标签 oc label 192.168.56.110 router=true # 部署并指定serviceaccount oc adm router router --replicas=1 --selector='router=true' --service-account=router -
设置router自身的高可用,参考这里
默认使用keepalived实现多个router的高可用,访问router变成访问VIP地址,keepalived再根据权重和健康监测,利用VRRP通告外界后台到底那个router在服务。
# 添加另一个node作为冗余 oc label no 192.168.56.111 router=true oc scale dc router --replicas=2 #绑定serviceaccount特权,因为keepalived要操作iptables oc adm policy add-scc-to-user privileged system:serviceaccount:default:ipfailover #创建keepalived并指定VIP oc adm ipfailover ha-router \ --replicas=2 --watch-port=80 \ --selector="router=true" \ --virtual-ips="192.168.56.170" \ --iptables-chain="INPUT" \ --service-account=ipfailover --create这样,刚才创建的router就自高可用了,通过
192.168.56.170来访问,有一点值得注意,- 按照现在的例子,如果以后还有router做高可用的话,要加上
--vrrp-id-offset=1,保证一个vip用一个独有的vrrp-id。
- 按照现在的例子,如果以后还有router做高可用的话,要加上
Router分片
路由分片的概念,就是集群内有多个router,通过label来负责不同的routes。
这样可以实现一个project独享一个router,或者某几个route独享一个router,再或者大型集群,更多样化的需求,用这个router sharding的概念也可以满足。
我现在还没有具体的场景,先不实践,后续有机会会跟进更新下。
4.3.8 - 镜像管理
刚接触docker时,第一个接触到的应该就是镜像了,docker之所以如此火热,个人认为一大部分原因就是这个镜像的提出,极大的促进了DevOps推广和软件复用的能力。
而openshift对镜像的管理非常强大,直到写这篇blog,我才真正意识到这点,甚至犹豫是不是要放到开发实战篇后再来写镜像管理。
简要说下openshift里使用镜像的情况:
- 首先openshift可以利用任何实现了
Docker registry API的镜像仓,比如,Vmware的Harbor项目,Docker hub以及集成镜像仓( integrated registry) - 集成镜像仓,openshift内部的,可以动态生成,自动让用户编译的镜像有地方存, 其次它还负责通知openshift镜像的变动,然后openshift会根据策略去决定编译其他依赖镜像还是部署应用
- 第三方镜像, 可通过命令
oc import-image <stream>来实时获取镜像tag信息并转换成镜像流,继而触发后续的编译或者部署。 - 当然
oc new-app也支持直接从第三方镜像仓或者本地镜像里启动一个应用
文末有安装集成镜像仓的说明,先介绍image Streams 和 istag的概念和应用场景。
镜像管理
-
openshift基于docker的image概念又延伸出了Image Streams和Image Stream Tags概念
默认openshift项目下会有一些镜像流,是供自带模板里用的,所以想加速部署模板的话,可以在改这里,通过istag指向本地镜像仓。
oc get is -n openshift oc get istag -n openshiftimage,通俗讲就是对应用运行依赖(库,配置,运行环境)的一个打包。
docker pull push, 就是操作的镜像。 为什么openshift还要抽象出is和istag呢,主要是为了打通集成编译和部署环节(bc和dc),原生API就支持了DevOps理念。后面会细讲bc和dcis,开发人员可以理解成git的分支,每个分支都会编译很多临时版本出来,这个就是对应到is~=分支和istag~=版本号。 其实is和istag只是记录了一些映射关系,并不会存放实际镜像数据,比如is里记录了build后要output的镜像仓地址和所有tags,而istag里又记录了具体某个tag与image(可能是存于外部镜像仓,也能是某个is)的关系, 利用此实现了bc/dc和镜像的解耦。
这里通过部署jenkins服务,来初步了解下具体的含义,
- 创建ci项目
oc new-project ci # 先拉取必要镜像 docker pull openshift/jenkins-1-centos7 #通过模板部署,下面一条命令就可以创建一个临时的jenkins服务的 #oc new-app jenkins-ephemeral #跑之前我们先来注意几点- 更改默认的is
先来查看默认的is
oc get template jenkins-ephemeral -n openshift -o json ... "triggers": [ { "imageChangeParams": { "automatic": true, "containerNames": [ "jenkins" ], "from": { "kind": "ImageStreamTag", "name": "${JENKINS_IMAGE_STREAM_TAG}", "namespace": "${NAMESPACE}" }, "lastTriggeredImage": "" }, "type": "ImageChange" }, { "type": "ConfigChange" } ] ... { "name": "NAMESPACE", "displayName": "Jenkins ImageStream Namespace", "description": "The OpenShift Namespace where the Jenkins ImageStream resides.", "value": "openshift" }, { "name": "JENKINS_IMAGE_STREAM_TAG", "displayName": "Jenkins ImageStreamTag", "description": "Name of the ImageStreamTag to be used for the Jenkins image.", "value": "jenkins:latest" } ...可以看到默认模板里部署jenkins时,会从openshfit的namespace里拉取jenkins:latest的镜像, 去openshift项目里找找看,确实存在对应的is
➜ ~ oc get is -n openshift | grep jenkins jenkins 170.16.131.234:5000/openshift/jenkins latest,1 2 days ago ➜ ~ oc get istag -n openshift | grep jenkins:latest jenkins:latest openshift/jenkins-1-centos7@sha256:ab590529e20470e53c1d4b6b970de5d4fd357d864320735a75c1df0e2fffde07 2 days ago sha256:ab590529e20470e53c1d4b6b970de5d4fd357d864320735a75c1df0e2fffde07上面的命令的输出,有两个点要阐述下,
- is里的
170.16.131.234:5000/openshift/jenkins是个可有可无的地址,一般系统会填写集成镜像仓的地址 - 而istag里
openshift/jenkins-1-centos7@sha256:ab则是指明了对应tag的镜像来源,
这样的话,默认执行
oc new-app jenkins-ephemeral的话,会从docker.io那里拉取镜像 openshift/jenkins-1-centos7@sha256:ab590529e20470e53c1d4b6b970de5d4fd357d864320735a75c1df0e2fffde07为了加速部署,我们把刚才pull下来的镜像,push到集成镜像仓里
#添加用户 #htpasswd /etc/origin/master/htpasswd xxp docker tag openshift/jenkins-1-centos7 hub2.300.cn/openshift/jenkins docker login -u developer -p `oc whoami -t` hub2.300.cn docker push hub2.300.cn/openshift/jenkinspush完后再来看istag的变化,由以前的
openshift/jenkins-1-centos变为了170.16.131.234:5000/openshift/jenkins➜ ~ oc get istag -n openshift | grep jenkins:latest jenkins:latest 170.16.131.234:5000/openshift/jenkins@sha256:dc0f434a492d11d6ae13711e77f87303a06a8fc0fb3a97ae327a4b88c33435b6 21 hours ago sha256:dc0f434a492d11d6ae13711e77f87303a06a8fc0fb3a97ae327a4b88c33435b6这里是push到集成镜像仓后,系统会自动更新对应的is和istag, 为了加速部署,更改istag还可以通过import-image从私有镜像仓(harbor)里来完成
这样再来部署jenkins应用就快速多了
还有很多更细致的东西,比如如何周期同步第三方镜像仓等等,有需要的查看官文
安装独立镜像仓
可以通过openshift-ansible一次性安装OK,这里使用CLI安装,正好可以串一下openshift里的各种概念的使用场景。
部署
oc project default
oc adm policy add-scc-to-user privileged system:serviceaccount:default:registry
oc label node 192.168.56.102 registry=true
#使用hostPath存储,要在node上放行权限,默认registry用的1001 userID, 不然后续挂载进去的volume,没有写权限
sudo chown 1001:root /home/registry
#注意要指定使用的镜像版本,默认是拉取最新的, 一定要指明``--volume``参数,不然deploy,不会挂载主机目录,官文这里遗漏了。
oc adm registry --images="openshift/origin-docker-registry:v1.4.1" --selector="registry=true" --mount-host="/home/registry" --service-account=registry --volume='/registry'```
中间莫名出现部署``error``的状态,重新部署了下``oc deploy docker-registry --retry``
### 加密镜像仓
- 先拿到serviceIP
```bash
[root@node0 master]# oc get svc docker-registry
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
docker-registry 170.16.132.252 <none> 5000/TCP 1h
- 创建自签名证书,如果已经有了,跳过此步
oc adm ca create-server-cert \
--signer-cert=/etc/origin/master/ca.crt \
--signer-key=/etc/origin/master/ca.key \
--signer-serial=/etc/origin/master/ca.serial.txt \
--hostnames='hub.example.com,docker-registry.default.svc.cluster.local,170.16.132.252:5000' \
--cert=/etc/secrets/registry.crt \
--key=/etc/secrets/registry.key
-
创建secret, secret是专门来保存敏感信息的,比如密码,sshkey,token信息等等
更详细的介绍可以查看这里
oc secrets new registry-secret \ /etc/secrets/registry.crt \ /etc/secrets/registry.key -
绑定secret到serviceaccount
oc secrets link registry registry-secret
oc secrets link default registry-secret
- 更新dc,添加volume,把新创建的secret挂进去
oc volume dc/docker-registry --add --type=secret \
--name=docker-registry --secret-name=registry-secret -m /etc/secrets
如果想移除的话,如下
oc volume dc/docker-registry --remove --name=docker-registry
- 更新环境变量
oc set env dc/docker-registry \
REGISTRY_HTTP_TLS_CERTIFICATE=/etc/secrets/registry.crt \
REGISTRY_HTTP_TLS_KEY=/etc/secrets/registry.key
- 更新健康监测 HTTP->HTTPS
oc patch dc/docker-registry -p '{"spec": {"template": {"spec": {"containers":[{
"name":"registry",
"livenessProbe": {"httpGet": {"scheme":"HTTPS"}}
}]}}}}'
oc patch dc/docker-registry -p '{"spec": {"template": {"spec": {"containers":[{
"name":"registry",
"readinessProbe": {"httpGet": {"scheme":"HTTPS"}}
}]}}}}'
- 验证是否OK
[root@node0 master]# oc logs dc/docker-registry | grep tls
time="2017-03-02T16:01:41.113619323Z" level=info msg="listening on :5000, tls" go.version=go1.7.4 instance.id=594aa09b-4540-4e38-a85a-851261cd1254
添加路由
oc create route passthrough registry --service=docker-registry --hostname=hub2.300.cn
登录镜像仓
oc policy add-role-to-user admin developer -n default
oc login -u developer
docker login -u developer -p `oc whoami -t` hub2.300.cn
- push镜像
docker push hub2.300.cn/default/busybox
安装镜像仓console
- oc利用官方模板安装
oc create -n default -f https://raw.githubusercontent.com/openshift/openshift-ansible/master/roles/openshift_hosted_templates/files/v1.4/origin/registry-console.yaml
oc create route passthrough --service registry-console \
--hostname hub3.300.cn \
-n default
oc new-app -n default --template=registry-console \
-p OPENSHIFT_OAUTH_PROVIDER_URL="https://192.168.31.100:8443" \
-p REGISTRY_HOST=$(oc get route docker-registry -n default --template='{{ .spec.host }}') \
-p COCKPIT_KUBE_URL=$(oc get route registry-console -n default --template='https://{{ .spec.host }}')
- 登录浏览器打开
https://hub3.300.cn/registry,使用已有的账户登录,比如这里是默认的developer和developer。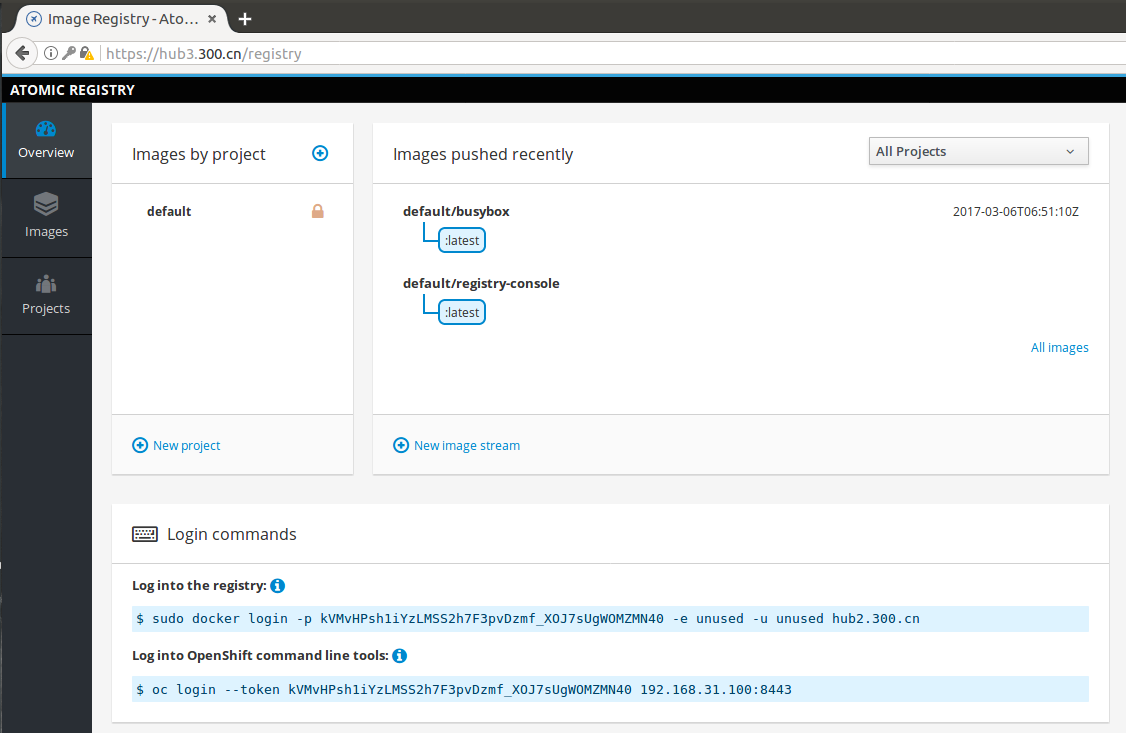
4.3.9 - 性能优化指南
主要参考的官方链接, 本文是基于openshift 3.5说的。
概览
本指南提供了如何提高OpenShift容器平台的集群性能和生产环境下的最佳实践。 主要包括建立,扩展和调优OpenShift集群的推荐做法。
个人看法,其实性能这个东西是个权衡的过程,根据自身硬件条件和实际需求,选择适合自己的调优手段。
安装实践
网络依赖
首先安装自然要选择官方的openshift-ansible项目, 默认是rpm安装方式,需要依赖网络,比如要去联网下载atomic-openshift-*, iptables, 和 docker包依赖,
如果有不能联网的节点,可以参考我之前写的离线安装openshift。
ansible优化
官方推荐使用ansible安装,这里说下针对ansible的优化,以提高安装效率,主要参考ansible官方blog,
如果参考上文离线安装的话,不建议跨外网连接rpm仓或者镜像仓,下面是推荐的ansible配置
# cat /etc/ansible/ansible.cfg
# config file for ansible -- http://ansible.com/
# ==============================================
[defaults]
forks = 20 # 20个并发是理想值,太高的话中间会有概率出错
host_key_checking = False
remote_user = root
roles_path = roles/
gathering = smart
fact_caching = jsonfile
fact_caching_connection = $HOME/ansible/facts
fact_caching_timeout = 600
log_path = $HOME/ansible.log
nocows = 1
callback_whitelist = profile_tasks
[privilege_escalation]
become = False
[ssh_connection]
ssh_args = -o ControlMaster=auto -o ControlPersist=600s
control_path = %(directory)s/%%h-%%r
pipelining = True # 多路复用,减少了控制机和目标间的连接次数,加速了性能。
timeout = 10
网络配置
这里必须要提下,一定要安装前做好网络规划,不然后面改起来很麻烦,
默认是每个node上最多可跑110个pods,这个要看自身硬件条件,比如说我的环境全是高配物理机,我就改成了,每个节点可以跑1024个pods,这个主要改下面的地方。
openshift_node_kubelet_args={'pods-per-core': ['0'], 'max-pods': ['1024'], 'image-gc-high-threshold': ['90'], 'image-gc-low-threshold': ['80']}
osm_host_subnet_length=10
osm_cluster_network_cidr=12.1.0.0/12
关于网络的更多优化项,后面有单独介绍。
主机节点优化
openhshift集群里,除了pod间的网络通信外,最大的开销就是master和etcd间的通信了,openshift的master集成了k8s里的api-server, master主要通过etcd来交互node状态,网络配置,secrets和卷挂载等等信息
master侧
主要优化点包括:
- master和etcd尽量部署在一起.
- 高可用集群里,master尽量部署在低延迟的网络里.
