性能优化指南
主要参考的官方链接, 本文是基于openshift 3.5说的。
概览
本指南提供了如何提高OpenShift容器平台的集群性能和生产环境下的最佳实践。 主要包括建立,扩展和调优OpenShift集群的推荐做法。
个人看法,其实性能这个东西是个权衡的过程,根据自身硬件条件和实际需求,选择适合自己的调优手段。
安装实践
网络依赖
首先安装自然要选择官方的openshift-ansible项目, 默认是rpm安装方式,需要依赖网络,比如要去联网下载atomic-openshift-*, iptables, 和 docker包依赖,
如果有不能联网的节点,可以参考我之前写的离线安装openshift。
ansible优化
官方推荐使用ansible安装,这里说下针对ansible的优化,以提高安装效率,主要参考ansible官方blog,
如果参考上文离线安装的话,不建议跨外网连接rpm仓或者镜像仓,下面是推荐的ansible配置
# cat /etc/ansible/ansible.cfg
# config file for ansible -- http://ansible.com/
# ==============================================
[defaults]
forks = 20 # 20个并发是理想值,太高的话中间会有概率出错
host_key_checking = False
remote_user = root
roles_path = roles/
gathering = smart
fact_caching = jsonfile
fact_caching_connection = $HOME/ansible/facts
fact_caching_timeout = 600
log_path = $HOME/ansible.log
nocows = 1
callback_whitelist = profile_tasks
[privilege_escalation]
become = False
[ssh_connection]
ssh_args = -o ControlMaster=auto -o ControlPersist=600s
control_path = %(directory)s/%%h-%%r
pipelining = True # 多路复用,减少了控制机和目标间的连接次数,加速了性能。
timeout = 10
网络配置
这里必须要提下,一定要安装前做好网络规划,不然后面改起来很麻烦,
默认是每个node上最多可跑110个pods,这个要看自身硬件条件,比如说我的环境全是高配物理机,我就改成了,每个节点可以跑1024个pods,这个主要改下面的地方。
openshift_node_kubelet_args={'pods-per-core': ['0'], 'max-pods': ['1024'], 'image-gc-high-threshold': ['90'], 'image-gc-low-threshold': ['80']}
osm_host_subnet_length=10
osm_cluster_network_cidr=12.1.0.0/12
关于网络的更多优化项,后面有单独介绍。
主机节点优化
openhshift集群里,除了pod间的网络通信外,最大的开销就是master和etcd间的通信了,openshift的master集成了k8s里的api-server, master主要通过etcd来交互node状态,网络配置,secrets和卷挂载等等信息
master侧
主要优化点包括:
