主要记录介绍以前个人的Openshfit实践总结。
Openshift
红帽家的k8s发行版,在持续演进中...
- 1: 快速安装
- 2: 权限资源管理
- 3: 项目开发实战
- 4: DevOps实战-0
- 5: DevOps实战-1
- 6: 编译和目录结构介绍
- 7: 多负载均衡方案
- 8: 镜像管理
- 9: 性能优化指南
- 10: 网络整理
- 11: 监控梳理
- 12: 日志分析
1 - 快速安装
介绍openshift的快速安装方法。
不知道为什么openshift在国内热度这么低,那些要做自己容器云的公司,不知道有openshift项目的存在么?完全满足我的需求。
docker负责应用的隔离打包,k8s提供集群管理和容器的编排服务,而openshfit则负责整个应用的生命周期:
- 源码管理,CI&CD能力
- 多租户管理, 支持LDAP和Oauth
- 集成监控日志于web console
先说下自接触到openshift项目就遇到的一个困惑,就是openshift origin/enterprise /online/dedicated/ocp之间的关系: orgin相当于Fedora, 其他的相当于RHEL
接下来谈下我用自己的笔记本实践的过程与感受:
- 快速安装
本人日常基于ubuntu16.04办公,所以用oc直接上, oc相当于kubectl
这里直接下载oc客户端,或者自行编译, 编译结果在_output目录下
git clone --depth=1 https://github.com/openshift/origin.git
cd origin && make
mv _output/local/bin/linux/amd64/oc /usr/local/bin
启动openshift, 默认开启监控并初始安装自最新版本,当前是v1.5.0-alpha.2
oc cluster up --metrics=true --version=latest --insecure-skip-tls-verify=true --public-hostname=air13
过程中会拉取所需镜像, 我这里显示比较多,之前已经做了些实验
➜ ~ docker images | grep openshift | awk '{print $1}'
openshift/node
openshift/origin-sti-builder
openshift/origin-docker-builder
openshift/origin-deployer
openshift/origin-gitserver
openshift/origin-docker-registry
openshift/origin-haproxy-router
openshift/origin
openshift/hello-openshift
openshift/openvswitch
openshift/origin-pod
openshift/origin-metrics-cassandra
openshift/origin-metrics-hawkular-metrics
openshift/origin-metrics-heapster
openshift/origin-metrics-deployer
openshift/mysql-55-centos7
openshift/origin-logging-curator
openshift/origin-logging-fluentd
openshift/origin-logging-deployment
openshift/origin-logging-elasticsearch
openshift/origin-logging-kibana
openshift/origin-logging-auth-proxy
启动后,会打印如下信息
OpenShift server started.
The server is accessible via web console at:
https://air13:8443
The metrics service is available at:
https://metrics-openshift-infra.192.168.31.49.xip.io
You are logged in as:
User: developer
Password: developer
To login as administrator:
oc login -u system:admin
打开浏览器,访问https://air13:8443,默认用developer登录,其实现在任意用户任意密码都可以的。
web console里是空空如野的,可以临时授权developer用户操作所有项目
oc adm policy add-cluster-role-to-user cluster-admin developer
2.技巧总结
- 命令行自动补全, 其实kubectl也可以如此
source <(oc completion bash)
-
默认监控占用的资源太大了,可以如下降低资源占用,当然也可以web操作限制资源利用率
oc env rc hawkular-cassandra-1 MAX_HEAP_SIZE=1024M -n openshift-infra #重建下变量才会生效 oc scale rc hawkular-cassandra-1 --replicas 0 -n openshift-infra oc scale rc hawkular-cassandra-1 --replicas 1 -n openshift-infra因为是rc,所以直接杀掉没关系,要不env不生效
-
自己编译离线文档
# 下载源文件 git clone --depth=1 https://github.com/openshift/openshift-docs.git # 编译 cd openshift-docs && asciibinder build # 结果会存放在 _preview下, cd _preview && python -m SimpleHTTPServer #打开浏览器访问127.0.0.1:8000推荐此人blog,有几篇干货
3.后面会重点说下权限/资源管理和整个app开发的流程
2 - 权限资源管理
介绍openshift的账户、权限、资源配额管理。
重点介绍 project,limitRange,resourceQuta和 user, group, rule,role,policy,policybinding的关系, 我刚接触时,这几个概念老搞不太清楚,这里梳理下
资源管理说明
可以对计算资源的大小和对象类型的数量来进行配额限制。
ResourceQuota是面向project(namespace的基础上加了些注解)层面的,只有集群管理员可以基于namespace设置。
limtRange是面向pod和container级别的,openshift额外还可以限制 image, imageStream和pvc,
也是只有集群管理员才可以基于project设置,而开发人员只能基于pod(container)设置cpu和内存的requests/limits。
ResourceQuota
看看具体可以管理哪些资源,期待网络相关的也加进来.简单来讲,可以基于project来限制可消耗的内存大小和可创建的pods数量
// The following identify resource constants for Kubernetes object types
const (
// Pods, number
ResourcePods ResourceName = "pods"
// Services, number
ResourceServices ResourceName = "services"
// ReplicationControllers, number
ResourceReplicationControllers ResourceName = "replicationcontrollers"
// ResourceQuotas, number
ResourceQuotas ResourceName = "resourcequotas"
// ResourceSecrets, number
ResourceSecrets ResourceName = "secrets"
// ResourceConfigMaps, number
ResourceConfigMaps ResourceName = "configmaps"
// ResourcePersistentVolumeClaims, number
ResourcePersistentVolumeClaims ResourceName = "persistentvolumeclaims"
// ResourceServicesNodePorts, number
ResourceServicesNodePorts ResourceName = "services.nodeports"
// ResourceServicesLoadBalancers, number
ResourceServicesLoadBalancers ResourceName = "services.loadbalancers"
// CPU request, in cores. (500m = .5 cores)
ResourceRequestsCPU ResourceName = "requests.cpu"
// Memory request, in bytes. (500Gi = 500GiB = 500 * 1024 * 1024 * 1024)
ResourceRequestsMemory ResourceName = "requests.memory"
// Storage request, in bytes
ResourceRequestsStorage ResourceName = "requests.storage"
// CPU limit, in cores. (500m = .5 cores)
ResourceLimitsCPU ResourceName = "limits.cpu"
// Memory limit, in bytes. (500Gi = 500GiB = 500 * 1024 * 1024 * 1024)
ResourceLimitsMemory ResourceName = "limits.memory"
)
openshift额外支持的images相关的限制策略
// ResourceImageStreams represents a number of image streams in a project.