- 确保**/etc/origin/master/master-config.yaml**里的etcds,第一个是本地的etcd实例.
node侧
node节点的配置主要在**/etc/origin/node/node-config.yaml**里, 优化点视具体情况定,主要可以优化的点有:
- iptables synchronization period,
- MTU值
- 代理模式
配合自文件里还可以配置kubelet的启动参数,主要关注两点pods-per-core 和 max-pods,这两个决定了node节点的pod数,两者不一致时,取值小的。如果数值过大(严重超卖)会导致:
- 增加cpu消耗,主要是docker和openshift自身管理消耗的
- 降低pod调度效率
- 加大了OOM的风险
- 分配pod ip出异常(可能地址池不够了,默认254个ip)
- 影响应用的性能
有一点要注意,k8s体系的平台,跑一个pod,实际会启动两个容器,一个pause先于业务容器启动,主要负责网络事项,所以跑10个pods,实际上会运行20个容器
etcd节点
etcd是一个分布式的key-value存储,所以有条件的话,存储读写性能的提升,上ssd最好了。
其次是网络的优化,比如和masters部署在一起,或者提供专网连接。
etcd实际使用中,最好的提升手段,是关注内存,这个官网有个换算公式的,多少pods推荐多大内存的使用
内核优化
上面的所有节点,内核层面都需要做些优化,这里推荐使用tuned工具来做,这点属于常规运维优化了,具体可以参考这里来做, 不想明白原理的,可以如下 快速操作,redhat的人已经自动化了。
yum install tuned
systemctl start tune
systemctl enable tuned
tuned-adm profile throughput-performance)来做
资源优化
超卖现象
主要是资源管理这块儿的注意点, 我以前有blog专门介绍过,主要值得一提的是,这里有个隐形的QoS级别
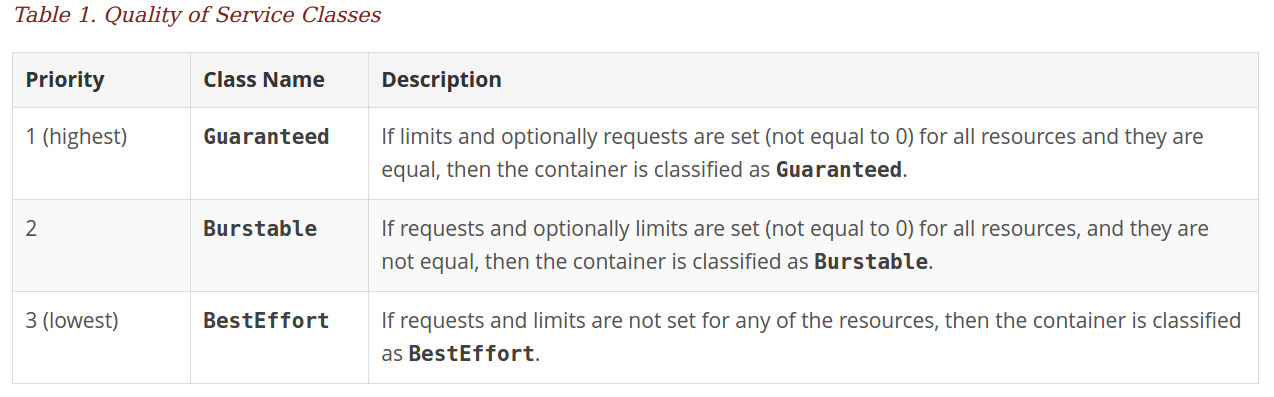
Guaranteed类型的pod是优先级最高的,是有保证的,只会在程序本身“异常”超出limits(一般的应用在pod层设置了limits,就不会超过该限制的,除非是java系的,其需要用环境变量来控制),才会被杀掉,其他类型的配额在集群资源紧张时会被kill掉的。
这块儿更多的细节也可以参考官文
镜像
这里需要注意的是,可以提前把需要的基础镜像先pull到node节点上,比如origin-pod镜像等,还有其他自定义的Gold 镜像,这样可以减少应用部署时间。
如果是采用镜像方式部署集群的话,也可以采取提前pull镜像的方式,当然有私有镜像仓的,可以忽略。
主要是现在默认的镜像拉取策略就是IfNotPresent,才能完成加速部署的效果
线上debug容器
线上容器环境可能很干净, 如何调试一个线上正在运行的容器,估计困扰过很多开发人员,这个其实利用docker原生特性,可以很easy的做到
比如你自己build一个工具包镜像tools,里面装有tcpdump,perf,strace等等debug工具,如下可以很方便的动态的嵌入到运行的线上容器中。
docker run -t --pid=container:production \
--net=container:production \
--cap-add sys_admin \
--cap-add sys_ptrace \
tools
当然万能的日志调式,也是OK的。
存储优化
这里的存储说的是docker的graph驱动( Device Mapper, Overlay, 和 Btrfs),首先overlay在启停容器速度方面要优于devicemapper,其还能带来更优良的页面缓存共享,但存在POSIX兼容性问题,比如不支持SELinux。
官方是推荐使用thin devicemapper的,但需要额外的独立块盘才能搞定。如果系统是7.2的话,使用overlay亦可,关闭selinux的代价就是牺牲部分容器安全。
路由和网络优化
openshift里的Router是基于haproxy做的,等价于k8s里的nginx ingress服务,提供集群内的service供外访问能力。
一般一个4 vCPU/16GB RAM的虚机,可以提供7000-32000 HTTP keep-alive连接请求,这取决于连接是否加密和页面大小,如果是物理机的话,性能会翻倍。
可通过Router sharding的技术来扩展性能。下图各种配置是统计性能(默认100个routes)
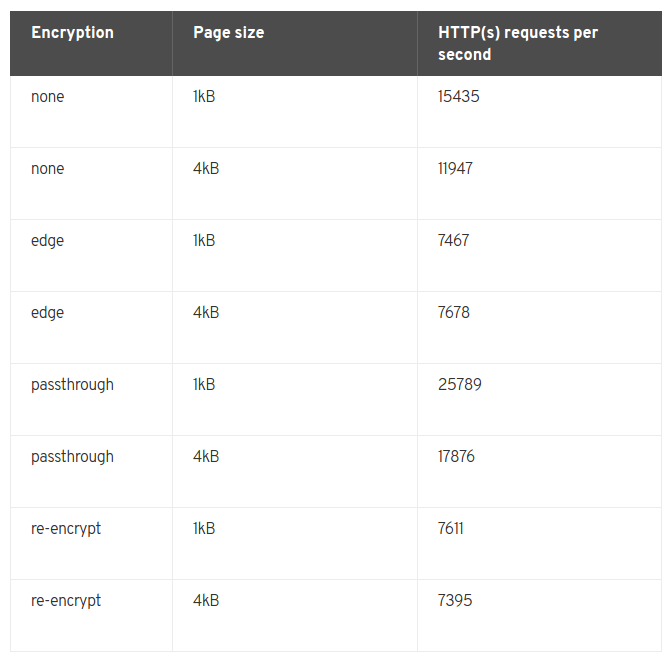
网络优化
默认openshift提供了一个基于ovs的sdn方案,其中涉及到了vxlan, OpenFlow和iptables,当然这些相关的优化项社区已经有很成熟的优化点和方法了,比如增大MTU,UDP-offload,多路复用等等,
这里重点说下vxlan, 基于二层网络,vxlan从4096提升到了16百万多个,vxlan就是把原报文封装进UDP报文,以提供所有pods间通信的能力,自然这样会增加cpu解封包的开销,具体网络吞吐取决于cpu的性能,另外还会额外增加延时响应。
直白的说,现在云主机或物理机的cpu都可以打满千兆网卡,如果是万兆网卡,那vxlan网络的吞吐带宽会卡在CPU上,这是所有overlay网络的现状。
如果你的主机用用万兆或者40Gbps, 那就要考虑网络的性能优化了:
- 通过直接路由,负责pod间通信,不过需要手动维护node节点添加删除时的路由变化。
- 条件允许的话,可以考虑BGP的calico网络方案
- 另外就是购置支持udp-offload的网卡
值得注意点是,及时使用了udp-offload的网卡,和非overlay网络比,延迟是不会减少的,只是减少了cpu开销,从而提高了带宽吞吐。
子网大小
现在openshift-ansible项目默认的安装出来的配置是:
- 集群里内最多1024个节点
- 每个节点最多可以跑510个pods
- 支持65,536个service
比如我要搞一个8192个节点的集群,每个节点允许510个pods运行:
[OSE3:vars]
osm_cluster_network_cidr=10.128.0.0/10
监控
都知道k8s里的弹性伸缩,依赖于Heapster, 而openshift内置的监控系统又是用的自家的Haw系列,导致监控镜像相当的大
在opneshift里有两点要提的是METRICS_RESOLUTION和METRICS_DURATION变量,前者是默认是30s,指的是监控时间间隔,后者默认是7天,指的是监控数据保留时长(过期就会删掉)。
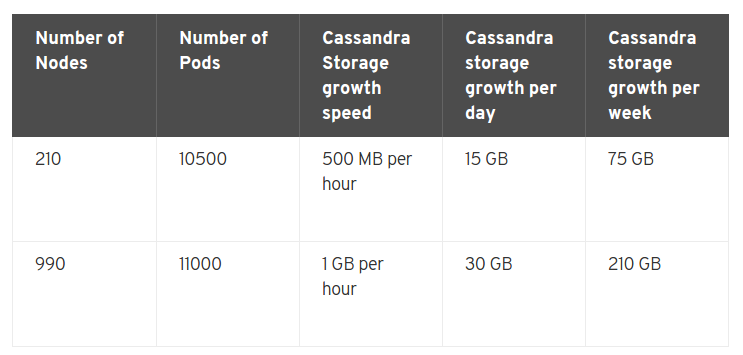
默认的监控体系(Cassandra/Hawkular/Heapster)可以监控25000个pods。
总结
其实openshift基于k8s提供了一站式解决方案, 如果公司不具备k8s二次开发能力,openshift足矣。
4.3.10 - 网络整理
介绍利用openshift-ansible项目安装后的生产环境里的网络情况。
待整理。。。
4.3.11 - 监控梳理
未完搞 ...
4.3.12 - 日志分析
未完搞 ...
4.4 - Kubersphere
主要记录介绍对kubersphere的架构认知和储备二次开发所必备的知识。
本系列文章中会把kubesphere简说成KCP(Qingcloud kubernetes controller-manage platform)
4.4.1 - 使用kind本地启动多集群
我本地4c/8G的小本儿,跑了两个集群,组建了多集群环境,还行,能玩动...
环境篇
-
kind安装
-
镜像准备
视网络情况,可以把依赖镜像
kindest/node提起pull到本地 -
docker的data-root目录
尽量不要放到/var目录下,kind起的集群容器会占用比较大的空间
实操
- 创建集群
执行完如下命令后,docker ps可以看到本地启动了两个容器,一个容器对应一个集群。
kind create cluster --image kindest/node:v1.19.16 --name host
kind create cluster --image kindest/node:v1.19.16 --name member
kubectl config use-context [kind-host | kind-member],可以切换kubecl执行的上下文
- 安装kubesphere
分别在两个集群各自安装ks组件
# 集群1安装
kubectl config use-context kind-host
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/cluster-configuration.yaml
# 集群2安装
kubectl config use-context kind-member
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/cluster-configuration.yaml
- 纳管集群
可以在上面的初始化阶段直接改好主和成员集群的关系,这里参考官文即可
host集群的UI地址,可以通过host容器IP:30880来访问,主集群的容器ip,可以如下获取:
docker inspect --format '{{ .NetworkSettings.Networks.kind.IPAddress }}' host-control-plane
实操添加集群时,需要member集群的kubeconfig,可以用如下命令获取到
kind get kubeconfig --name member
记得把kubeconfig中的server地址中改成member容器ip:6443,这样host集群才能访问到member集群
总结
验证功能、测试开发,挺方便的,可以视本地资源紧张情况停掉监控的ns。
现在kind启动的集群默认使用了containerd的runtime,若想进一步调试查看集群内的情况,可以内部集成的crictl代替熟悉的docker工具。
4.4.2 - 论Kubesphere的异地多活方案
遇到这样一个场景,在同一套环境中需要存在多个host控制面集群...bulabula... 因此想探索下kubesphere的异地多活混合容器云管理方案
集群角色介绍
一个兼容原生的k8s集群,可通过ks-installer来初始化完成安装,成为一个QKE集群。QKE集群分为多种角色,默认是none角色(standalone模式),开启多集群功能时,可以设置为host或者member角色。
- none角色,是最小化安装的默认模式,会安装必要的ks-apiserver, ks-controller-manager, ks-console和其他组件
- ks-apiserver, kcp的API网关,包含审计、认证、权限校验等功能
- ks-controller, 各类自定义crd的控制器和平台管理逻辑的实现
- ks-console, 前端界面UI
- ks-installer, 初始化安装和变更QKE集群的工具,由shell-operator触发ansible-playbooks来工作。
- member角色,承载工作负载的业务集群,和none模式的组件安装情况一致
- host角色,整个混合云管理平台的控制面,会在none的基础上,再额外安装tower,kubefed-controller-manager, kubefed-admission-webhook等组件
- tower,代理业务集群通信的server端,常用于不能直连member集群api-server的情况
- kubefed-controller-manager,社区的kubefed联邦资源的控制器
- kubefed-admission-webhook, 社区的kubefed联邦资源的动态准入校验器
多集群管理原理
上段提到QKE有3种角色,可通过修改cc配置文件的clusterRole来使能, ks-installer监听到配置变化的事件,会初始化对应集群角色的功能。
kubectl edit cc ks-installer -n kubesphere-system
角色不要改来改去,会出现莫名问题,主要是背后ansible维护的逻辑有疏漏,没闭环
host集群
host角色的主集群会被创建25种联邦资源类型Kind,如下命令可查看,还会额外安装kubefed stack组件。
➜ kubectl get FederatedTypeConfig -A
此外api-server被重启后,会根据配置内容的变化,做两件事,注册多集群相关的路由和缓存同步部分联邦资源。
- 添加url里包含
clusters/{cluster}路径的agent路由和转发的功能,要访问业务集群的信息,这样可以直接转发过去。 - cacheSync,缓存同步联邦资源,这里是个同步的操作。
当开启多集群后,如果某个member出现异常导致不可通信,那host的api-server此时遇到故障要重启,会卡在cacheSync这一步,导致无法启动,进而整个平台无法访问。
controller-manager被重启后,同样会根据配置的变化,把部分资源类型自动转化成联邦资源的逻辑,也就是说,在host集群创建的这部分资源会自动同步到所有成员集群,实际的多集群同步靠kubefed-controller-manager来执行。以下资源会被自动创建联邦资源下发:
- users.iam.kubesphere.io -> federatedusers.types.kubefed.io
- workspacetemplates.tenant.kubesphere.io -> federatedworkspaces.types.kubefed.io
- workspaceroles.iam.kubesphere.io -> federatedworkspaceroles.types.kubefed.io
- workspacerolebindings.iam.kubesphere.io -> federatedworkspacerolebindings.types.kubefed.io
此外还会启动cluster、group和一些globalRole*相关资源的控制器逻辑,同上也会通过kubefed自动下发到所有集群,clusters.cluster.kubesphere.io资源除外。
如果以上资源包含了
kubefed.io/managed: false标签,kubefed就不会再做下发同步,而host集群下发完以上资源后,都会自动加上该标签,防止进入死循环
member集群
修改为member集群时,需要cc中的jwtSecret与host集群的保持一致(若该值为空的话,ks-installer默认会随机生成),提取host集群的该值时,需要去cm里找,如下:
kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret
jwtSecret要保持一致,主要是为了在host集群签发的用户token,在用户访问业务集群时token校验能通过。
添加集群
本文只关注直接连接这种情况,当填好成员集群的kubeconfig信息,点击添加集群后,会做如下校验:
- 通过kubeconfig信息先校验下是否会添加已存在的重复集群
- 校验成员集群的网络连通性
- 校验成员集群是否安装了ks-apiserver
- 校验成员集群的
jwtSecret是否和主集群的一致
写稿时,此处有个问题,需要修复,如果kubeconfig使用了
insecure-skip-tls-verify: true会导致该集群添加失败,经定位主要是kubefed 空指针panic了,后续有时间我会去fix一下,已提issue。
校验完必要信息后,就执行实质动作joinFederation加入联邦,kubesphere多集群纳管,实质上是先组成联邦集群:
- 在成员集群创建ns kube-federation-system
- 在上面的命名空间中创建serviceAccount [clusterName]-kubesphere, 并绑定最高权限
- 在主集群的kube-federation-system的命名空间创建
kubefedclusters.core.kubefed.io,由kubefed stack驱动联邦的建立 - 加入联邦后,主集群的联邦资源会通过kubefed stack同步过去
上述一顿操作,等效于
kubefedctl join member-cluster --cluster-context member-cluster --host-cluster-context host-cluster
异地多活方案设计
异地多活的方案主要是多个主集群能同时存在,且保证数据双向同步,经过上面的原理分析,可知多个主集群是可以同时存在的,也就是一个成员集群可以和多个主集群组成联邦。整体方案示意图设计如下:
以下操作假设本地已具备三个QKE集群,如果不具备的可按照此处快速搭建
host、host2、member3个集群
大致实现逻辑的前提介绍:
- 三个集群的
jwtSecret得保持一致 - 两个主集群都去
添加纳管同一个member集群 - 利用
etcdctl make-mirror实现双向同步
验证下可行性
实操双活前,先验证下可行性
实验1:
在两边创建一个同名用户,用户所有信息一致,可以添加成功,然后再修改一边的用户信息,使两边不一致
可以看到member集群的用户xxp,一直会被两边不断的更新...
root@member-control-plane:/# kubectl get user xxp -w
NAME EMAIL STATUS
xxp xxp@163.com Active
xxp xxp-2@163.com Active
xxp xxp@163.com Active
xxp xxp-2@163.com Active
... 周而复始 ...