- master和etcd尽量部署在一起.
- 高可用集群里,master尽量部署在低延迟的网络里.
- 确保**/etc/origin/master/master-config.yaml**里的etcds,第一个是本地的etcd实例.
node侧
node节点的配置主要在**/etc/origin/node/node-config.yaml**里, 优化点视具体情况定,主要可以优化的点有:
- iptables synchronization period,
- MTU值
- 代理模式
配合自文件里还可以配置kubelet的启动参数,主要关注两点pods-per-core 和 max-pods,这两个决定了node节点的pod数,两者不一致时,取值小的。如果数值过大(严重超卖)会导致:
- 增加cpu消耗,主要是docker和openshift自身管理消耗的
- 降低pod调度效率
- 加大了OOM的风险
- 分配pod ip出异常(可能地址池不够了,默认254个ip)
- 影响应用的性能
有一点要注意,k8s体系的平台,跑一个pod,实际会启动两个容器,一个pause先于业务容器启动,主要负责网络事项,所以跑10个pods,实际上会运行20个容器
etcd节点
etcd是一个分布式的key-value存储,所以有条件的话,存储读写性能的提升,上ssd最好了。
其次是网络的优化,比如和masters部署在一起,或者提供专网连接。
etcd实际使用中,最好的提升手段,是关注内存,这个官网有个换算公式的,多少pods推荐多大内存的使用
内核优化
上面的所有节点,内核层面都需要做些优化,这里推荐使用tuned工具来做,这点属于常规运维优化了,具体可以参考这里来做, 不想明白原理的,可以如下 快速操作,redhat的人已经自动化了。
yum install tuned
systemctl start tune
systemctl enable tuned
tuned-adm profile throughput-performance)来做
资源优化
超卖现象
主要是资源管理这块儿的注意点, 我以前有blog专门介绍过,主要值得一提的是,这里有个隐形的QoS级别
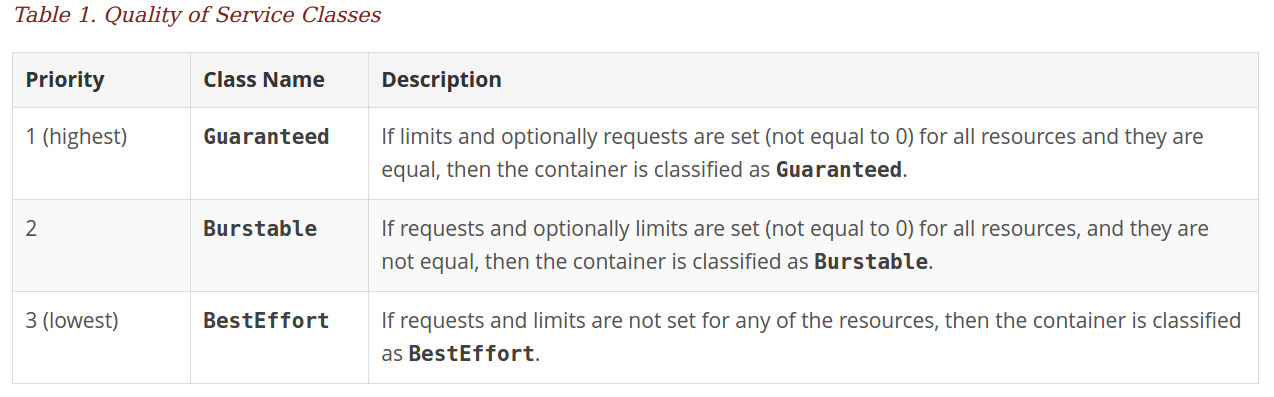
Guaranteed类型的pod是优先级最高的,是有保证的,只会在程序本身“异常”超出limits(一般的应用在pod层设置了limits,就不会超过该限制的,除非是java系的,其需要用环境变量来控制),才会被杀掉,其他类型的配额在集群资源紧张时会被kill掉的。
这块儿更多的细节也可以参考官文
镜像
这里需要注意的是,可以提前把需要的基础镜像先pull到node节点上,比如origin-pod镜像等,还有其他自定义的Gold 镜像,这样可以减少应用部署时间。
如果是采用镜像方式部署集群的话,也可以采取提前pull镜像的方式,当然有私有镜像仓的,可以忽略。
主要是现在默认的镜像拉取策略就是IfNotPresent,才能完成加速部署的效果
线上debug容器
线上容器环境可能很干净, 如何调试一个线上正在运行的容器,估计困扰过很多开发人员,这个其实利用docker原生特性,可以很easy的做到
比如你自己build一个工具包镜像tools,里面装有tcpdump,perf,strace等等debug工具,如下可以很方便的动态的嵌入到运行的线上容器中。
docker run -t --pid=container:production \
--net=container:production \
--cap-add sys_admin \