ResourceImageStreams kapi.ResourceName = "openshift.io/imagestreams"
// ResourceImageStreamImages represents a number of unique references to images in all image stream
// statuses of a project.
ResourceImageStreamImages kapi.ResourceName = "openshift.io/images"
// ResourceImageStreamTags represents a number of unique references to images in all image stream specs
// of a project.
ResourceImageStreamTags kapi.ResourceName = "openshift.io/image-tags"
此外,除了可以设置额度Quantity外,还可以指定配额的作用范围Scopes,其实就是作用于哪类pod上的:
- 是否是长期运行的pod
- 是否有资源上限的pod
目前只有pods数和计算资源(cpu,内存)才能指定作用域
// A ResourceQuotaScope defines a filter that must match each object tracked by a quota
type ResourceQuotaScope string
const (
// Match all pod objects where spec.activeDeadlineSeconds,这个是标明pod的运行时长参数
ResourceQuotaScopeTerminating ResourceQuotaScope = "Terminating"
// Match all pod objects where !spec.activeDeadlineSeconds , 长期运行的pod
ResourceQuotaScopeNotTerminating ResourceQuotaScope = "NotTerminating"
// Match all pod objects that have best effort quality of service, 只能用来描述资源无上限的pod数
ResourceQuotaScopeBestEffort ResourceQuotaScope = "BestEffort"
// Match all pod objects that do not have best effort quality of service, 资源有上限的pod
ResourceQuotaScopeNotBestEffort ResourceQuotaScope = "NotBestEffort"
)
下面举个例子
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources-long-running
spec:
hard:
pods: "4"
limits.cpu: "4"
limits.memory: "2Gi"
scopes:
- NotTerminating
上面的意思即是, 限制长期运行的pod最多只能创建4个,且共用4c和2G内存
如果不指定scopes的话,是描述的所有scopes的限制;
本文参考这里
可以看到,通过资源配额管理,可以帮助我们解决以下问题:
-
控制计算资源使用量
我们在实际生产环境中经常遇到的情况是,用户申请了过多的资源,用户应用的资源使用率太低,造成了资源的浪费。管理员通常会给集群设置超卖系数,来提高整个集群的资源使用率;另外管理员也会给用户设置资源配额上限,来限制用户使用资源的数量。通过上面的介绍我们可以看到,kubernetes的资源配额,我们可以从应用的层次上来进行配额管理,可以设置不同应用的资源配额上限。
-
控制besteffort类型POD资源使用量
如果POD中的所有容器都没有设置request和limit,那么这些POD的QoS类型是besteffort,这种类型的POD更方便kubernetes进行调度,但是存在的问题是,如果不对这些POD进行资源管理,那么就会导致这个kubernetes集群资源过载,会影响这个集群中的所有应用,所以通过将资源配额管理的作用范围设置成besteffort,kubernetes可以通过限制这些POD的资源,避免整个集群资源过载。
-
控制长期运行的应用和短暂运行的应用资源使用率
在实际使用中,在kubernetes集群中会同时存在两种类型的应用,一种是长期运行的应用,比如网站这种web应用,还有一种就是短暂运行的应用,比如编译网站的这种应用。通过资源配额管理,可以同时对这两种不同类型的应用设置资源使用上限,来控制不同应用的资源使用。
LimitRange
limtRange是面向pod和container级别的,为什么只能集群管理员才可设置呢,因为这个的提出是为了防止有些应用忘记加资源边界的限定,而占用过多的资源,那么有了limitRange就给它来个默认限制。
apiVersion: "v1"
kind: "LimitRange"
metadata:
name: "core-resource-limits"
spec:
limits:
- type: "Pod"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "200m"
memory: "6Mi"
- type: "Container"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "100m"
memory: "4Mi"
default:
cpu: "300m"
memory: "200Mi"
defaultRequest:
cpu: "200m"
memory: "100Mi"
maxLimitRequestRatio:
cpu: "10"
- type: "openshift.io/Image"
max:
storage: "1Gi"
- type: "openshift.io/ImageStream"
max:
openshift.io/image-tags: "10"
openshift.io/images: "12"
如上使用oc create后,会看到我们对某namespace下的pod和container做了默认的资源设置,

权限管理说明
这里不涉及到认证登录的介绍,openshfit支持很多认证方式,比如AllowAll,CA认证, HTPasswd, KeyStone, LDAP, Oauth等,这里为了简化,用默认的AllowAll来做权限控制的说明
权限管理,即访问API资源之前,必须要经过的访问策略校验,主要分为5种: AlwaysDeny、AlwaysAllow(默认)、ABAC、RBAC、Webhook
主要说明user, group, rule,role,policy,policybinding之间的关系,以及提出这些概念,各自是为了解决什么问题
- user和group
说到user其实就是一个用户账号(userAccount),用它来和k8s集群做交互(登录,kubectl等), 但还有一个容易混淆的概念就是sercieAccount,有了userAccount为什么还又来个serviceAccount的设计, 这两者有什么区别 ? 以下是kubernetes官方对两者的解释
user account是为人类设计的,而service account则是为跑在pod里的进程用的,运行在pod里的进程需要调用Kubernetes API以及非Kubernetes API的其它服务(如image repository/被mount到pod上的NFS volumes中的file等);
user account是global的,即跨namespace使用;而service account是namespaced内的,即仅在所属的namespace下使用;
user account可能会涉及到很多权限设定和商业逻辑在里面,而后者是更轻量级的,是集群用户针对某namespace内的服务使用的,一般遵循最小特权原则,如监控服务需要访问APIsever等;
useraccount需要借助第三方实现,后者系统都会默认在namesspace里创建default,亦可自定义
两者大部分流程是一致的,都是要先认证通过再校验权限,然后才是action, 实际上一般是由userAccount来控制serviceAccount来完成特定的任务, 比如一个用户A自建了服务1和服务2, 但只想把服务2开发给用户B,这样的serviceAccount就可以排上用场了, 又或者我有几个服务,有了serviceAccount就可以来限制用户的访问权限(list, watch, update, delete)了.