这个实验,即使在创建用户时,页面表单上两边信息填的都一样,也会出现互相刷新覆盖的情况,因为yaml里的uid和time信息不一致
实验2:
在两边添加一个同名用户,但两边用户信息(用户角色)不一致,可以创建成功,但后创建者的kube-federa会同步失败, 到这里还能接受,毕竟有冲突直接就同步失败了
但member集群上该用户的关联角色会出现上文的情况,被两边的主集群持续反复地修改...
实验3:
在一侧的主集群上尝试修复冲突资源,即删除有冲突的用户资源,可以删除成功,但对应的联邦资源会出现删失败的情况
➜ ~ kubectl get users.iam.kubesphere.io
NAME EMAIL STATUS
admin admin@kubesphere.io Active
xxp3 xxp3@163.com Active
➜ ~
➜ ~ kubectl get federatedusers.types.kubefed.io
NAME AGE
admin 5h33m
xxp 65m #这里是个删不掉的资源,fed controller会重复做失败尝试
xxp3 61m
这样就会出现,两个主集群:一个要删,一个要同步,member集群上:持续上演“一会儿消失,一会儿又出现了”的奇观。
总结
两个主集群可以同时工作,一旦出现同名冲突资源,处理起来会非常麻烦,尤其是背后的Dependent附属资源出现冲突时,往往问题点隐藏的更深,修复起来也棘手...
后来调研也发现:目前的社区方案make-mirror只支持单向同步,适合用来做灾备方案。
所以容器云平台的双活,除非具备跨AZ的etcd集群,否则需要二次开发改造类make-mirror方案来支持了。我最开始要考虑的问题答案也就显而易见了:如果要多个host集群共存,必须考虑通过行政管理手段,来尽量避免同名资源冲突。
4.4.3 - 搭建kubesphere的开发调试环境
依赖工具介绍
- vscode,个人日常使用vscode开发,标配
Remote Development插件 - kt-connect,本地开发使用的流量代理工具,可以双向代理,本地可以直接访问pod和svc,也可以转发访问pod的流量到本地,相关原理介绍。
准备调试环境
连接集群网络
使用kt-connect,打通网络,本地可直接访问Kubernetes集群内网
sudo ktctl connect --context kind-host --portForwardTimeout 300
ktctl采用本地kubectl工具的集群配置,默认为~/.kube/config文件中配置的集群。- 如果kubeconfig有多个集群,可以通过
--context指定要连接的具体集群 - 如果本地环境是
kind集群,需要修改kubeconfig中server的127地址为容器IP:6443 - 如果网络比较差,会遇到错误
ERR Exit: pod kt-rectifier-tcxjk failed to start,可适当增加等待时间portForwardTimeout
另外注意的是,kt-connect需要root权限,上条命令会默认读取
/root/.kube/config文件,自行copy或者另通过-c指定文件
clone代码
不表.
编辑调试的配置文件
首先编辑vscode的调试配置文件, 我是如下配置的:
➜ kubesphere git:(master) cat .vscode/launch.json
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "ks-apiserver",
"type": "go",
"request": "launch",
"mode": "auto",
"program": "${workspaceFolder}/cmd/ks-apiserver/apiserver.go"
},
{
"name": "controller-manager",
"type": "go",
"request": "launch",
"mode": "auto",
"program": "${workspaceFolder}/cmd/controller-manager/controller-manager.go"
}
]
}
准备调试环境
按F5,启动调试,左上角选择要调试的组件,我这里以controller-manager举例(需要hack的注意点比较多)。
过会儿会发现出现错误,错误提示很明显,因缺少配置文件,导致无法启动,通过查看deployment yaml, 发现后面还会缺失Admission Webhooks的证书,可如下统一提取到本地:
# 提取启动的配置文件(调试apiserver的时候也需要这一步,但要把文件放到对应cmd/ks-apiserver目录下)
kubectl -n kubesphere-system get cm kubesphere-config -ojsonpath='{.data.kubesphere\.yaml}' > cmd/controller-manager/kubesphere.yaml
# 提取webhook用到的证书
mkdir -p /tmp/k8s-webhook-server/serving-certs/
export controller_pod=`kubectl -n kubesphere-system get pods -l app=ks-controller-manager -o jsonpath='{.items[0].metadata.name}'`
kubectl -n kubesphere-system exec -it ${controller_pod} -- cat /tmp/k8s-webhook-server/serving-certs/ca.crt > /tmp/k8s-webhook-server/serving-certs/ca.crt
kubectl -n kubesphere-system exec -it ${controller_pod} -- cat /tmp/k8s-webhook-server/serving-certs/tls.crt > /tmp/k8s-webhook-server/serving-certs/tls.crt
kubectl -n kubesphere-system exec -it ${controller_pod} -- cat /tmp/k8s-webhook-server/serving-certs/tls.key > /tmp/k8s-webhook-server/serving-certs/tls.key
继续启动,发现还会有缺文件的错误,应该是编译镜像时,内置了些文件,通过查看build/ks-controller-manager/Dockerfile,发现后面会缺的东西还是比较多的,推荐直接从运行中的pod直接copy到本地:
sudo mkdir /var/helm-charts/
sudo chmod -R a+rw /var/helm-charts
kubectl -n kubesphere-system cp ${controller_pod}:/var/helm-charts /var/helm-charts/
继续启动,成功 !
开始调试
利用ktctl替换集群中的ks-controller-manager的服务为本地服务。
sudo ktctl exchange ks-controller-manager --namespace kubesphere-system --mode scale --recoverWaitTime 300 --expose 8443:8443
如果本地集群只有一个节点,上述命令会一直pending,可以通过如下命令替代
sudo ktctl exchange ks-controller-manager --namespace kubesphere-system --expose 8443:8443 kubectl -n kubesphere-system scale deployment ks-controller-manager --replicas=0结束调试,记得还原刚才缩容
replicas的设置。
后续就是vscode的正常断点调试或者本地开发验证了,有时间在整理贴图...
4.5 - KVM和Libvirt的实践整理
介绍
此前一直用Virtualbox操作虚机的东西,对于个人搭建环境还是显的有些笨重,不能实现Iac的目标,故尝试了Vagrant和Libvirt,综合考虑我选择libvirt继续深入下去,也是希望以后有机会可以深入搞下openstack的nova组件。
安装必要依赖
sudo apt install bridge-utils qemu-kvm virtinst -y
- qemu-kvm: 这个负责hypervisor层和仿真器(可以模拟x86, arm体系).
- virtinst: 安装和管理虚机的命令行工具
- bridge-utils: 创建和管理bridge网络
安装完输入kvm-ok查看是否安装OK,另外还需要重启以使kvm和libvirt daemon启动。
配置网络
未完。。。
4.6 - Vagrant实践整理
很早就听说vagrant的大名,是个创建和管理虚机环境的工具,但一直没有机会实践下,近日我的VirtuablBox让我搞砸了,决定试用下,便于快速搭建各种环境。
安装vagrant
图省事儿的话,直接sudo apt install vagrant就可以安装,不过版本有点儿低,是1.8.1。
通过官方下载地址, 可直接下载最新的安装包。我这里安装的是1.9.4
➜ ~ vagrant -v
Vagrant 1.9.4
常用命令
一个打包好的操作系统在Vagrant中称为Box,即Box是一个打包好的操作系统环境,网上有很多打包好的环境,官方也有下载各种Boxes的地址
一般使用流程如下:
- vagrant box add 添加box的操作
- vagrant init 初始化box的操作
- vagrant up 启动虚拟机的操作
- vagrant ssh 登录虚拟机的操作
额外还有些常用的命令
- vagrant box list 显示当前已经添加的box列表
- vagrant box remove 删除相应的box
- vagrant halt -f 冷关机(切断电源)
- vagrant suspend 挂起当前的虚拟机
实践
目前vagrant 1.9.4支持适配VirtualBox, VMware,Hyper-V, 和 Docker,本文使用的是VirtualBox。
需要你本机已经安装virtuablbox环境
一般只要如下初始化,就会有个最新的centos-7虚机环境
➜ vagrant init centos/7
A `Vagrantfile` has been placed in this directory. You are now
ready to `vagrant up` your first virtual environment! Please read
the comments in the Vagrantfile as well as documentation on
`vagrantup.com` for more information on using Vagrant.
➜ ls
Vagrantfile
➜ vagrant up --provider virtualbox
Bringing machine 'default' up with 'virtualbox' provider...
==> default: Box 'centos/7' could not be found. Attempting to find and install...
default: Box Provider: virtualbox
default: Box Version: >= 0
==> default: Loading metadata for box 'centos/7'
default: URL: https://atlas.hashicorp.com/centos/7
==> default: Adding box 'centos/7' (v1704.01) for provider: virtualbox
default: Downloading: https://atlas.hashicorp.com/centos/boxes/7/versions/1704.01/providers/virtualbox.box
default: Progress: 2% (Rate: 94086/s, Estimated time remaining: 1:52:14)
但如上需要依赖外网, 国内环境一般会下载失败,我这里介绍一种通过本地iso创建Box的方法,然后通过本地Box启动虚机环境。
这个iso转box的方法需要Packer工具,此工具同样和vagrant都是HashiCorp公司出品的,目前国外很火的工具,
支持创建各式各样的镜像,包括各种国内外主流的公有云, openstack的镜像,甚至docker镜像都是可以OK的。
参考
4.7 - 解读Consul
概述
介绍现在的Consul前,有必要先介绍下Service Mesh的概念,
Service Mesh
Service Mesh是一种面向服务间安全通信的基础设施层,俗称代理服务的东西向流量。 典型的实现包含控制面板和数据面。
- 控制面:跟踪记录所有的服务和访问地址,提供服务发现、健康检查、策略管理等。
- 数据面:通过sidcar机制代理服务间的通信。
传统 vs 微服务优势 :
- 单体 -> 微服务架构
- 函数调用 -> 服务发现(熔断、健康检查)
- 配置文件 -> 配置中心
- 防火墙 -> 访问策略
- DMZ、生产区 -> 零信任
Consul
Consul是Service mesh中的控制面的实现,主要有一下几大特色:
- 服务发现:分为注册服务、发现服务、健康检查三大功能。
- K-V存储:BoltDB,支持 ACID 事务、无锁并发事务 MVCC,提供 B+Tree 索引。
- 多数据中心:多中心Gossip数据同步
- Servie Mesh: 利用sidecar机制实现了端到端的认证和加密通信
部署架构
下图为经典的多中心consul集群配置。
- 每个datacenter,都有N个Server和M个Client节点。因为网络延迟对Consul分布式一致性的性能影响,会出现节点越多,共识越慢的现象,server节点一般推荐为3~5个,但client节点没有限制。
- Client主要充当DNS server、负载均衡和健康检查的作用。
- Server实现数据的分布式存储一致性,一般用来存储节点状态、注册的服务信息、应用配置、通信策略等。
- Consul在选主和数据事务中都使用了Raft算法,但是其WAN(多个数据中心间)、LAN(节点间)通信、故障广播使用了Gossip算法(流行病协议)。
- 在单集群内,Consul server默认的Follower节点收到读写请求后,会转发给Leader处理
- 若查询的服务不在本集群,本地的Leader转发给远程集群的Leader处理。
运维高可用管理
目前分布式系统的高可靠实现,均受限于CAP(一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance))理论,根据不同业务场景的会采取三者之间的平衡取舍。本文的Consul是采用Raft算法来实现的,采用此算法的还有EverDB、RocketDB、Etcd、Kafka3等系统。
Raft算法状态机:
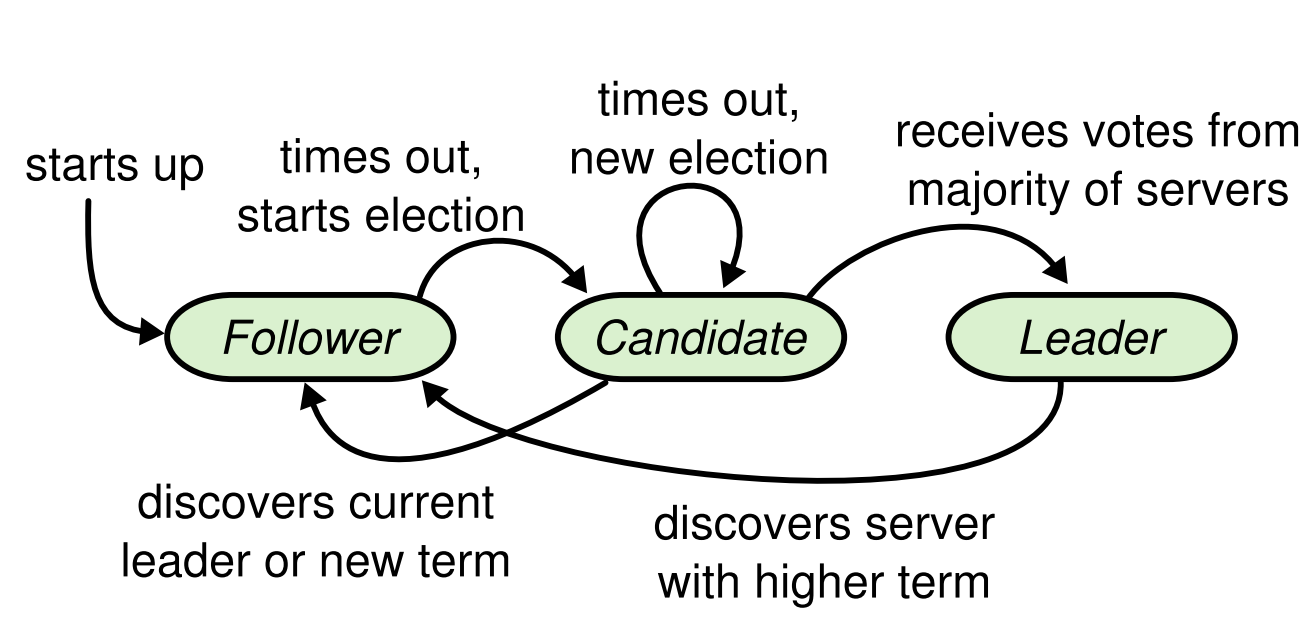
主要有三种状态Follower、Candidate和Leader,其中值得关注有以下几个方面:
- 第一次启动后,默认进入为
Follower,经过随机时间(Election Time)后,进入Candidate状态,发起投票流程。 - 收到大多数节点投票,可以成为
Leader - 非拜占庭环境,每进行一次选举,选举周期Term就回自加1,默认大家都遵从term高的节点
- 选主成功后,Leader会发起心跳保活
- Follower可以根据CAP相性调整,一般是收到请求后转发给Leader处理。
详情可查看动画展示。
从Raft算法原理可以得出,Leader选举和日志同步都只需要大多数的节点正常互联即可,所以少量节点故障或网络异常不会影响系统的可用性。
即使Leader故障,在选举超时后,剩余节点会自发选举新Leader,无需人工干预,RTO时间极小。如果网络发生脑裂,待网络恢复后,也会保证数据最终一致性。
Gossip通信
Gossip是Consul节点间状态同步的,下图为形象表示:
可以理解为一传十、十传百,随机选择几个节点发出消息,收到信息的节点在向其他节点传播,这种方式在数据量大、环境复杂的情况下比一传百更具备可扩展性和可靠性。Consul默认有两个Gossip池,LAN池和WAN池。
LAN池 :Consul中的每个数据中心有一个LAN池,它包含了这个数据中心的所有成员,包括clients和servers。LAN池用于以下几个目的:
- 成员关系信息允许client自动发现server, 免去如何发现server端的配置。
- 分布式失败检测机制使得由整个集群来做失败检测这件事, 而不是集中到几台机器上。
- gossip池使得类似Leader选举这样的事件,可以更可靠、迅速的传达。
WAN池: WAN池是全局唯一的,因为所有的server都应该加入到WAN池中,无论它位于哪个数据中心。由WAN池提供的成员关系信息允许server做一些跨数据中心的请求。一体化的失败检测机制允许Consul优雅地去处理:整个数据中心失去连接, 或者仅仅是别的数据中心的某一台失去了连接。
数据读写一致性
数据写入必须走Leader,经过两阶段提交(propose、prewrite(append、replicate)、commited、apply)过程,详情可以参考这里,读取数据Consul有三个级别可以配置。
- consistent: Leader处理数据前,要和所有节点确认自己还是Leader,每次请求都会额外的网络请求
- default: 引入Leader Lease机制,一定时间窗口内,Learder利用状态缓存,直接处理请求。
- stale: 所有server节点都可以直接回应请求,会产生Follower节点反应过久的数据。
ACL授权
TODO.