--cap-add sys_ptrace \
tools
当然万能的日志调式,也是OK的。
存储优化
这里的存储说的是docker的graph驱动( Device Mapper, Overlay, 和 Btrfs),首先overlay在启停容器速度方面要优于devicemapper,其还能带来更优良的页面缓存共享,但存在POSIX兼容性问题,比如不支持SELinux。
官方是推荐使用thin devicemapper的,但需要额外的独立块盘才能搞定。如果系统是7.2的话,使用overlay亦可,关闭selinux的代价就是牺牲部分容器安全。
路由和网络优化
openshift里的Router是基于haproxy做的,等价于k8s里的nginx ingress服务,提供集群内的service供外访问能力。
一般一个4 vCPU/16GB RAM的虚机,可以提供7000-32000 HTTP keep-alive连接请求,这取决于连接是否加密和页面大小,如果是物理机的话,性能会翻倍。
可通过Router sharding的技术来扩展性能。下图各种配置是统计性能(默认100个routes)
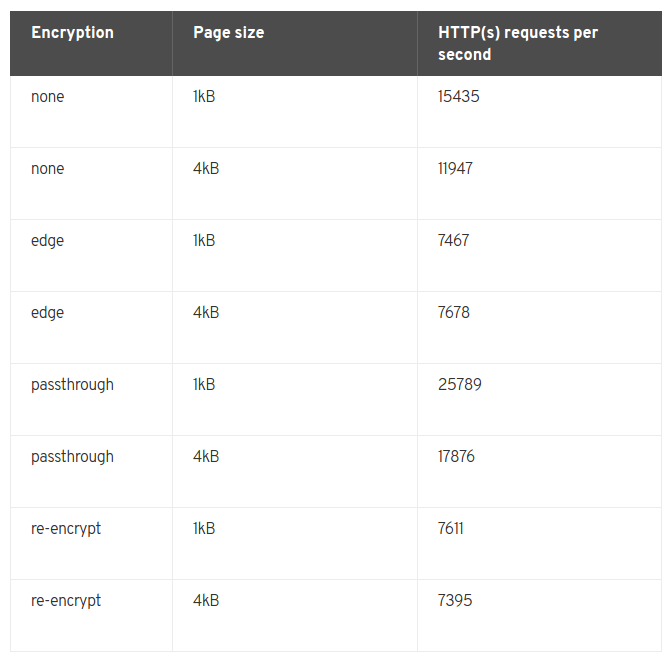
网络优化
默认openshift提供了一个基于ovs的sdn方案,其中涉及到了vxlan, OpenFlow和iptables,当然这些相关的优化项社区已经有很成熟的优化点和方法了,比如增大MTU,UDP-offload,多路复用等等,
这里重点说下vxlan, 基于二层网络,vxlan从4096提升到了16百万多个,vxlan就是把原报文封装进UDP报文,以提供所有pods间通信的能力,自然这样会增加cpu解封包的开销,具体网络吞吐取决于cpu的性能,另外还会额外增加延时响应。
直白的说,现在云主机或物理机的cpu都可以打满千兆网卡,如果是万兆网卡,那vxlan网络的吞吐带宽会卡在CPU上,这是所有overlay网络的现状。
如果你的主机用用万兆或者40Gbps, 那就要考虑网络的性能优化了:
- 通过直接路由,负责pod间通信,不过需要手动维护node节点添加删除时的路由变化。
- 条件允许的话,可以考虑BGP的calico网络方案
- 另外就是购置支持udp-offload的网卡
值得注意点是,及时使用了udp-offload的网卡,和非overlay网络比,延迟是不会减少的,只是减少了cpu开销,从而提高了带宽吞吐。
子网大小
现在openshift-ansible项目默认的安装出来的配置是:
- 集群里内最多1024个节点
- 每个节点最多可以跑510个pods
- 支持65,536个service
比如我要搞一个8192个节点的集群,每个节点允许510个pods运行:
[OSE3:vars]
osm_cluster_network_cidr=10.128.0.0/10
监控
都知道k8s里的弹性伸缩,依赖于Heapster, 而openshift内置的监控系统又是用的自家的Haw系列,导致监控镜像相当的大
在opneshift里有两点要提的是METRICS_RESOLUTION和METRICS_DURATION变量,前者是默认是30s,指的是监控时间间隔,后者默认是7天,指的是监控数据保留时长(过期就会删掉)。
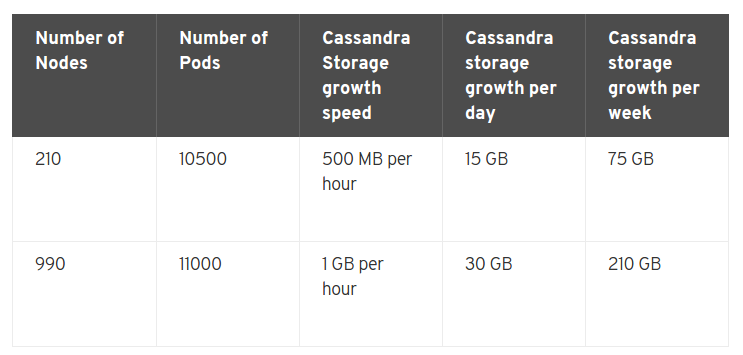
默认的监控体系(Cassandra/Hawkular/Heapster)可以监控25000个pods。
总结
其实openshift基于k8s提供了一站式解决方案, 如果公司不具备k8s二次开发能力,openshift足矣。