说到group就是方便对user的权限批量操作而设计;
用户可以被分配到一个或多个组,每个组代表一组特定的用户。组在同时向多个用户管理权限时非常有用。
- rule和role
rule是规则, 是对一组对象上被允许的动作(get, list, create, update, delete, deletecollection 和 watch)描述,可操作对象主要是 container,images,pod,servcie, project, user, build, imagestream, dc, route, templeate。
role 就是规则的集合,俗称角色, 不同对象上的不同动作,可以任意组成各种角色,系统默认的有 admin basic-user cluster-admin cluster-admin edit self-provisioner view;
policy,是策略, 保存特定namespace的所有角色roles的对象。 每个命名空间最多只有一个Policy策略。
rolebinding, 就是把user或者group与角色role进行关联,注意. user和group可以被关联到多个roles
pollicybing, 就是就是多个rolebindings的描述;
这样看,policy的概念提出有点儿扯淡了,感觉没什么用,其实不然,policy的提出主要是为了区分cluster-policy和local-policy的。
cluster policy是适用于所有namespace的角色和绑定; local policy则是试用于具体的某个namespace的;
以上可以通过oc describe clusterPolicy default来看查看所有详细的信息;
小节:
可以通过oc policy can-i --list查看自己可以干些什么
还可以通过oc policy who-can <动作> <资源对象>, 比如说查看谁能get pod之类的,就是oc policy who-can get pod
➜ openshift-docs git:(master) ✗ oc policy who-can get pod
Namespace: myproject
Verb: get
Resource: pods
Users: developer
system:admin
system:serviceaccount:default:pvinstaller
system:serviceaccount:myproject:deployer
system:serviceaccount:openshift-infra:build-controller
system:serviceaccount:openshift-infra:deployment-controller
system:serviceaccount:openshift-infra:deploymentconfig-controller
system:serviceaccount:openshift-infra:endpoint-controller
system:serviceaccount:openshift-infra:namespace-controller
system:serviceaccount:openshift-infra:pet-set-controller
system:serviceaccount:openshift-infra:pv-binder-controller
system:serviceaccount:openshift-infra:pv-recycler-controller
Groups: system:cluster-admins
system:cluster-readers
system:masters
system:nodes
如果openshift自带的角色不能满足的话,还可以自定义角色role
$ oc get clusterrole view -o yaml > clusterrole_view.yaml
$ cp clusterrole_view.yaml localrole_exampleview.yaml