client说明:
configmap中的字段: client的配置datacenter、encrypt
-encrypt:和sever段保持一致,可用consul keygen生成,只在启动后加载一次,之后便不需要了,用于加密consul的gossip协议通信。datacenter: 和要接入的server端保持一致,代表consul集群名称。acl.tokens.agent: acl申请的token,代表了该client可以操作服务、配置的权限
deployment的字段:
CONSUL_RETRY_JOIN_ADDR里的值,会填充到join和--retry-join参数中,代表要接入的consul集群,前者加入一次不成功会失败,后者会重复尝试直到成功。CONSUL_NODE_NAME,会填充到-node参数,默认是hostname,要求全局唯一,此处代表要接入注册中心的系统的名字。AGENT_TOKEN:acl里申请的token
server说明:
4.8 - 解读Kafka
5 - 区块链
存放些曾经在区块链界战斗过的痕迹。
5.1 - 什么是以太坊
目录
- 什么是以太坊
- 应用场景
- 趋势展望
内容
1.什么是以太坊
以太坊是一个全新开放的区块链平台,它允许任何人在平台中建立和使用通过区块链技术运行的去中心化应用。
1.1. 从名字说起
以太坊 == ethereum,
Ether,物理学里面有个以太,绝对静止的存在于空间的那种物质,尚未证明是否真实存在,在某领域里,它被称为虚空,空间…是一种能承载万物的东西,是一种目前还难以解释和观察的东西。
至于这个“坊”字,也不知道是谁先翻译叫起来的,反正现在大家都这么叫。
1.2 从功能说起
以太是区块链网络里很重要的元素 -- 燃料 -- 以太币,为计算付费。
1. 开发人员发布Dapp
2. 用户和Dapp交互
3. 挖矿得到报酬(维持网络稳定的)
4. 金融交易
1.3 从产出
- 2014年9月份预售阶段发了6千万以太币,(募集到 31,531 个比特币)
- 其中20%用于以太基金的运作,主要是给开发人员发工资。
- 挖矿,大概每15秒左右出一个块,作为报酬,出块的人可以得到5个以太
- 打包叔块的人会得到2-3个以太
自从Byzantium update升级后,现在挖矿和挖到叔块的人会分别得到3和0.625-2.625个以太。
1.4 FAQ
1.4.1 以太比会无限发行么?
不会, 当时预售的时候规定,每年的发行量是1800万上限(被挖到),计划在17年底,会切换共识算法从POW到Casper上,之后出块效率更高,需要的挖矿补贴更少, 具体发行多少,现在还未定。
1.4.2 以太币和比特币的对比?
如果后者,以太币是不可能实现的,在整个数字生态是互补关系,Ether应被视为“加密燃料”,其目的是为计算付费,而不是用作或被视为货币,资产,份额或其他任何东西。

技术层面的对比
1.2 账户
以太坊有两种类型的账户:
- 外部账户(由私钥控制的)
- 合约账户(由合约代码控制)。
另种账户都可以发起交易,后者被动发送。
外部所有的账户没有代码,人们可以通过创建和签名一笔交易从一个外部账户发送消息。每当合约账户收到一条消息,合约内部的代码就会被激活,允许它对内部存储进行读取和写入,和发送其它消息或者创建合约。
UTXOs的好处有: 更加私密(用户要是每笔交易都换一个地址,那么就很难找到其中两个地址的相关性);潜在的可扩展性。
账户的好处: 节省大量空间(每笔交易只有一个输入、一个输出、一个签名);更大的可替代性;简单(编码简单,不需要更为复杂脚本);
1.3 以太坊虚拟机EVM
1.4 挖矿
1.5 网络
目前有主链和测试链之分,测试网已经运行到3代了
测试链的区别:

主链:

- 应用场景
-
金融服务:主要是降低交易成本,减少跨组织交易风险等。该领域的区块链应用将最快 成熟起来,银行和金融交易机构将是主力推动者。
-
征信和权属管理:这是大型社交平台和保险公司都梦寐以求的,目前还缺乏足够的数据 来源、可靠的平台支持和有效的数据分析和管理。该领域创业的门槛极高,需要自上而 下的推动。
-
资源共享:airbnb 为代表的公司将欢迎这类应用,极大降低管理成本。这个领域创业门 槛低,主题集中,会受到投资热捧。
-
投资管理:无论公募还是私募基金,都可以应用区块链技术降低管理成本和管控风险。 虽然有 DAO 这样的试水,谨慎认为该领域的需求还未成熟。
-
物联网与供应链:物联网是很适合的一个领域,短期内会有大量应用出现,特别是租 赁、物流等特定场景。但物联网自身的发展局限将导致短期内较难出现规模应用。
- 趋势展望
一个是 技术领域也存在着周期律。这个周期目前看是7-8 年左右。或许正如人有“七年之 痒”,技术也存在着七年这道坎,到了这道坎,要么自身突破迈过去,要么往往就被新的技术 所取代。如果从比特币网络上线(2009 年1月)算起,到今年正是在坎上。因此,现在正是 相关技术进行突破的好时机。
为何恰好是7年? 7年按照产品周期来看基本是2-3个产品周期,所谓事不过三,经过2-3 个产品周期也差不多该有个结论了。
另外,最早出现的未必是先驱,也可能是先烈。创新固然很好,但过早播撒的种子,没有合 适的土壤,往往也难长大。技术创新与科研创新很不同的一点便是,技术创新必须立足于需 求,过早过晚都会错失良机。科研创新则要越早越好,最好像二十世纪那批物理巨匠们一 样,让后人吃了一百多年的老本。
最后,事物的发展往往是延续的、长期的。 新生事物大都不是凭空蹦出来的,往往是解决了 前辈未能解决的问题,或是出现了之前未曾出现过的场景。而且很多时候,新生事物会在历 史的舞台下面进行长期的演化,只要是往提高生产力的正确方向,迟早会出现在舞台上的一 天。

QA ?
5.2 - 搭建以太坊私链网络
大量过时文章充斥于网络,本文基于官方go-tehereum 1.6.7版本整理而出,在geth1.6之后引入了一个puppeth工具,它就是用来初始一个私链创世块配置的。
准备工具环境
下载go-ethereum代码(go的开发环境准备,不在此文范围)
# 下载源码
go get github.com/ethereum/go-ethereum
cd $GOPATH/src/github.com/ethereum/go-ethereum
# 编译1.6.7版本的代码
git checkout -b v1.6.7 v1.6.7
make all
# 安装
sudo ln -s $PWD/build/bin/* /usr/local/bin/
# 检查是否安装OK
geth version
Geth
Version: 1.6.7-stable
Git Commit: ab5646c532292b51e319f290afccf6a44f874372
Architecture: amd64
Protocol Versions: [63 62]
Network Id: 1
Go Version: go1.8.3
Operating System: linux
GOPATH=/home/xxp/go
GOROOT=/home/xxp/Software/go
生成私链创世块的配置
- 创建账户
# 创建testnet目录
➜ mkdir testnet && cd testnet
# 创建3个普通账户,密码自定
➜ geth --datadir node0 account new
# 把密码记录到文件里,后面会频繁输入
➜ echo node0 > node0/password
➜ geth --datadir node1 account new
➜ echo node1 > node1/password
➜ geth --datadir node2 account new
➜ echo node2 > node2/password
如上打印的一串16进制的字符串就代表账户的userID(理解成网络中的IP地址),后面puppeth需要用到。
- 生成genesis文件
genesis文件定义了私链的第一个块生成,直接看操作吧(省略了些输出)
➜ testnet puppeth
Please specify a network name to administer (no spaces, please)
> testnet
Sweet, you can set this via --network=testnet next time!
INFO [08-21|23:04:14] Administering Ethereum network name=testnet
WARN [08-21|23:04:14] No previous configurations found path=/home/xxp/.puppeth/testnet
What would you like to do? (default = stats)
1. Show network stats
2. Configure new genesis
3. Track new remote server
4. Deploy network components
> 2
Which consensus engine to use? (default = clique)
1. Ethash - proof-of-work
2. Clique - proof-of-authority
> 2
# 设置5秒出一个块
How many seconds should blocks take? (default = 15)
> 5
# 输入有签名权限的账户
Which accounts are allowed to seal? (mandatory at least one)
> 0x799a8f7796d1d20b8198a587caaf545cdde5de13
> 0x1458eac314d8fc922029095fae20483f55726017
> 0x3ca60eb49314d867ab75a3c7b3a5aa61c3d6ef71
> 0x
# 输入有预留余额的账户
Which accounts should be pre-funded? (advisable at least one)
> 0x799a8f7796d1d20b8198a587caaf545cdde5de13
> 0x1458eac314d8fc922029095fae20483f55726017
> 0x3ca60eb49314d867ab75a3c7b3a5aa61c3d6ef71
> 0x
Specify your chain/network ID if you want an explicit one (default = random)
> 378
Anything fun to embed into the genesis block? (max 32 bytes)
>
What would you like to do? (default = stats)
1. Show network stats
2. Save existing genesis
3. Track new remote server
4. Deploy network components
> 2
Which file to save the genesis into? (default = testnet.json)
> genesis.json
INFO [08-21|23:05:36] Exported existing genesis block
最后会在当前目录生成genesis.json文件。
启动私链网络
这里通过单机不同端口模拟多节点,
- 默认geth一启动就会发出discovery,以发现其他节点,源码里内置了几个初始节点,可以通过--bootnode参数重置。如果真要不同节点互组网络的话,还需要主要时间同步,
- 还可以通过--nodiscover参数,停掉自动发现,并利用admin.addPeer()或者static-node功能组成网络。
# 启动节点0, 关闭自动发现(防止不希望的节点进入)
geth --datadir node0 init genesis.json
geth --datadir node0 --port 30000 --nodiscover --unlock '0' --password ./node0/password console
# 不加console的话,可以通过geth attach ipc:node0/geth.ipc来访问
# 启动节点1,另起一个终端,通过不同端口模拟
geth --datadir node1 init genesis.json
geth --datadir node1 --port 30001 --nodiscover --unlock '0' --password ./node1/password console
# 启动节点2,genesis.json里已经指定networkID,启动时无需指定了
geth --datadir node2 init genesis.json
geth --datadir node2 --port 30002 --nodiscover --unlock '0' --password ./node2/password console
目前启动了三个节点,但都默认关闭了发现功能,需要手动添加peer节点。
在每个console输入admin.nodeInfo.enode, 把输出记录下来到static-nodes.json文件,我这里情况如下:
➜ testnet cat node0/static-nodes.json
[
"enode://2ffb53ede7de8dabf8f12343a7b2aba6b09263a53d8db5b4669309c5913f72969ce469cf09299f13e9d6cba8a98e18ad43811439326d7152f21d2e03ddc6be17@[::]:30000?discport=0",
"enode://910d1bfcd763bb5157bc62f8b121eb21fb305d17e4e4437c0b094d3d6f2d72f1964b80eb8fa2cf6cd7d4cc2d44cfc1ed9b74275ea7fd42ab89b4d089023fb7d5@[::]:30001?discport=0",
"enode://acab97a2a287b740b5efc3af465ba7330b3d4948b05e26818822d1aee659ec1b8f54ee9501576dc08ea4021d7ede01431691a27310a7dcbda2437bcd3b9c451d@[::]:30002?discport=0"
]
把static-nodes.json文件放入各自(node0/,node1/, node2/)的admin.datadir目录下,并Ctrl+D终止掉console,并重新执行geth --datadir <dir> --prot <port> --nodiscover console,如果觉得这样麻烦的话,或者以后动态添加节点时候,可考虑在每个节点的console里输入admin.addPeer("nodeInfo_encode")来完成。
然后在console中可以如下验证,是否互相发现组成以太坊私链网络了
# 这样可看到其他节点的明细
> admin.peers
[{
caps: ["eth/63"],
id: "910d1bfcd763bb5157bc62f8b121eb21fb305d17e4e4437c0b094d3d6f2d72f1964b80eb8fa2cf6cd7d4cc2d44cfc1ed9b74275ea7fd42ab89b4d089023fb7d5",
name: "Geth/v1.6.7-stable-ab5646c5/linux-amd64/go1.8.3",
network: {
localAddress: "[::1]:43928",
remoteAddress: "[::1]:30001"
},
protocols: {
eth: {
difficulty: 1,
head: "0xa43519868915a64d3798abf1867b7bc769d1239442c69ff1eca8e3dfcd13209b",
version: 63
}
}
}, {
caps: ["eth/63"],
id: "acab97a2a287b740b5efc3af465ba7330b3d4948b05e26818822d1aee659ec1b8f54ee9501576dc08ea4021d7ede01431691a27310a7dcbda2437bcd3b9c451d",
name: "Geth/v1.6.7-stable-ab5646c5/linux-amd64/go1.8.3",
network: {
localAddress: "[::1]:60310",
remoteAddress: "[::1]:30002"
},
protocols: {
eth: {
difficulty: 1,
head: "0xa43519868915a64d3798abf1867b7bc769d1239442c69ff1eca8e3dfcd13209b",
version: 63
}
}
}]
>
# 可看到此节点发现了另外两个节点
> net.peerCount
2
>
目前整个testnet的目录结构如下
➜ tree
.
├── genesis.json
├── node0
│ ├── geth
│ │ ├── chaindata
│ │ │ ├── 000002.ldb
| | | ├── ...
│ │ ├── lightchaindata
│ │ │ ├── 000001.log
│ │ │ ├── ...
│ │ ├── LOCK
│ │ └── nodekey
│ ├── geth.ipc
│ ├── history
│ ├── keystore
│ │ └── UTC--2017-08-21T15-03-25.499242705Z--799a8f7796d1d20b8198a587caaf545cdde5de13
│ └── static-nodes.json
├── node1
│ ├── geth
│ │ ├── chaindata
│ │ │ ├── 000002.ldb
│ │ │ ├── ...
│ │ │ └── MANIFEST-000007
│ │ ├── lightchaindata
│ │ │ ├── ...
│ │ │ └── MANIFEST-000000
│ │ ├── LOCK
│ │ └── nodekey
│ ├── geth.ipc
│ ├── history
│ ├── keystore
│ │ └── UTC--2017-08-21T15-03-35.020270645Z--1458eac314d8fc922029095fae20483f55726017
│ └── static-nodes.json
└── node2
├── geth
│ ├── chaindata
│ │ ├── 000002.ldb
│ │ ├── ...
│ │ └── MANIFEST-000007
│ ├── lightchaindata
│ │ ├── ...
│ │ └── MANIFEST-000000
│ ├── LOCK
│ └── nodekey
├── geth.ipc
├── history
├── keystore
│ └── UTC--2017-08-21T15-03-46.899273318Z--3ca60eb49314d867ab75a3c7b3a5aa61c3d6ef71
└── static-nodes.json
15 directories, 56 files
开始挖矿
在每个节点的console输入如下,启动挖矿(共识记账):
# 这一步可以不需要,因为我们geth启动的时候,已经传入unlock参数了,因为console里执行unlock是有过期时间机制的,私网直接来。。。。
> personal.unlockAccount(eth.coinbase)
Unlock account 0x799a8f7796d1d20b8198a587caaf545cdde5de13
Passphrase:
true
>
# 这一个很重要,为后面的eth设置了默认账户
> eth.defaultAccount = eth.coinbase
"0x799a8f7796d1d20b8198a587caaf545cdde5de13"
>
> miner.start()
通过钱包交易
通过mist钱包界面,来查看基本信息和进行交易,不过之前需要在console开启RPC, node0的console里如下
> admin.startRPC("127.0.0.1", 8545, "*", "eth,net,web3,admin,personal")
启动的mist钱包
mist --node geth --node-datadir ./node0 --rpc http://localhost:8545
# 不启动rpc的话,也可以如下直接通过ipc通信
# mist --rpc ./node0/geth.ipc --node-networkid 378 --node-datadir ./node0
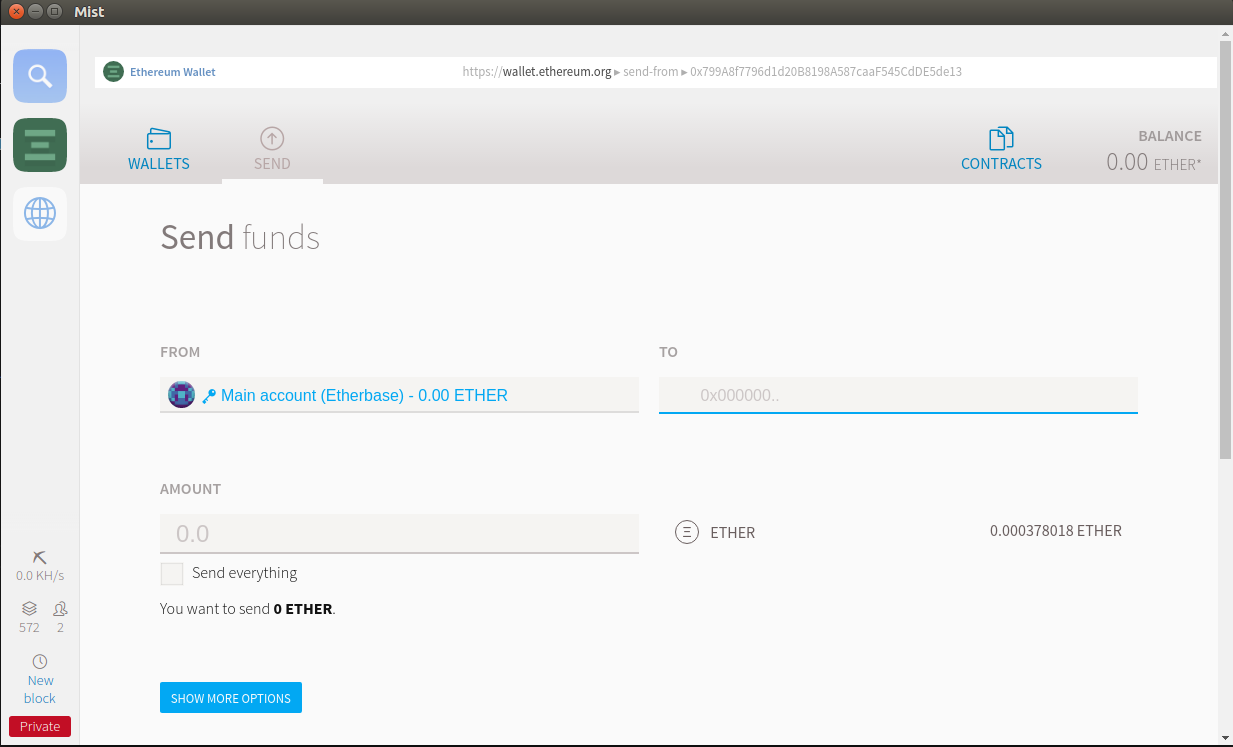
需要去node1上通过eth.accounts[0]拿到账号信息,填入红框,点击发送交易,输入密码即可
![]()
另外也可以通过console命令行来完成上面操作:
>
> var sender = eth.accounts[0]
undefined
> var receiver = "0x1458eac314d8fc922029095fae20483f55726017"
undefined
> var amount = web3.toWei(10, "ether")
undefined
> personal.unlockAccount(eth.accounts[0])
Unlock account 0x799a8f7796d1d20b8198a587caaf545cdde5de13
Passphrase:
true
> eth.sendTransaction({from:sender, to:receiver, value: amount})
"0x97ca1f5fa27df083e14b2ffb82c2a60744aeae0f1a7b5e735ca4d0c05c16f7b6"
>
写个合约
通过mist界面点击的“开发”->"Open Remix IDE", 会自动打开IDE工具,并且默认集成了一个投票的合约,合约内容不表
“create”按钮后面输入 10 -> 点击, 这时候需要输入密码解锁,因为需要支付一定的gas费用。
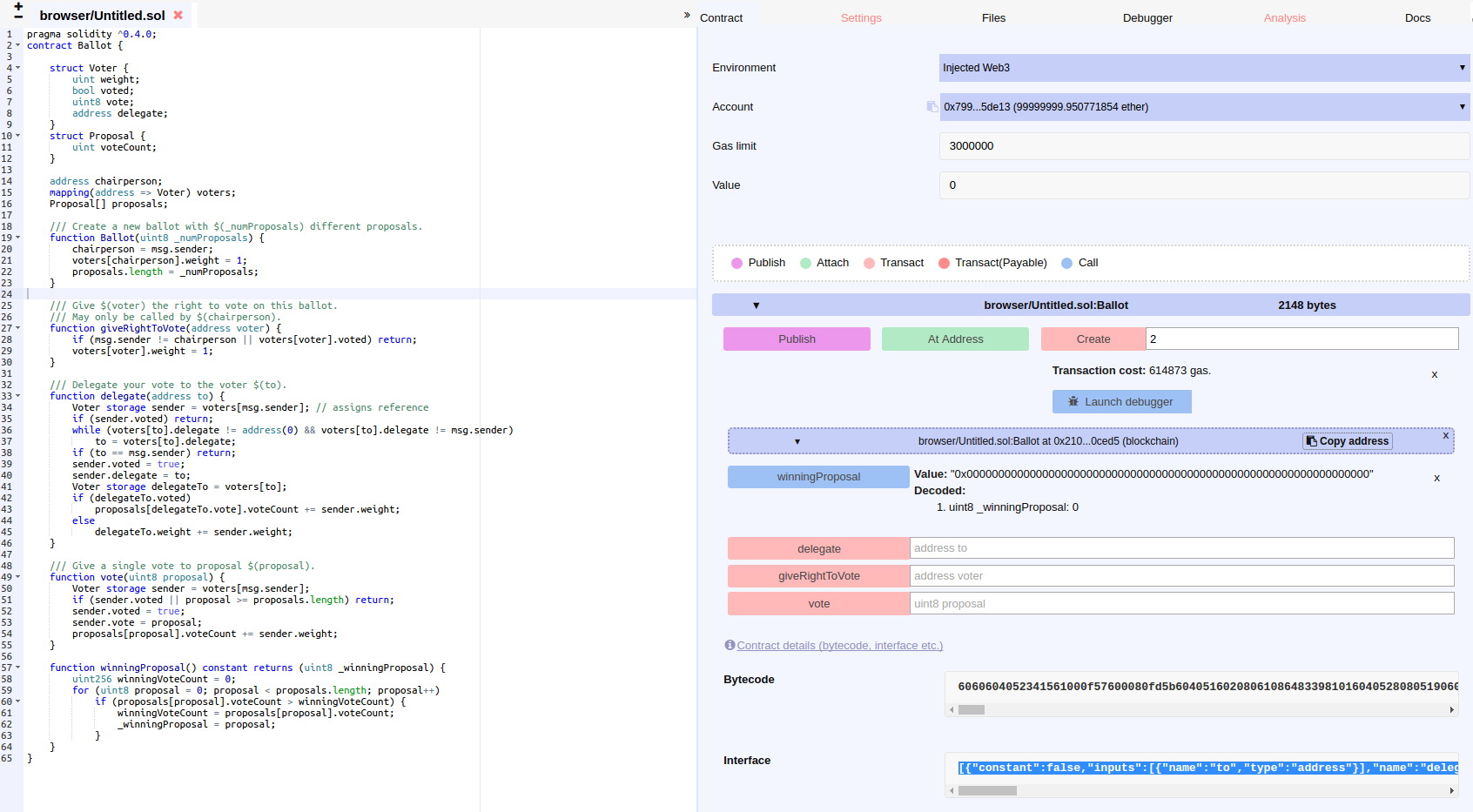
- 这个合约就是个投票程序
- 第一个部署的默认是主席身份,拥有指定别人投票的权利,因为我这里的mist是连接的node0,所以
- 合约初始化(也就是界面点击“create”时),需要输入"投案"个数
在每个节点的的console里,通过eth.contract(ABI).at(Address);拿到合约对象,
- 其中node0的节点需要用
giveRightToVote给其他账户授权投票权限 - ABI的信息,就是remix里Interface框对应的信息
- 合约地址通过
Copy address得到
> var b = eth.contract([{"constant":false,"inputs":[{"name":"to","type":"address"}],"name":"delegate","outputs":[],"payable":false,"type":"function"},{"constant":true,"inputs":[],"name":"winningProposal","outputs":[{"name":"_winningProposal","type":"uint8"}],"payable":false,"type":"function"},{"constant":false,"inputs":[{"name":"voter","type":"address"}],"name":"giveRightToVote","outputs":[],"payable":false,"type":"function"},{"constant":false,"inputs":[{"name":"proposal","type":"uint8"}],"name":"vote","outputs":[],"payable":false,"type":"function"},{"inputs":[{"name":"_numProposals","type":"uint8"}],"payable":false,"type":"constructor"}]).at('0xc825238a3348f0a679924796fcf1b1b64a8c1706')
undefined
> b.vote(9)
"0x1646e6547606a8ad0e183f1c9145eff08bbdfd860961d6c7d7367f5b70779cbd"
>
> b.giveRightToVote('0x1458eac314d8fc922029095fae20483f55726017')
"0x2759928ad03a2ed5bc4b9c54531eb83e25c4a468e71682f67b160ad3328c8173"
>
> b.giveRightToVote('0x3ca60eb49314d867ab75a3c7b3a5aa61c3d6ef71')
"0x46f756e613499f836e392011c8f6d7c23d378fd5a656bae775ecda8bf286c5b6"
> b.winningProposal()
9
其中值得注意的是b.vote(Web3 deploy框的信息也可以直接部署合约。
5.3 - 以太坊的truffle box开发实战
整个过程主要演示chrome扩展 METAMASK, OpenZepplin库和truffle框架的使用。
搭建私连网络
主要参考之前的以太坊-私有链搭建初步实践, 这里只用单节点的网络。
还是先准备账户:
mkdir node0
# 会在node0/keystore目录里生成一个keyfile json文件
geth --datadir node0 account new
#利用puppeth生成genesis.json的过程不表,参考上边的链接
geth --datadir node0 init genesis.json
# 把刚才的账号的密码写入node0/password文件
# 启动私链,顺便开启console
echo node0 > node0/password
geth --datadir node0 --port 30000 --nodiscover --unlock '0' --password ./node0/password --mine --rpc --rpccorsdomain "*" --rpcapi "eth,net,web3,admin,personal" console
我们把这个账号的json文件导入到chorme插件metamask里,便于后面调试和演示
ubuntu系统上的chrome插件会有窗口消失的bug,在URL栏里打开chrome-extension://nkbihfbeogaeaoehlefnkodbefgpgknn/popup.html
truflle初始化项目
需要下载truffle命令号
npm install -g truffle
mkdir token && cd token
# 利用trulle下载token代笔示例
truffle unbox tutorialtoken
npm intall zeppelin-solidity
如上必要的依赖框架和库已经下载到了本地, 接下来就创建自己的代币合约
在contract目录创建TutorialToken.sol文件,内容如下:
pragma solidity ^0.4.11;
import 'zeppelin-solidity/contracts/token/StandardToken.sol';
/**
* @title SimpleToken
* @dev Very simple ERC20 Token example, where all tokens are pre-assigned to the creator.
* Note they can later distribute these tokens as they wish using `transfer` and other
* `StandardToken` functions.
*/
contract TutorialToken is StandardToken {
string public name = "TutorialToken";
string public symbol = "SIM";
uint256 public decimals = 18;
uint256 public INITIAL_SUPPLY = 10000;
/**
* @dev Contructor that gives msg.sender all of existing tokens.
*/
function TutorialToken() {
totalSupply = INITIAL_SUPPLY;
balances[msg.sender] = INITIAL_SUPPLY;
}
}
在以太坊里几乎所有操作都是当做交易来看的,部署合约就是一种交易,交易就要花钱(gas消耗),所以truffle做的是增量部署(少消耗gas),现在在migrations目录添加新的部署文件2_deploy_contracts.js。
var TutorialToken = artifacts.require("./TutorialToken.sol");
module.exports = function(deployer) {
deployer.deploy(TutorialToken);
};
一切准备就绪,编译,部署开始:
# 编译
➜ truffle compile
Compiling ./contracts/Migrations.sol...
Compiling ./contracts/TutorialToken.sol...
Compiling zeppelin-solidity/contracts/math/SafeMath.sol...
Compiling zeppelin-solidity/contracts/token/BasicToken.sol...
Compiling zeppelin-solidity/contracts/token/ERC20.sol...
Compiling zeppelin-solidity/contracts/token/ERC20Basic.sol...
Compiling zeppelin-solidity/contracts/token/StandardToken.sol...
Writing artifacts to ./build/contracts
# 根据truffle.js的配置进行部署
➜ truffle migrate
Using network 'development'.
Running migration: 1_initial_migration.js
Deploying Migrations...
... 0x65ccd2d6a4f4248466dd7887da7a2ac35d18c7ab0ec826cb25580bc785a2c3b8
Migrations: 0xc64569558f90302f4b3884929ac5540c645674dc
Saving successful migration to network...
... 0xf9043ca886d352f05a05642047f63eed11d9b328fb815becc68baffc4d953d60
Saving artifacts...
Running migration: 2_deploy_contracts.js
Deploying TutorialToken...
... 0x19350625474c36316046b103e671eaad45834a60c17a5b9c64cf96316754560f
TutorialToken: 0x7f469dc1ec17c3b7c52a3ad74611cb4b7e6807e1
Saving successful migration to network...
... 0xe57ba56dd5f1b18d410577def8bc7089f7de56e8d8718c3098430995d4b81353
Saving artifacts...
5.4 - fomo3d-上线部署要点
fomo3d游戏一出,国内疯狂clone上线,这里谈下我上线的思路和部署方法(纯手动的^_^,落伍了)
通过原版合约地址,可以一层一层的拔下所有涉及到的合约代码。
目前据我统计共有8个合约,其中有两个闭源合约:
- F3DexternalSettingsInterface
- JIincInterfaceForForwarder
闭源合约不可怕,看明白什么功能,自己hack掉是不影响游戏本身的。
提前预警,合约的内容细节还是要自己研究的,没时间写太细,
其实这个游戏本身只需要2个合约就可以跑起来,且没实质影响,只是单纯改变了部分利益分配方式。
下面说明,我尽可能少改动原版的情况下,部署上线合约,移除p3d修改后的原版合约代码在这里
部署前的准备
我一般使用在线remix工具部署合约在自己的私链上调试,私链建议如下启动(一键解万忧的方式,推荐创世块采用POA共识-不消耗CPU),这样可以使用remix的debug功能
geth \
--datadir ./node0\
--ws\
--wsaddr 0.0.0.0\
--wsapi "eth,net,web3,admin,personal,txpool,miner,clique,debug"\
--wsport 8546\
--wsorigins "*"\
--rpc\
--rpcapi "eth,net,web3,admin,personal,txpool,miner,clique,debug"\
--rpccorsdomain "*"\
--rpcaddr 0.0.0.0\
--rpcport 8545\
--rpcvhosts "*"\
--mine\
--etherbase 0xdbeb69c655b666b3e17b8061df7ea4cc2399df11\
--unlock 0xdbeb69c655b666b3e17b8061df7ea4cc2399df11\
--password ./password\
--nodiscover\
--maxpeers '50'\
--networkid 378\
--targetgaslimit 471238800\
&
部署合约
按先后顺序如下部署
真心不推荐部署带有p3d合约的游戏,这样项目方就可以吃掉本来要流到这里25%左右的流水资金了
我对p3d的合约内容还没有很深的研究,只知道它
- 是一个自带“交易所”、发行总量为0的Token,
- 通过Eth买入会自动增发,卖出会销毁
- 买入和卖出都会扣掉10%的费用给仍持有Token的人
- 每买一次都会使Token升值
- 每卖一次会使Token降价
这个合约不需要改动,贴源码,编译后部署截图如下,点击红色记录下来部署后的合约地址
- 部署divies合约
这个合约专门往p3d持有者发分红的。
把刚才记录的p3d合约地址,替换到HourglassInterface后面的地址。如上贴源码,编译后部署Divies合约,
记录下divies的地址,并替换fomo3dlong.sol里的DiviesInterface地址
部署JIincForwarder合约
这个合约是管理流向社区2%的资金的,被fomo3dlong里调用, 这里需要hack,因为其中涉及到一个闭源的合约,既然知道它是管理2%资金流向的,那直接在fomo3dLong的合约如下hack
- 把定义
Jekyll_Island_Inc的地方,直接定义成一个普通地址address reward = 0xxxxxxx; - 把调用Jekyll_Island_Inc的地方, 写成
reward.transfer(_com);, 注意有两个地方调用(都要换),一个是游戏进行时调用,一个是本轮结束后调用
// // community rewards
// if (!address(Jekyll_Island_Inc).call.value(_com)(bytes4(keccak256("deposit()"))))
// {
// // This ensures Team Just cannot influence the outcome of FoMo3D with
// // bank migrations by breaking outgoing transactions.