$ vim localrole_exampleview.yaml
# 1. Update kind: ClusterRole to kind: Role
# 2. Update name: view to name: exampleview
# 3. Remove resourceVersion, selfLink, uid, and creationTimestamp
$ oc create -f path/to/localrole_exampleview.yaml -n <project_you_want_to_add_the_local_role_exampleview_to>
下文介绍实战,结合实际场景,如何设置权限,即整个开发管理流程实践说明
3 - 项目开发实战
介绍openshift的项目开发实战。
下面的所有操作,都可以通过cli,web console,RestFul API实现,默认使用cli说明
创建项目
这里是接着oc cluster up后,来说的, 默认oc whoami是 developer,拥有admin的Role角色,俗称项目经理(管理员)
- 删除默认创建的项目,并创建一个实际中的项目
oc delete project myproject
oc new-project eshop --display-name="电商项目" --description="一个神奇的网站"
现在项目管理员可以创建任意多个项目,从前面的源码可以看到目前是没法针对项目管理员去限制可创建项目上限的。
- 查看项目状态
#oc status
In project 电商项目 (eshop) on server https://192.168.31.49:8443
You have no services, deployment configs, or build configs.
Run 'oc new-app' to create an application.
空空如也,有提示语句提示可通过oc new-app去创建具体应用的
创建应用
前面也说过,openshift的核心就是围绕应用的整个生命周期来的,所以从new-app说起
new-app的入口是NewCmdNewApplication(), 大部分实现是 func (c *AppConfig) Run() (*AppResult, error) 感兴趣的可以根据源码来理解openshift的devops理念。
- 创建应用的方式 现在可以通过3种方式(源码, docker镜像, 模板)来创建一个应用。
# oc new-app -h
#此处省略。。。
Usage:
oc new-app (IMAGE | IMAGESTREAM | TEMPLATE | PATH | URL ...) [options]
#此处省略。。。
有很多灵活简便的方式来创建应用,甚至可以直接oc new-app mysql来创建一个mysql服务
比如下面的例子,是基于nodejs-ex项目的master分支,创建应用
oc new-app https://github.com/xiaoping378/nodejs-ex.git#master
接着上面的nodejs-ex项目来说, 实际上,oc new-app就做了两件事,先build, 再deploy。
new-app一般会先创建一个bc, bc会产出一个iamge,new-app典型的还会创建一个dc,去部署新生成的image,也会创建相应的service来负载均衡方访问刚部署上的镜像里的业务。
这一切都是自动完成的,因为openshift origin里面有一些检测机制和默认规则,下面就针对上面那条命令看看内部都发生了什么
-
首先openshift会执行
git ls-remote, 来查看此项目的所有remote分支,如果存在master分支,下一步则直接clone和checkout了
checkout后,接着就是根据解析规则来定义如何build了。
-
build策略
首先会探测nodejs-ex项目根目录下,是否有dockerfile或者jenkinsfile,如果两者都没有则会根据“典型文件”判断这个项目的开发语言, 举例