// // Something we would never do. But that's not the point.
// // We spent 2000$ in eth re-deploying just to patch this, we hold the
// // highest belief that everything we create should be trustless.
// // Team JUST, The name you shouldn't have to trust.
// _p3d = _p3d.add(_com);
// _com = 0;
// }
reward.transfer(_com);
所以不需要部署这个合约,你只要想办法把流到这里的ETH,流到平台方就可以了。(流到开发者,我觉得也是可以的,哈哈~)
- 部署Team合约
这个合约利用多签技术限制了影响团队的操作,需要改的地方就是把这些地址全部换成自己的,
把下面这些地址,改成你自己的地址,最好把deployer地址写成你用来部署合约的那个地址,后面调用playbook合约的addGame需要这里的权限
address inventor = 0x18E90Fc6F70344f53EBd4f6070bf6Aa23e2D748C;
address mantso = 0x8b4DA1827932D71759687f925D17F81Fc94e3A9D;
address justo = 0x8e0d985f3Ec1857BEc39B76aAabDEa6B31B67d53;
address sumpunk = 0x7ac74Fcc1a71b106F12c55ee8F802C9F672Ce40C;
address deployer = 0xF39e044e1AB204460e06E87c6dca2c6319fC69E3;
admins_[inventor] = Admin(true, true, "inventor");
admins_[mantso] = Admin(true, true, "mantso");
admins_[justo] = Admin(true, true, "justo");
admins_[sumpunk] = Admin(true, true, "sumpunk");
admins_[deployer] = Admin(true, true, "deployer");
改完后,如上贴源码,编译后部署TeamJust合约,记录地址,替换playbook合约的TeamJustInterface地址
- 部署playerBook合约
很有意思的合约,这里就是上面说的整个游戏其实只需要两个合约中的一个。 不解读细节了,直接改吧
你会发现这里怎么还有个JIincForwarderInterface地址,第三步不是说不部署这个了么 ?
这里的主要是收取别人注册名字开启邀请返佣机制时需要支付的那0.01ETH的
知道了这个,就跟第3步一样加个reward收款地址吧,细节不标
如上贴源码,编译后部署PlayBook合约,记录下地址, 替换fomo3d合约里的PlayerBookInterface地址。
- 部署fomo3dLong合约
这个是另一个核心合约之一,这里也有个闭源合约,用来初始化控制时间的参数
直接注释掉,然后如下改动
uint256 private rndExtra_ = 30; // 和rndInit一起控制第一轮游戏开始的初始时间的,单位是秒
uint256 private rndGap_ = 30; // 和rndInit一起控制下轮游戏开始的初始时间的,单位是秒
还有两个改动点就是activate和setOtherFomo里加上自己的deployer地址,
额外把setOtherFomo里的往另一个游戏池子里输血的功能改到,因为我们没有其他的游戏,如第三步一样,换个收款码吧
otherF3D_.transfer(_long);
部署吧!!!
最后部署这一步,很有可能遇到errored: oversized data的错误,刷新remix页面即可。
合约设置
先setOtherFomo,然后再设置playbook里的addgame,最后activate即可。
页面
页面直接Ctrl+s下载原版界面,把最后的fomo3dLong的合约地址替换下,另外那个后台API,其实没什么,自己试下就知道了,然后就可以上线了。。。
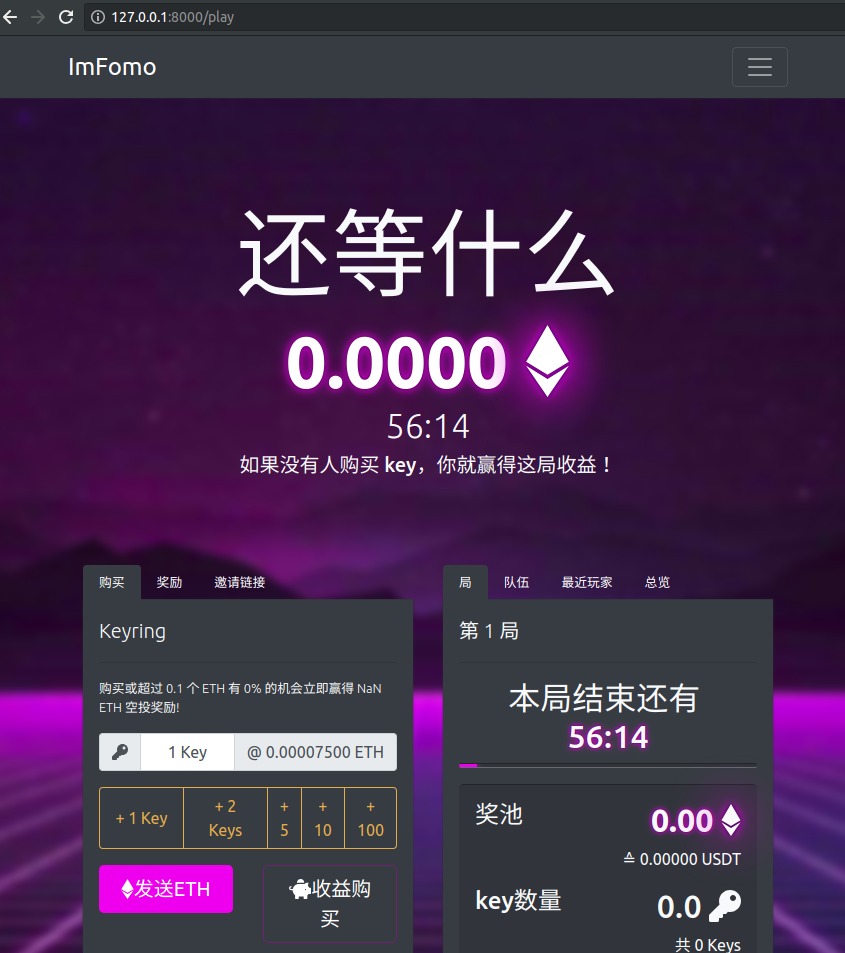
感受
- 合约debug难如上青天
- 要替换一大堆合约里的地址,除了Interface类的要替成依赖的合约地址,其他的全可以写成你自己地址(即使都一样的也OK)就可以。
目前我们搞出来的定制版有:
- 多级返佣模式, 可自定义级数
- 空投fix版
- 去除战队版
- 移除p3d版本
- 原版
5.5 - fomo3d-钱都去哪儿了
fomo3d里有战队系统、邀请分佣机制、持key分红、空投系统、持p3d分红等玩法, 相信通过之前各类媒体的解读都有所了解。
下面通过分析合约代码,以讲解ETH数据流向的方式串下所有流程,让大家明明白白的知道自己的ETH都去了哪里。
以10ETH充币到fomod3d合约举例,分三种情况
- 早期用户(游戏刚启动时的激进者)
- 中期用户(为了赚分红、返佣的用户)
- 晚期用户(为了赢48%大奖的人)
早期
当合约被激活后,开发者做了一个很“仇富”的举动,每个地址在合约收到100ETH之前,只能购买1ETH的keys,防止被资本大鳄收割本轮后面入场的玩家。这里有个小hack的点,就是提前多准备些小号,多个地址去投,也可以做到比别人便宜多的价格买到keys。
这个阶段以买入10ETH举例,你只会买到等同于1ETH价值的keys,其余9个ETH会直接进入你的收益里, 演示如下:
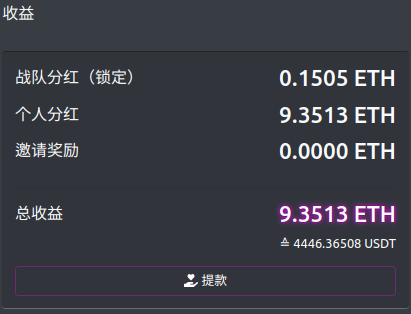
下面是实现此功能的代码

代码里的规则(不限阶段)梳理:
- 提款功能可以无限次提,不影响本轮接下来的分红收益,你的收益来自于你持有keys的分红。
- 最低可以支付1e-09个Ether,当购买的Key数量大于或者等于1个时,倒计时会加30秒。
- 当支付的eth不小于0.1时,会送一次“彩票”,买key支付的金额越大,中奖的奖金也越大,最大可中“彩票池”里额度的75%,直译过来这个功能叫空投。
中期
所有阶段的用户如果是直接打开的官网,充币买keys时会触发合约的这个接口,

其中_affcode是值邀请人的地址,_team是指用户所有购买key所选的战队,默认的2是指蛇队。
如果是从别人的邀请进入的官网,要看邀请人给你发的是哪个链接,有三种形式的链接:
 ,
,
从上到下,分别会走buyXaddr、buyXid、buyXname的接口,比如我给人发了exitscam.me/xxp的邀请链接,被邀的人买keys时会触发如下接口:

这其中我个人会收到他买key总额度的10%佣金,这里还有个隐藏的点:
如果用户是直接从官网进入买key的,那同样会有10%佣金的产生,只不过是流向p3d的持有者。
晚期
当有人买key时,都会选择一个战队,默认会被勾选蛇队的,当买到keys数量不小于1个时,会使所选战队成为本轮的潜在获胜队。
说了这么多废话,回归正体,你的10ETH到底去了哪里???
如果支付10ETH时,选的是蛇队,你10个ETH里的5.6个会被持keys的人均分,1个看情况是给p3d的人还是给邀请你的人,还有1个必定会分给持有p3d的人,另外2个会进入大池子,其中0.2个会分给社区贡献人,0.1个会给TeamJust的另一个游戏合约,还有0.1个会流到“彩票池”里。
这里面根据你选的战队不通,分配比例不一样,具体看下的代码,执行这些ETH分配的是走distributeExternal,distributeInternal 出去的。
后面的PotSpit是本轮游戏结束后,如何分配大池子里的金额。
// Team allocation structures
// 0 = whales
// 1 = bears
// 2 = sneks
// 3 = bulls
// Team allocation percentages
// (F3D, P3D) + (Pot , Referrals, Community)
// Referrals / Community rewards are mathematically designed to come from the winner's share of the pot.
fees_[0] = F3Ddatasets.TeamFee(30,6); //50% to pot, 10% to aff, 2% to com, 1% to pot swap, 1% to air drop pot
fees_[1] = F3Ddatasets.TeamFee(43,0); //43% to pot, 10% to aff, 2% to com, 1% to pot swap, 1% to air drop pot
fees_[2] = F3Ddatasets.TeamFee(56,10); //20% to pot, 10% to aff, 2% to com, 1% to pot swap, 1% to air drop pot
fees_[3] = F3Ddatasets.TeamFee(43,8); //35% to pot, 10% to aff, 2% to com, 1% to pot swap, 1% to air drop pot
// how to split up the final pot based on which team was picked
// (F3D, P3D)
potSplit_[0] = F3Ddatasets.PotSplit(15,10); //48% to winner, 25% to next round, 2% to com
potSplit_[1] = F3Ddatasets.PotSplit(25,0); //48% to winner, 25% to next round, 2% to com
potSplit_[2] = F3Ddatasets.PotSplit(20,20); //48% to winner, 10% to next round, 2% to com
potSplit_[3] = F3Ddatasets.PotSplit(30,10); //48% to winner, 10% to next round, 2% to com
还有很多细节要分享,碍于时间有限,不过我会持续更新这里的
感想
- 持有p3d的人和早期进入的才是最大的受益者
- 后期进入的人只有通过拉人赚佣金的方式回本了
- 这轮游戏应该是结束不了的: 总有人赔了,要拉人进来捞本,被拉的人周而复始。。。
- 结束只有两个可能: 1. 合约有重大漏洞,资金被盗 2. 当大池子里48%的收益足以对整个以太网络发动51%攻击。。。
- 矿工在背后偷着乐
- 你们谁知道TeamJust的下个游戏的合约地址么? 我知道!!!