如果存在app.json或者package.json文件,则认为是nodejs类型的项目, 更多的典型文件如下:
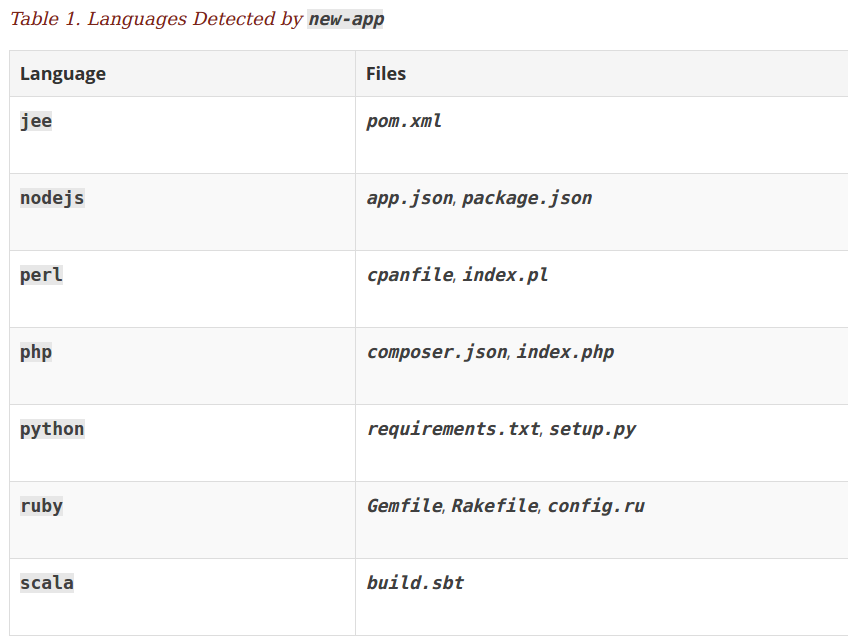
这部分的代码实现主要在 detector.go
未完,待续。。。
4 - DevOps实战-0
介绍openshift的DevOps实战-0。
主要涉及到一键发布,快速回滚,弹性伸缩,蓝绿部署方面。
-
启动openshift
oc cluster up --version=v1.5.0-rc.0 --metrics --use-existing-config=true默认负责监控的pods占用资源太大了,可以这样限制下,或者cluster up时不加
--metricsoc login -u system:admin oc env rc hawkular-cassandra-1 MAX_HEAP_SIZE=1024M -n openshift-infra #重建下,变量才会生效 oc scale rc hawkular-cassandra-1 --replicas 0 -n openshift-infra oc scale rc hawkular-cassandra-1 --replicas 1 -n openshift-infra -
建立本地Git仓
默认官方给出的例子基本都需要和Github结合,实在不好本地实战演示,所以本地要来一个
gogs代码仓。oc login -u devloper oc new-project ci #先拉取所依赖镜像 docker pull openshiftdemos/gogs:0.9.97 docker pull centos/postgresql-94-centos7 #创建gogs服务,并禁用webhook时的TLS校验,不然无法触发build oc new-app -f https://raw.githubusercontent.com/xiaoping378/gogs-openshift-docker/master/openshift/gogs-persistent-template.yaml -p SKIP_TLS_VERIFY=true -p HOSTNAME=gogs-ci.192.168.31.49.xip.io上面的HOSTNAME,注意要换成自己宿主机的IPv4地址,默认创建的其他服务的路由都是这个形式的,
有个有意思的地方,为什么默认路由会是这种
name+IP+xip.io形式呢,奥秘在 http://xip.io 的公共服务上。 这其实是个特殊的域DNS server,比如我们查询域名gogs-ci.192.168.31.49.xip.io时 ,会返回192.168.31.49的地址回来, 而这个地址恰好是我们Router的地址,这样子Router会根据route的配置负责负载到对应的POD上。自己试验下就知道怎么回事了。dig http://gogs-ci.192.168.31.49.xip.io +short只做功能性演示,先不考虑https加密安全访问,创建完后,访问gogs服务
http://gogs-ci.192.168.31.49.xip.io
这个项目,第一个注册用户即为管理员,比如我现在去页面注册一个叫
developer的用户。 -
找个项目来实战吧
-
克隆远程项目,并设置
git clone https://github.com/xiaoping378/nodejs-ex.git && cd nodejs-ex git remote add gogs http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git -
通过web页面,在gogs上创建一个
nodejs-ex仓库, 并如下push刚才克隆的项目$ git push gogs master Username for 'http://gogs-ci.192.168.31.49.xip.io': developer Password for 'http://developer@gogs-ci.192.168.31.49.xip.io': Counting objects: 431, done. Delta compression using up to 4 threads. Compressing objects: 100% (210/210), done. Writing objects: 100% (431/431), 145.16 KiB | 0 bytes/s, done. Total 431 (delta 159), reused 431 (delta 159) To http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git * [new branch] master -> mastergogs的页面上会如实反馈信息
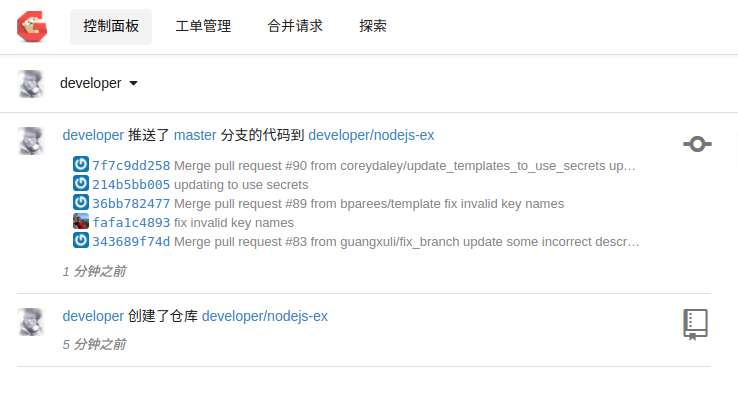
OK,现在本地项目就有了,接下来进入正题
-
-
在openshift部署此nodejs应用
#创建web namespace oc new-project web #先拉取依赖镜像 docker pull centos/mongodb-32-centos7 docker pull centos/nodejs-4-centos7 #部署此项目,并启用国内npm源和对应的git仓 oc new-app nodejs-mongo-persistent --name=nodejs-ex -p NPM_MIRROR=https://registry.npm.taobao.org -p SOURCE_REPOSITORY_URL=http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git默认此模板会从指定的URL地址拉取代码,并根据预先的配置,采取
Source编译策略,基于istag nodejs:4镜像编译出nodejs-mongo-persistent:latest镜像,编译出来的镜像又会自动触发部署。 -
最基本的DevOps能力
即push代码通过webhook触发自动编译,继而滚动部署
要实现这个目标前,需要先把webhook填写到gogs里。
在openshift界面上复制webhook地址
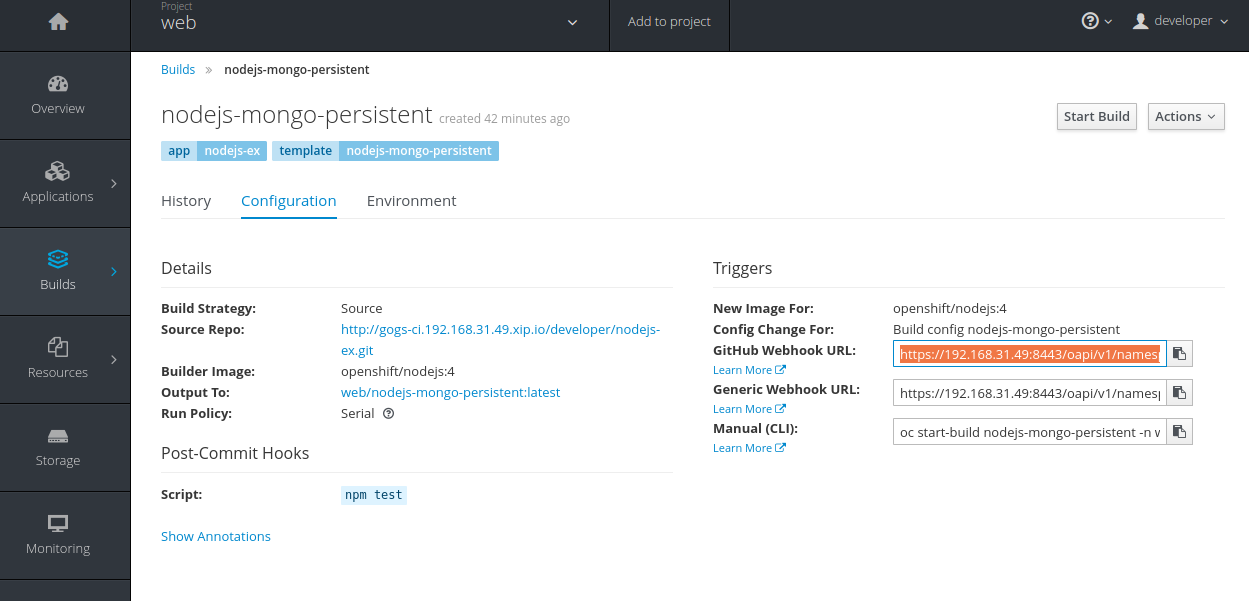
然后在gogs上填加一个webhook
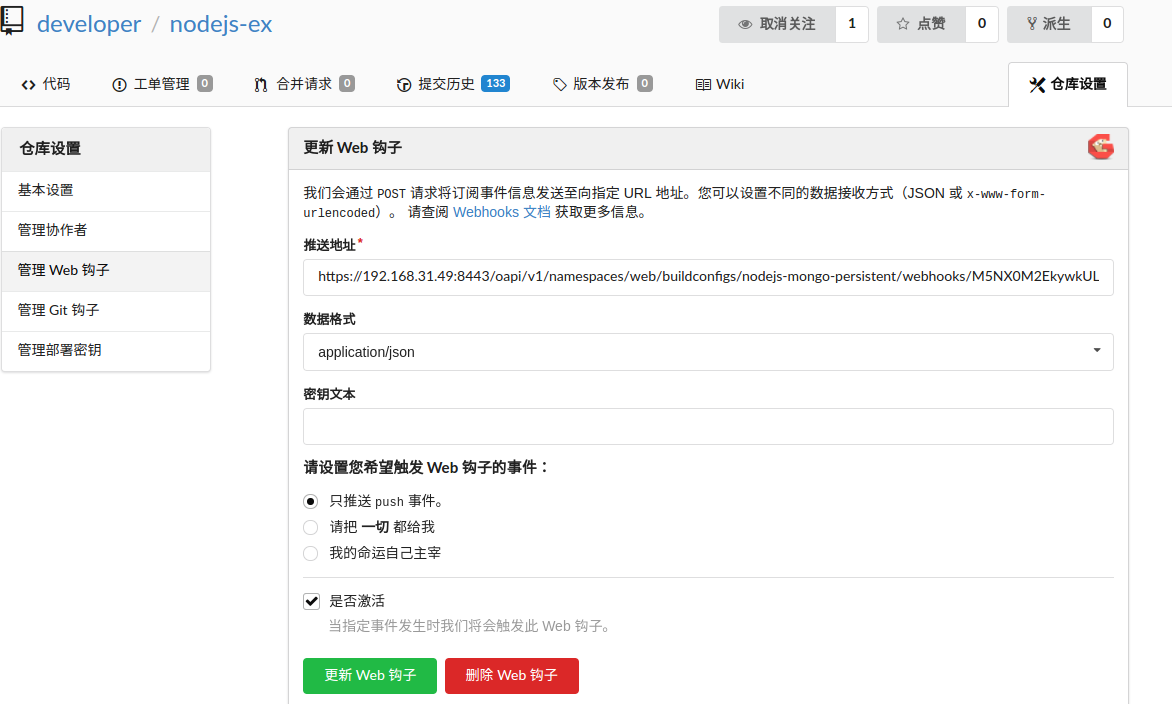
这里我们随意修改些,然后推送代码,就会自动触发编译并滚动升级
➜ nodejs-ex git:(master) vim views/index.html ➜ nodejs-ex git:(master) ✗ git add . ➜ nodejs-ex git:(master) ✗ git commit -m "这又是个测试" [master 082f05e] 这又是个测试 1 file changed, 1 insertion(+), 1 deletion(-) ➜ nodejs-ex git:(master) git push gogs master Username for 'http://gogs-ci.192.168.31.49.xip.io': developer Password for 'http://developer@gogs-ci.192.168.31.49.xip.io': Counting objects: 4, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (4/4), 365 bytes | 0 bytes/s, done. Total 4 (delta 2), reused 0 (delta 0) To http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git c3592e6..082f05e master -> master编译成功后,会产生新镜像,继而触发滚动升级的截图
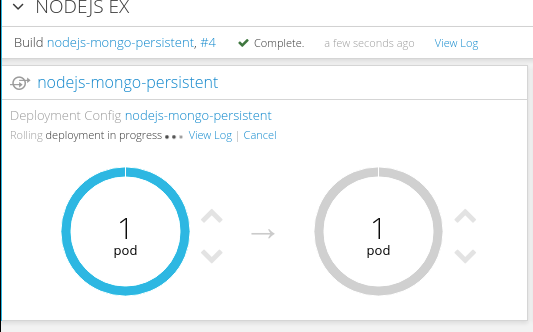
现实中,如果项目没有很好的自动化测试的话,我们肯定不会这样操作的,除非想被开掉了。