如果你也找到了,可以加我微信yiyemeishui, 加好友时请输入TeamJust的下个游戏合约地址,我们一起来票大的。。。
5.6 - 解读cosmos-sdk系列(1)
通过本系列,可以了解tendermint共识和cosmos-sdk架构的设计思想,并学习到如何通过Cosmos-SDK来快速开发自己的区块链应用。
cosmos团队把区块链分成了三层
- 网络层 - p2p负责广播交易
- 共识层 - 对哪些交易打包进块形成共识
- 应用层 - 执行交易,负责交易结果落盘(状态一致)
这里的应用层可能会有误解,并非是Dapp层,对于SDK底层的Tendermint来说,除p2p网络和打包块共识外,其他都算是应用部分, 拿实现比特币公链的例子来讲,应用部分就是维护账户的UTXO数据库,如果对比以太的话,keystore账户和EVM虚机部分就是应用范畴,所以SDK内置了账户、质押、治理、权限等应用模块,可以帮助我们简单地实现底层链的开发。
可以把这几层简单理解成各节点通过同步交易集(块)日志,实现数据(状态)一致性。数据库的主从模式不也是同步binlog日志,各自执行(replay,回放)日志后,实现数据(状态)最终落盘,区块节点本身同步块的时候,默认就是去下载交易日志,把执行结果按照逻辑链的形式写入本地leveldb的,然后才能对外提供各类RPC服务。
tendermint共识
为后续更好的利用cosmos-sdk,要先了解下Tendermint。
Tendermint Core 提供了网络和共识层功能,而应用层要通过ABCI协议和Core互通消息msg,简单讲tendermint负责起一个replication engine进程,而应用层要运行一个state macheine进程,进程间通过ABCI消息来通信。
ABCI协议的消息体用protobuf定义在这里,app侧可以响应的request如下:
message Request {
oneof value {
RequestEcho echo = 2;
RequestFlush flush = 3;
RequestInfo info = 4;
RequestSetOption set_option = 5;
RequestInitChain init_chain = 6;
RequestQuery query = 7;
RequestBeginBlock begin_block = 8;
RequestCheckTx check_tx = 9;
RequestDeliverTx deliver_tx = 19;
RequestEndBlock end_block = 11;
RequestCommit commit = 12;
}
}
ABCI的设计主要有以下几个特点:
-
消息协议
- 成对出现的消息:
request/reponse - tendermint发起Request, app来响应
- 使用protobuf定义
- 成对出现的消息:
-
server/client
- tendermint运行client
- app侧运行server端
- 可以由TSP(支持checkTx和DeliverTx消息的异步处理)、grpc两种方式实现
-
区块相关
- abci是面向连接的
- tendermint会创建三个socket连接来和app通信,分别是
Mempool,Cosensus,Query连接-
Mempool连接: 钱包客户端发起交易,会首先进入钱包后台连接的节点的local mempool,该节点通过发送checkTx消息来通知app,去检验交易签名是否有效等等,如果OK节点则会p2p广播该交易到其他节点的mempool里。 -
Cosensus连接: 出块节点从mempool的交易集里选出一个块提案(proposer),之后会经过3阶段提交(pre-vote, pre-commit, commit)处理,这个块才能说达成共识(上链了),,只有块被commited了,app侧才会更新状态,比如改变某地址余额等等。app更新状态的时候,是通过Core发送BeginBlock,DeliverTx ...,EndBlock,Commit消息给app侧来完成的,任何写入操作都是通过此连接完成的。 -
Query连接: 主要负责一些和共识无关的查询操作,比如块信息,地址余额等等,主要用到Info,SetOption,Query消息
-
整个abci的信息流大致如下:
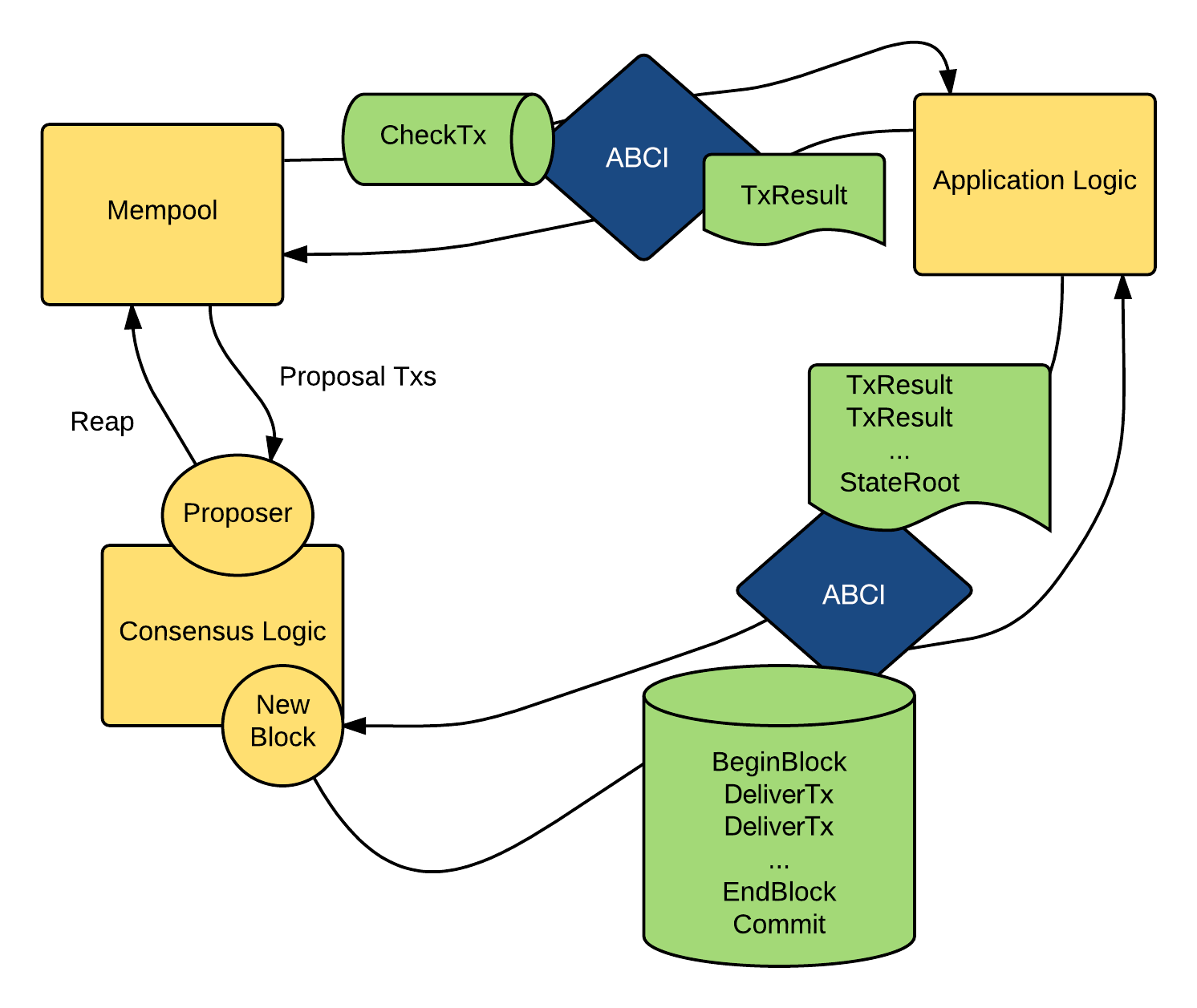
关于Tendermint和app间数据流的更多细节见下:
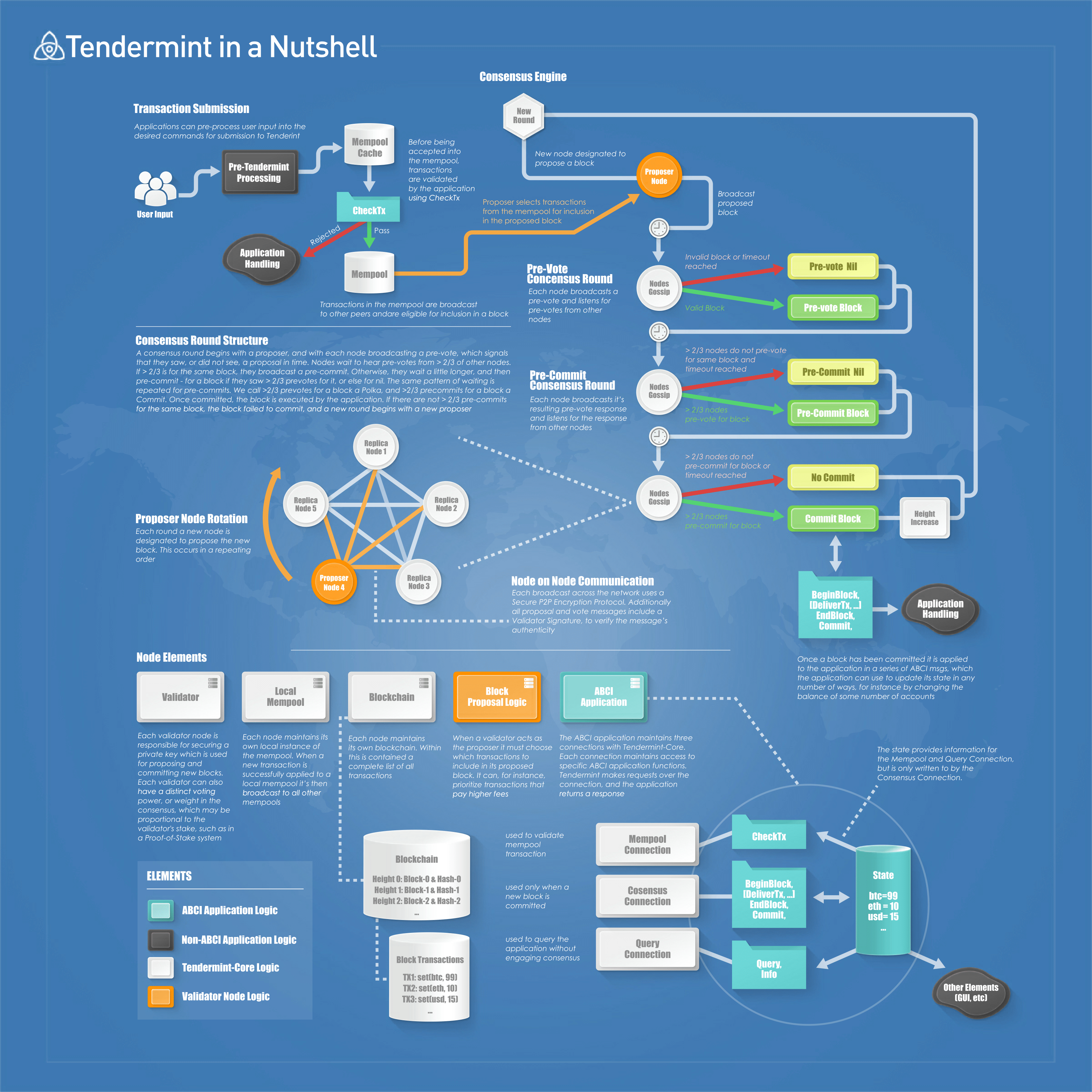
总结
可以理解成,Tendermint主要负责在BFT环境下同步app间的块交易日志,无论任何交易类型,只要交易块的执行结果是确定性的(唯一性),Tendermint就可以为我们形成区块的共识。
比如说,一个交易的内容在合约里创建一个真随机数,这种交易,tendermint是无法为我们形成共识的,因为多个节点的执行结果是不一样的, 因为这个结果是要在下个区块头的,这样就无法对下个区块形成共识了,所有节点都认为对方在恶意“搞分叉”了。
目前基于tendermint的项目有很多:
我个人看到好的是BigchainDB和超级账本Burrow项目,更多可以看这里
后续源码介绍,如何基于tendermint创建一个区块链
5.7 - farbic-搭建高并发交易网络
针对每秒数千笔交易的场景,默认的CCVC(并发控制版本检查)会导致交易失败率的上升,其实不需要对基础网络本身做特殊设置,从合约代码入手可以解决,参考官方例子farbic-samples.
下载项目
基于目前最新的v1.0.3版本来说
git clone https://github.com/hyperledger/fabric-samples.git
cd fabric-samples/first-network
未完...
5.8 - fabric-示例集群化操作
fabric给出的cc样例都是跑在docker-compose上,这里介绍利用已有的docker-compose.yaml如何集群化运行。
准备样例CC
以官方fabric-samples项目里的balance-transfer为例,准备拆分运行在4个虚机里。
git clone https://github.com/hyperledger/fabric-samples.git
cd fabric-samples/balance-transfer
本CC的示例,主要由3个部分组成:
- 2 CAs
- 1 SOLO orderer
- 4 peers (2 peers per Org)
其中artifacts目录里放置了:
- 由 cryptogen 工具生成的证书信息,后面运行时需要挂载到各自的peer节点里
- 由 configtxgen 工具生成的初始块
genesis.block和 channel配置信息mychannell.tx
准备集群
根据上面的情况,下面准备四个虚机来集群化操作, 虚机规划信息如下:
- air13, 192.168.10.78, 运行ca1,ca2, 这是我的本机
- node0, 192.168.10.110, 运行orderer
- node1, 192.168.10.114, 运行org1的peer0、peer1
- node2, 192.168.10.115, 运行org2的peer0、peer1
每个虚机都预先安装docker和docker-compose
修改artifacts/docker-compose.yaml文件,在每个service下添加如下信息:
extra_hosts:
- "ca.org1.example.com:192.168.10.78"
- "ca.org2.example.com:192.168.10.78"
- "orderer.example.com:192.168.10.110"
- "peer0.org1.example.com:192.168.10.114"
- "peer1.org1.example.com:192.168.10.114"
- "peer0.org2.example.com:192.168.10.115"
- "peer1.org2.example.com:192.168.10.115"
此举的作用是在每个容器的/etc/hosts文件里,添加上面的映射,最终docker-compose.yaml文件放置gist上了.
最后一步,因为此CC样例运行时,需要挂载本地目录里一些提前生成好的证书,我们还需要把这么需要挂载的东西,同步到每个虚机里,如下操作:
rsync -az balance-transfer root@192.168.10.110:~/
rsync -az balance-transfer root@192.168.10.114:~/
rsync -az balance-transfer root@192.168.10.115:~/
集群化运行
ssh进入虚机,按照规划启动各自的服务
# 进入air13虚机
cd balance-transfer/artifacts/
docker-compose up --no-deps ca.org1.example.com ca.org2.example.com
# ssh进入node0虚机
cd balance-transfer/artifacts/
docker-compose up --no-deps orderer.example.com
# ssh进入node1虚机
cd balance-transfer/artifacts/
docker-compose up --no-deps peer0.org1.example.com peer1.org1.example.com
# ssh进入node2虚机
cd balance-transfer/artifacts/
docker-compose up --no-deps peer0.org2.example.com peer1.org2.example.com
如上fabric的区块链网络已经集群化运行了
运行APP并测试CC
在虚机air13上运行我们的前端APP,并测试在网络集群化后的的CC,
此外由于此APP样例的特殊性,还需要修改其他的地方
- config.json文件里的orderer地址改为
"grpcs://192.168.10.110:7050" - app/network-config.json里指定地址的地方需要改成这样
进入balance-transfer目录,如下执行:
$ npm isntall
$ PORT=4000 node app
这样前端APP就运行起来了,接下来利用测试脚本testAPIs.sh测试下我们的CC,运行前,还需要修改下脚本里的peer地址,修改后的文件在这里
运行脚本:
./testAPIs.sh
POST request Enroll on Org1 ...
{"success":true,"secret":"DbzvtdmATgve","message":"Jim2 enrolled Successfully","token":"eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE1MDE4NzQ5MjUsInVzZXJuYW1lIjoiSmltMiIsIm9yZ05hbWUiOiJvcmcxIiwiaWF0IjoxNTAxODM4OTI1fQ.LUmfEstviquaD5k5oBMd9KUFaKF1s6ZMY8iO67dKiH0"}
。
。
。
GET query Installed chaincodes
["name: mycc, version: v0, path: github.com/example_cc"]
GET query Instantiated chaincodes
["name: mycc, version: v0, path: github.com/example_cc"]
GET query Channels
{"channels":[{"channel_id":"mychannel"}]}
Total execution time : 13 secs ...