其实可以简单的去掉webhook,采用手动触发build: 界面操作的话,去build界面点击
Start Build,命令行的话如下oc start-build nodejs-mongo-persistent另外,如果发现新版本的应用有重大缺陷,想回滚以前的部署版本,也有对应的界面和命令
oc rollback nodejs-mongo-persistent --to-version=3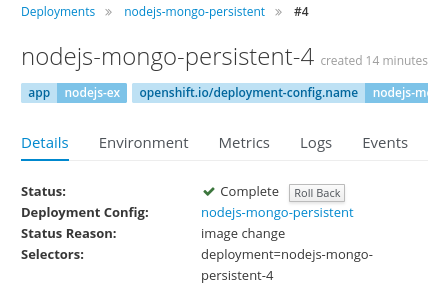
-
弹性伸缩
目前可以根据CPU使用率来进行弹性伸缩
有人问能不能基本mem进行弹性呢,其实这个是没什么意义的,一般应用都会自行缓存,内存基本只增不长, 所以cpu才能很好的实时反应业务的负载。
弹性伸缩前,要确保应用先行设置了cpu request,这点还没明白原因,为什么要这样,按理说,heapster一直会采集pod的资源使用情况的,HPA周期拿数据和设置的阈值对比就完了。
这里是部署界面的菜单栏,可以手动加上cpu request
添加 cpu request.
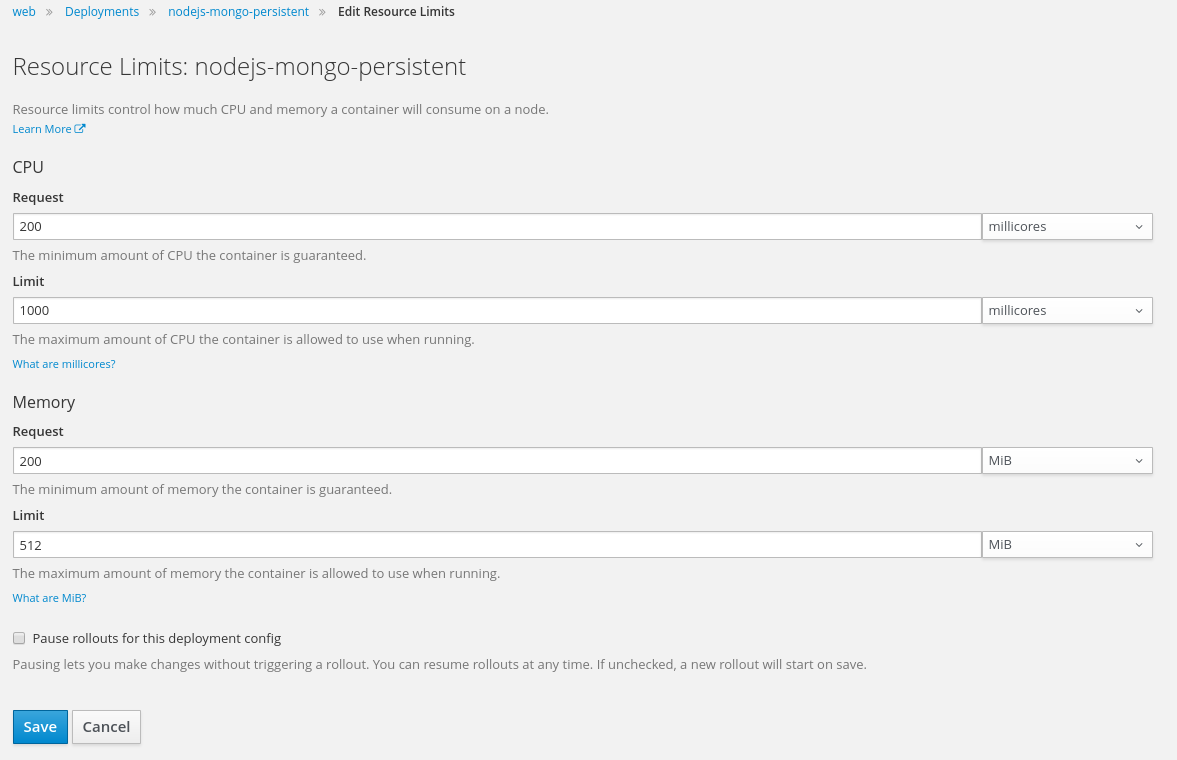
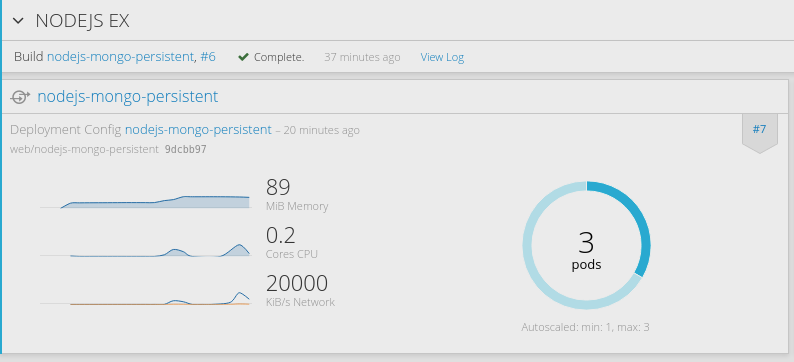
然后开启弹性伸缩特性,这里就不截图了,展示下命令行,我们设置成: 当cpu使用率达到80%时,就弹,最大可以弹出3个实例
oc autoscale dc/nodejs-mongo-persistent --max=3 --cpu-percent=80OK,之后我们通过ab工具简单做个压力模拟,因为环境在我的笔记本上,所以只模拟发送100万个连接,并发100的量
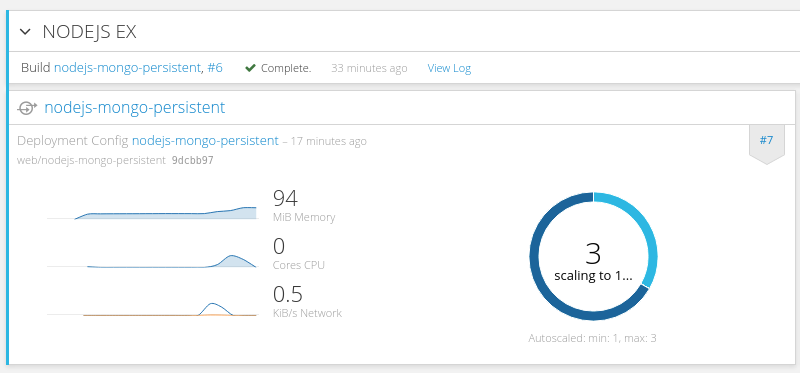
ab -n 1000000 -c 100 http://nodejs-mongo-persistent-web.192.168.31.49.xip.io/后台每1分钟采集一次cpu使用率,过不了一会儿,就会看到nodejs实例自动扩展了
当业务量降下来时,会自动减少实例,是根据平均CPU使用率来操作的。
-
蓝绿部署
这个也是API级别的支持,不描述具体操作细节了,原理还是以前的,从负载均衡层面入手。 实现新旧版本同时存在。 并不是所有业务都适合蓝绿部署的,要看后台数据是否允许,新旧版本同时发生读写数据
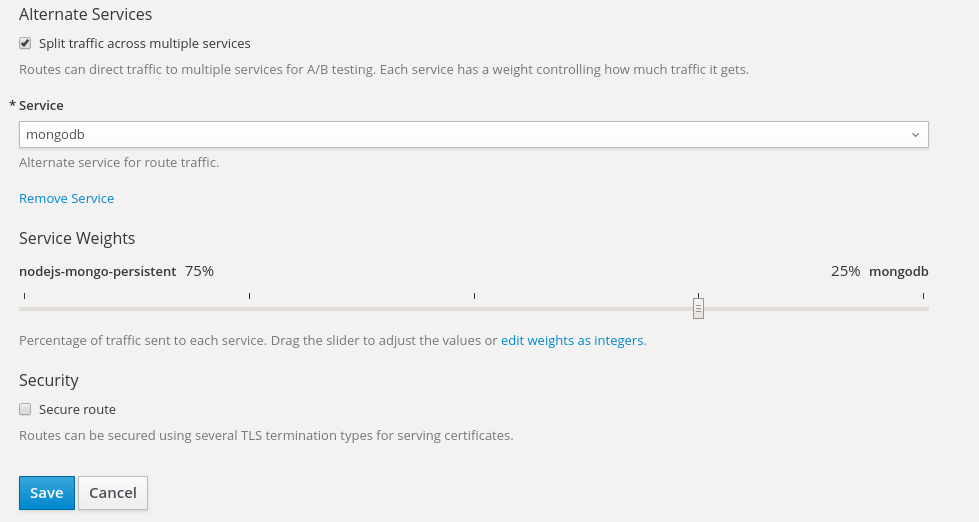
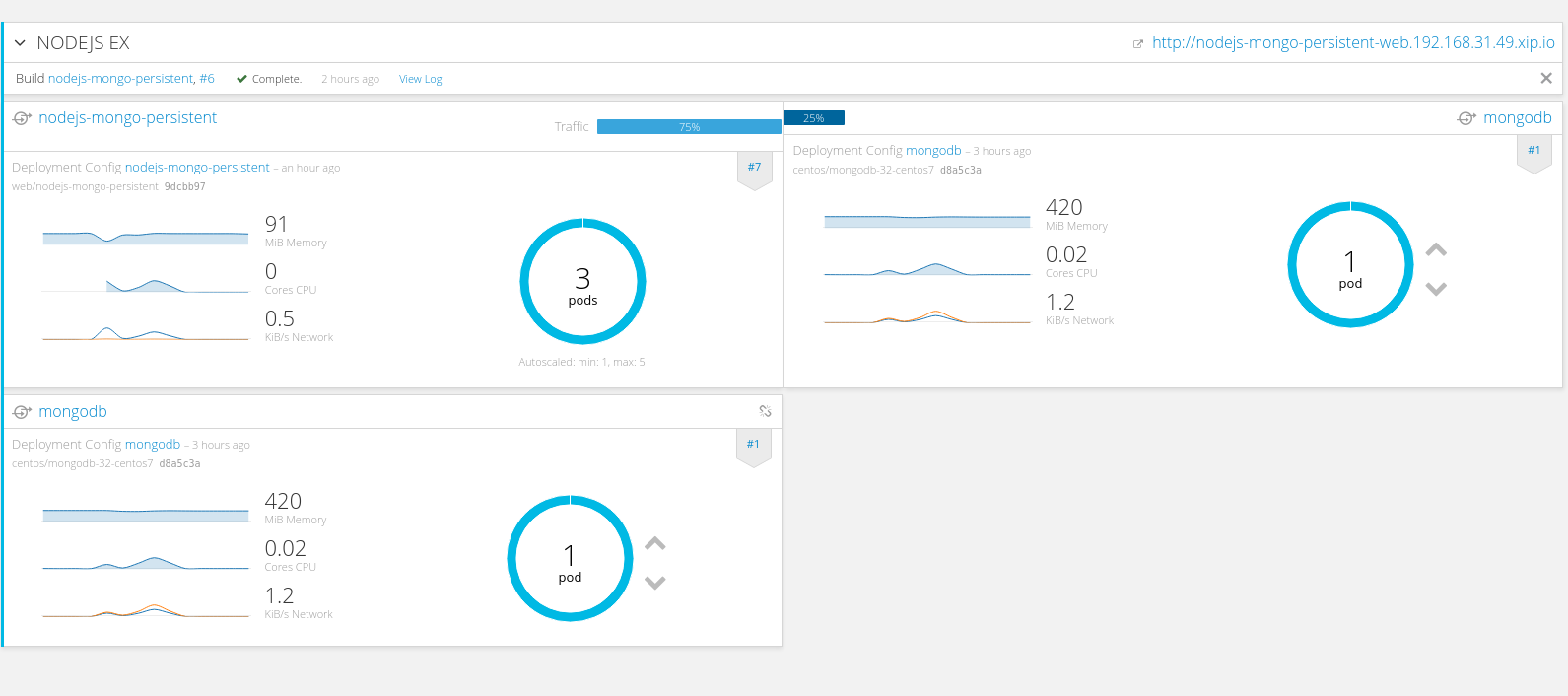
在openshift里实现蓝绿部署的,就太简单了。具体就是在Route层面添加同一应用的多个版本的service,并设置分流权重 截图如下
界面设置,只是为了展示功能,我随便添加了个service
实际展示效果
总结
Openshift平台本身在API层面实现了DevOps,所以基于它很容易做到DevOps as an service, 上面的演示可能与现实世界不太一样,
比如真实情况是有,测试,预发布,线上环境的,下次再分享: openshift基于jenkins pipeline如果实现更真实场景的需求。
5 - DevOps实战-1
介绍openshift的DevOps实战-1。
本文主要介绍基于openshift如何完成开发->测试->线上场景的变更,这是一个典型的应用生产流程,来看看openshift是如何利用容器优雅的完成整个过程的吧
下文基于上篇DevOps实战-0 的nodejs-ex项目来说, 假设到这里,你本地已经有了nodejs-ex项目
准备3个project
用这3个project来模拟开发,测试,线上环境
现实中一般各个场景的服务器都是物理隔离的,这里可以利用--node-selector,来指定项目可以跑在哪些节点上。
oc login -u sysetm:admin
#晚上在笔记本上写此blog,没合适的环境,单机模拟多台 -- start
oc label node 192.168.31.49 web-prod=true web-dev=true web-test=true
#晚上在笔记本上写此blog,没合适的环境,单机模拟多台 -- end