本样例修改后的完整地址在这里
总结
目前集群化后网络里的peers ledger和orderer的数据还是存储在容器里,是否要考虑挂载出来,不然容器挂了再启动后,数据是否会乱了,后续研究下。
后续还会继续搞下CA,MSP和动态添加节点以及合约迭代升级等问题。
5.9 - farbic-区块链的生产集群化
默认社区的demo是基于docker-compose给出的,达到了“一键部署”的效果,但生产上考虑多节点的情况,还需要费些手脚,这里考虑用kompose结合k8s来做这件事。
k8s集群 1.7的初始化
每个节点都要安装docker的步骤,此处略过不表,这里主要介绍利用kubeadm初始化k8s集群,这里不考虑k8s集群本身的高可用,以前有文章专门介绍过。
apt-get update && apt-get install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet kubeadm
# 默认会自动安装这些包 ebtables kubeadm kubectl kubelet kubernetes-cni socat
如果你本机是centos的话,可以用如下命令安装
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
setenforce 0
yum install -y kubelet kubeadm
systemctl enable kubelet && systemctl start kubelet
上面的命令,需要翻墙才能跑通,没条件的可以去release项目自己编译deb包或者rpm包,如下运行
git clone https://github.com/kubernetes/release.git && cd release
# debian系如下
docker build --tag=debian-packager debian
docker run --volume="$(pwd)/debian:/src" debian-packager
# docker run -e "HTTPS_PROXY=127.0.0.1:8118" --net=host --volume="$(pwd)/debian:/src" debian-packager
# 默认debs包在目录debian/bin/stable/xenial下
# centos系的如下
cd rpm
./docker-build.sh
#默认rpm包在目录output/x86_64/下
必要依赖搞到手后,就可以简单的利用kubeadm启动集群了 在master节点上如下执行初始化,此过程会启动 etcd,controller-manager,scheduler,api-server组件
kubeadm init --kubernetes-version stable-1.7 --pod-network-cidr=10.244.0.0/16
在其他节点上执行join操作
现在必须要加上--node-name参数,不然报错误,这是个bug
kubeadm join --token 4cc663.c4d99a546c9f3974 192.168.10.78:6443 --node-name node-0
默认还需要启动pod network,我默认用的flannel。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel-rbac.yml
另外默认master节点是不会被调度容器的,如下可放开限制
kubectl taint nodes --all node-role.kubernetes.io/master-
默认我们得到如下的集群状态
➜ ~ kubectl get no
NAME STATUS AGE VERSION
air13 Ready 2h v1.7.2
node-0 Ready 17m v1.7.2
准备fabric的k8ss所需yaml文件
这里需要用到下载我改过的kompose工具,默认官方的对hostpath的处理,需要引入PV,PVC,虽然这样无可厚非,但对与现阶段的我增加了不必要的复杂度,就动手加了个--hostpaths的选项,
# 下载我改过的工具项目-kompose
git clone https://github.com/xiaoping378/kompose
cd kompose && make
# 如上会编译出kompose来,自己搞到$PATH里
这里以fabric-samples项目里的balance-transfer为例,演示一个完整的CC运行在k8s上。
下载fabric-samles项目,
git clone https://github.com/hyperledger/fabric-samples.git
cd fabric-samples/balance-transfer
kompose convert -f artifacts/docker-compose.yaml -d --hostpaths
# 如上会在当前目录出现批量的deployment和service yaml文件,这里需要针对hostpath的volumes稍作修改
sed -i 's/.\/channel/\/root\/balance-transfer\/artifacts\/channel/' *-deployment.yaml
#如上改成绝对路径,另外还需要保证各节点都要有channel目录
rsync -avz balance-transfer root@node-0:~/
因为ca, peer, orderer都需要从本地读取证书相关的信息,所以要把各节点利用nodeSelector特性绑定到指定的节点上,这一点以后得改掉,利用env来动态生成(待验证)
#比如让要在特定节点调度特定容器,需要如下操作
kubectl label node node0 ca=ture
还要在对应的deployment文件做如下操作
-- 未完待续。。。
6 - RPA机器人
主要介绍如何建设企业自己的RPA机器人流程自动化平台。
RPA(机器人流程自动化)借助AI(OCR、NLP)等技术,在疫情劳动力不足和数字化转型的大背景下,东风又起。国内该领域最早可追溯到按键精灵时代,可以模拟人操作设备(电脑、手机)的行为,无缝集成新旧系统,减少重复性任务,实现桌面流自动化。
本质上可以认为是自动化领域的技术,Gartner连续三年提到的技术趋势-超级自动化HyperAutomation(一种技术合集),主要包括
- RPA(机器人流程自动化)
- LCAP(低代码应用平台)
- AI(人工智能技术
- iBPMS(智能业务流程管理)
目前openrpa开源项目, 基本实现了hyperautomaion的前三项技术要求。
6.1 - openrpa介绍
openrpa的架构介绍
概述
openrpa项目,提供了OON技术栈(OpenRPA、Openflow、Node-RED)来实现的RPA功能。
OpenRPA
该组件可以认为是机器人的IDE设计器部分,基于MWF框架实现的,
- 可以图形化拖拽的方式实现基本功能
Activity,如点击邮箱、打开浏览器网址、输入文字、录屏录音、各类监听探测器等等 - 多个
Activity可以组合成一个序列,来实现工作流workflow,串行执行一系列动作 - 也可以通过配置作为agent(机器人)运行,负责执行设计好的工作流
- 默认远程连接到云端控制端(openflow),可上传同步本地的工作流和接受控制端的调度管理。
Openflow
OON技术栈的后台核心部分,可以关编排管理所有的活动,主要具备一下特性:
- 管理,调用和配置机器人和工作流
- 管理用户和权限(组)
- 创建Web表单,供和真实用户交互,实现工作流的输入,审批和确认等操作。
- 管理后端MongoDB存储
- 存储工作流、表单等数据信息
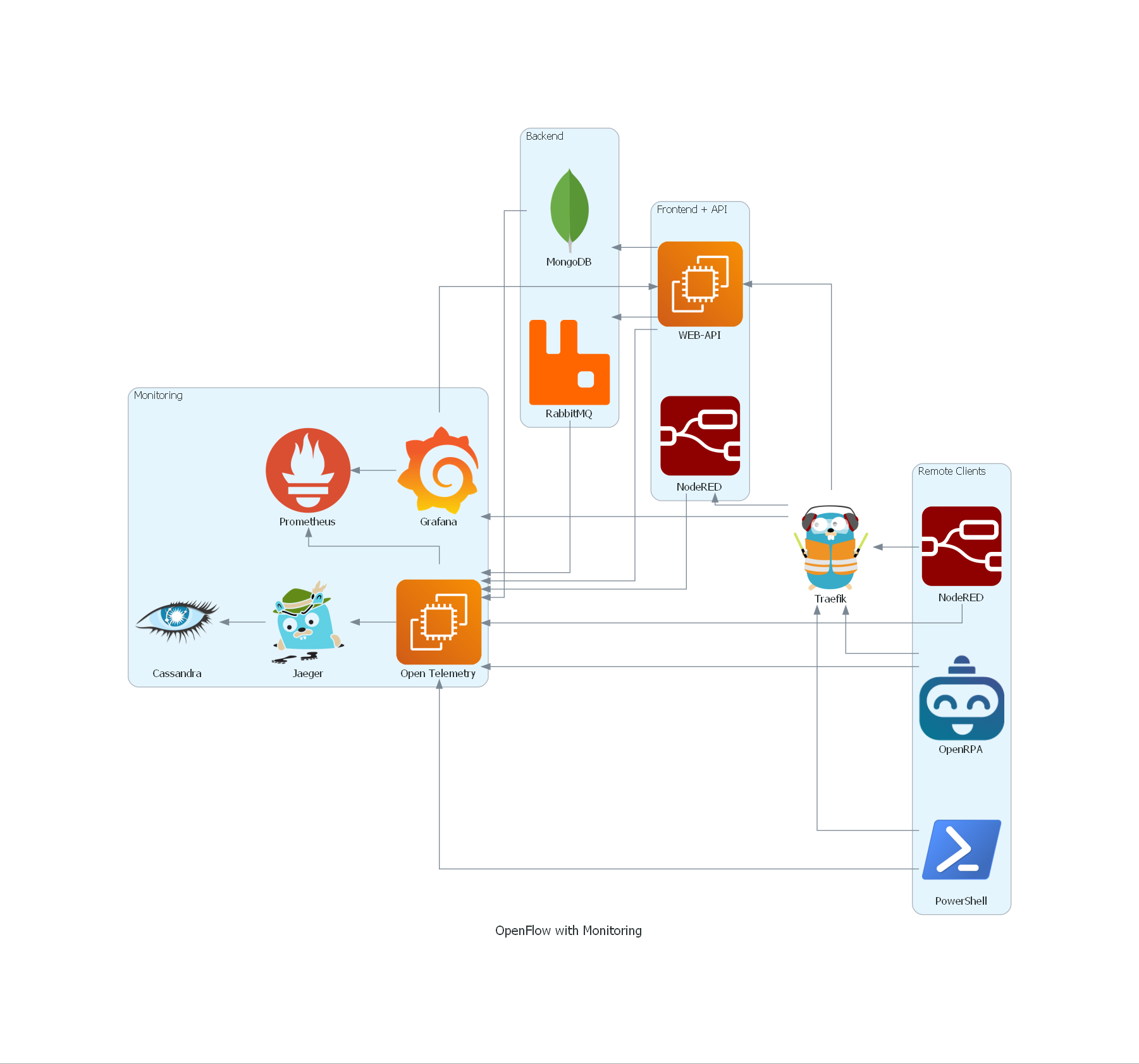
Node-RED
FAQ
三大组件汇总具有流的概念,openrpa中叫workflow,node-red中叫flow, openflow组件名称自身就带了flow的字样,界面上也有
7 - AI应用开发
介绍如何开发企业级AI大模型应用。
7.1 - AI大模型应用开发-扫盲篇
AI大模型应用开发-扫盲篇
当下从工程技术角度来看,AI大模型可以分为十个领域:前沿大模型、基准评估、提示思维链、检索增强生成、智能体、代码生成、视觉、声音、图像/视频扩散、微调。 本文旨在扫盲大模型应用开发基础概念,并介绍大模型应用开发的常见模式。
一、怎样得到一个大模型?
有卡没卡两种玩法,如果只面向应用开发,结合上信息安全的背景,则推荐使用社区开源模型或集成企业内部模型(下节介绍)。
1. 囤卡自己训练(全流程定制)
-
核心概念
- AI(artificial intelligence): 由来已久的概念,本文特指的生成式人工智能(gen AI),将机器学习和深度学习的神经网络提升到了一个新的水平。它可以创建新的内容和想法(例如图像和视频), 也可以使用已知知识来解决新问题。
- LLM (Large Language Model): 大型语言模型,是基于大量数据进行预训练得到的超大型深度学习模型,可自主学习(统计归纳),会理解(Token向量化)人类基本的语法、语言和知识。一般用参数的多少来衡量大模型能力。
- GPT (Generative Pre-trained Transformer): 生成式预训练 Transformer 模型,是一系列使用 Transformer 架构的神经网络模型,能够回答产出(关联预测)类似人类的文本和内容(图像、音乐等),并以对话方式回答问题。
- Transformer 模型: GPT的核心,是一种神经网络架构,它使用了自注意力机制(self-attention)来处理序列数据,并使用了多头自注意力(multi-head self-attention)来提高模型的性能。
- Pre-trained (预训练): 在无标注通用数据(如Common Crawl)上训练出基础模型,从已知找规律(优化损失函数)学习语言规律和世界知识,预测产出未知。需从头构建模型,通常需要超万亿token的庞大数据集和数万张高性能GPU(如H100/A100)组成的算力集群。
- Fine-tuning (微调): 在预训练模型基础上,用于特定领域数据(如金融客服、辅助编码)调整参数,使模型更适应垂直场景的推理。通常仅需调整少量参数(如使用LoRA技术调整0.1%-1%的参数),显存需求可降低至预训练的10%-20%。
- 模型压缩: 模型压缩技术,如量化、剪枝、知识蒸馏等,可以减少模型的参数数量,从而降低显存需求。
- 知识蒸馏: 将大型复杂模型(教师模型)在有限损失的情况下知识转移到更小型、高效模型(学生模型)中, 这样做的好处包括降低计算成本、减少推理时间,同时保持高性能,适合资源受限环境的部署。
- 模型量化: 模型量化是指将模型参数从浮点数转换为整数或低精度数据类型,以减少存储和计算开销。
蒸馏提取精华,量化降低细节。
-
实施难点
- 硬件门槛: OpenAI的GPT-4预训练成本约7800万美元,下一代模型的训练成本可能突破10亿美元,甚至向100亿美元迈进。国内有厂商利用算法优化,达到GPT-4同等性能表现的情况下,使大模型训练成本大幅降低,但也需要近600万美元的成本。
- 数据要求: 需清洗TB级高质量文本,避免噪声干扰。
- 技术复杂度: 涉及分布式训练、梯度优化等工程难题。
-
适用场景
当下大模型训练成本呈现“头部攀升、尾部下降”的极化现象。技术创新(算法优化、工程协同、开源生态)和国产算力替代为降本提供可能,此模式推荐巨头企业或科研机构用于前沿模型研发(如训练行业专属大模型)。
2. 下载社区开放模型(主流选择)
上一种方法,需要自己训练、微调得到一个LLM模型,现在介绍直接下载使用开放的大模型。
-
推荐平台
推荐平台(类似于代码找github,容器镜像找dockerhub的关系),可下载热门模型(和数据集):
- 国外平台: Hugging Face Hub: 提供100万+开源模型,涵盖Qwen2、DeepSeek、LLaMA、Gemma等热门模型。
- 国内平台: 魔搭ModelScope、智源悟道、讯飞星火。
-
模型类型(可商用)
模型名称 参数量 特点 典型用途 LLaMA-3 8B~70B Meta,支持微调 通用对话、推理 Mistral-7B 7B 法国,性能接近LLaMA-13B 代码生成、摘要 Phi-4 14B 微软,支持微调 擅长英语对话 Qwen-系列 0.5B~72B 阿里,大语言模型和大型多模态模型系列 通用对话、推理 DeepSeek-v3 671B 国内幻方,MoE模型,训练成本降60% 通用对话、推理 DeepSeek-R1-蒸馏 32B~70B 国内幻方,模型蒸馏,支持微调 复杂推理、编码、数学 ... ... ... ... -
对比维度
维度 说明 示例对比 参数量 7B/13B/70B等,参数量越大能力越强,但资源需求更高 LLaMA-7B(8GB显存) vs LLaMA-70B(需多卡) 上下文窗口 单次输入支持的最大Token数 GPT-4(128K) vs Claude-3(200K) 多语言支持 是否支持中文、代码等非英语场景 Qwen-72B(中文优化) vs CodeLlama 推理速度 生成100个Token所需时间,影响用户体验 Mistral-7B(快) vs LLaMA-13B(较慢) CPU推理支持 没有GPU的要考虑,是否提供量化版本及CPU优化方案 LLaMA.cpp(CPU优化) vs DeepSeek-MoE(需GPU) 内存占用 不同精度(FP16/INT8)消耗不同 Phi-3(4GB) vs Qwen1.5-4B(8GB) 许可证 商用限制(如LLaMA-2可商用,LLaMA-1仅限研究) 企业选型需重点审查 多模态支持 输出格式:图像、文本、音频、视频等 GPT-4o-mini(多模态) vs deepseek-v3(仅文本)
参数B和Token的关系
参数B应该是指模型训练的参数量,比如7B就是70亿参数。Token则是问答处理中的基本单位,通常对应单词或子词(1 Token约为1个汉字或4个字母)。 参数数量影响模型的学习能力和复杂度,而Token处理涉及输入输出的长度和速度。两者在模型训练和推理阶段都有不同的影响。比如,参数多的模型通常需要更多的计算资源,处理Token的能力更强,生成更准确的文本。但这也可能带来更高的延迟和资源消耗。
二、怎么使用大模型
前面主要讲了怎么得到大模型(自己训练和下载开源模型),下面介绍怎么使用大模型,技术上简单讲就是调用大模型的API,让大模型(服务)输出结果(文本生成、代码生成、图像生成)。 可以类比为一种中间件,用户可只关注输入和输出,中间件(大模型)负责推理产出。
-
在线API调用
- 国外厂商: 典型OpenAI的
gpt-4-turbo每千Token约$0.01,延迟低但数据需出境。 - AI集成服务: 在线集成的模型服务,本文发稿时众代理商均有活动,可领取百万Token免费额度
- 国内厂商: deepseek(性价比极高,每百万Tokens为2元)、智谱AI(符合数据合规要求)、千问、百川。
- 国外厂商: 典型OpenAI的
-
本地私有化部署
-
加速推理的引擎选择:
工具 优势 适用场景 性能基准 vLLM PagedAttention技术提升吞吐量3倍 高并发API服务 (CPU/GPU/TPU..) 70B模型 120 tokens/s (A100) llama.cpp 极致CPU优化,支持苹果Metal加速 边缘设备部署 7B模型 45 tokens/s (M2 Ultra) Ollama 一键部署,内置模型库 快速原型验证 13B模型 28 tokens/s (i9-13900H) TGI 企业级特性(监控/负载均衡) 生产环境集群 (不支持CPU) 支持千级别并发请求 -
硬件推荐指南:
硬件环境 推荐模型 性能指标 适用场景 手机/边缘设备 Phi-3-mini (3.8B) iPhone 15 Pro: 35 tokens/s 离线对话、实时翻译 CPU笔记本 Qwen1.5-4B-Chat-GGUF (量化版) i7-12700H: 18 tokens/s 文档摘要、基础问答 消费级GPU Llama-3-8B-Instruct (4-bit量化) RTX 4090: 85 tokens/s 代码生成、知识库问答 企业级服务器 DeepSeek-MoE-16b-chat 2×A100: 120 tokens/s 金融分析、复杂推理 混合部署集群 Qwen1.5-72B-Chat + vLLM 8×H100: 240 tokens/s (动态批处理) 超长文本生成、多轮对话
-
-
硬件优化技巧:
- CPU加速:
- 内存优化,使用GGUF格式 + mmap技术加载模型
- 计算加速,启用BLAS库加速(OpenBLAS/Intel MKL),ARM设备可使用NEON指令集优化
- GPU显存压缩:
- 量化,将模型参数的精度从浮点数降低到低位表示(FP8,INT4等),使模型在资源有限的设备上更高效地部署(会降低部分模型性能)
- CPU加速:
-
开发模式对比:
方式 优点 缺点 适用阶段 在线API调用 快速集成,无需运维 依赖网络,数据出内网风险 原型验证 本地私有化部署 数据隐私可控,定制化强 硬件成本高,需调优 企业生产环境 公私混合部署 平衡成本与安全性 架构复杂度高 中大型项目
四、基于大模型的应用技术
1. 提示词工程(Prompt Engineering)
-
核心原则
- 角色定义: “你是一位资深律师,需用简洁语言解释以下法条...”
- 结构化指令: 使用XML/JSON格式明确输入输出规则。
- 少样本学习(Few-Shot): 提供示例引导模型理解任务。
-
工具推荐
- LangChain Hub: 共享高质量Prompt模板
- PromptPerfect: 自动优化提示词
2. RAG(检索增强生成)
-
技术流程
graph LR A[文档切分] --> B[向量化存储] B --> C[用户提问检索] C --> D[注入Prompt生成答案] -
关键组件
- Embedding模型: 文本转向量(推荐text-embedding-3-small)
- 向量数据库: Pinecone(云服务)、Chroma(本地轻量级)
- 重排序器: Cohere Rerank、BAAI/bge-reranker-large
-
难题中文分词语义
- 混合分词策略:Jieba(词典匹配) + LSTM-CRF模型(实体识别)
- 上下文增强:在向量检索后添加语义重排层(使用bge-reranker-base-v1.5)
-
开源框架
- LlamaIndex: 快速构建RAG流水线
- Haystack: 支持多模态检索
3. Agent(智能体)
-
核心能力
- 工具调用: 联网搜索、执行代码、调用API
- 任务分解: 将复杂问题拆解为子任务(如“规划旅行”→订机票→订酒店)
- 自我迭代: 根据反馈调整策略
-
开发框架
五、实战案例:企业知识库问答系统
技术方案
用户提问 → 向量检索(Milvus) → Rerank排序 → Prompt拼接 → LLaMA-7B生成 → 返回答案
代码片段(Python)
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# 1. 加载文档
documents = SimpleDirectoryReader("data").load_data()
# 2. 构建索引
index = VectorStoreIndex.from_documents(documents)
# 3. 问答查询
query_engine = index.as_query_engine()
response = query_engine.query("公司年假政策如何规定?")
print(response)
六、避坑指南
- 模型幻觉
- 添加事实性校验层(如调用Wolfram Alpha验证数值结果)
- 长文本处理
- 采用滑动窗口(Sliding Window)分割超长上下文
- 安全防护
- 使用NeMo Guardrails过滤敏感词 & 防止Prompt注入
希望通过以上内容,可以帮助大家系统掌握大模型应用开发的全链路要点,从模型获取到技术落地均有实用参考,推荐实践后,再根据兴趣/需求重点拓展跟进文章开头提到的十大热点领域。
作者:许小平
8 - 其他推荐
站点推荐、三方好文集中地
8.1 - 优秀文集
TODO 待整理
9 - 贡献指南
TOOD 待整理