#1.创建web-dev项目
#2.授权developer为开发组项目管理员
#3.授权测试和运维人员可以从开发组拉取镜像
oc adm new-project web-dev --node-selector='web-dev=true'
oc policy add-role-to-user admin developer
oc policy add-role-to-group system:image-puller system:serviceaccounts:web-test -n web-dev
oc policy add-role-to-group system:image-puller system:serviceaccounts:web-prod -n web-dev
oc adm new-project web-test --node-selector='web-test=true'
oc policy add-role-to-user admin tester
oc adm new-project web-prod --node-selector='web-prod=true'
oc policy add-role-to-user admin ops
-
你可能会注意到,这里用的
new-project前面还加了adm, 其实oc adm等效于oadm, 一般管理集群相关的用这个命令,这里是因为需要读取节点的标签(label)信息。 -
指定项目要运行那些节点,则是利用了注解-annotations, 即在原有的project结构上设置了注解,这样openshift在相应的项目里创建任何pod时,都对会自动注入node-selector
-
另外需要注意的,默认项目的管理员(developer)是没有权限读取node标签信息的,以前写过权限管理相关blog,集群管理员可以授权node访问权限,即使如此developer还是不能改写项目级别的标签的,举个例子: developer在开发环境的pod上指定了
--node-selector='web-dev=false', 最终这个pod的node-selector会是'web-dev=true, web-dev=flase', 导致最终不会被调度到任何节点上。 -
上面分别授权了3个用户,这里是不关心这些用户是否真实存在的,只是一个RABC的描述,因为是
oc cluster up起来的环境,默认使用anypassword的身份认证,所以登录时,任意用户名和密码都是可以登录OK的。 -
通过
oc describe policybinding -n web-dev可以查看授权情况, 如果觉得默认的role不满足需求的话,也可以自定义role,另外通过oc policy remove-role-from-group/user <Role> <name>可以移除相关授权,
初始化web-dev, web-test, web-prod环境
按照上篇DevOps实战-0里的方式
初始化我们的开发环境, 进入源码nodejs-ex目录
oc new-app -f openshift/template/nodejs-mongo-persistent.json --name=nodejs-ex \
-p NPM_MIRROR=https://registry.npm.taobao.org \
-p SOURCE_REPOSITORY_URL=http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git \
-n web-dev
初始化测试环境,相较于上一步的模板json,只是注掉bc和更改了triggers的is,后面会详细介绍之间的差异
oc new-app -f openshift/template/nodejs-mongo-persistent-test.json --name=nodejs-ex-test -n web-test
以tester登录web console,会发现只有mongodb部署上了,而前端nodejs还在等待依赖的镜像 web-dev/nodejs-mongo-persistent:test。
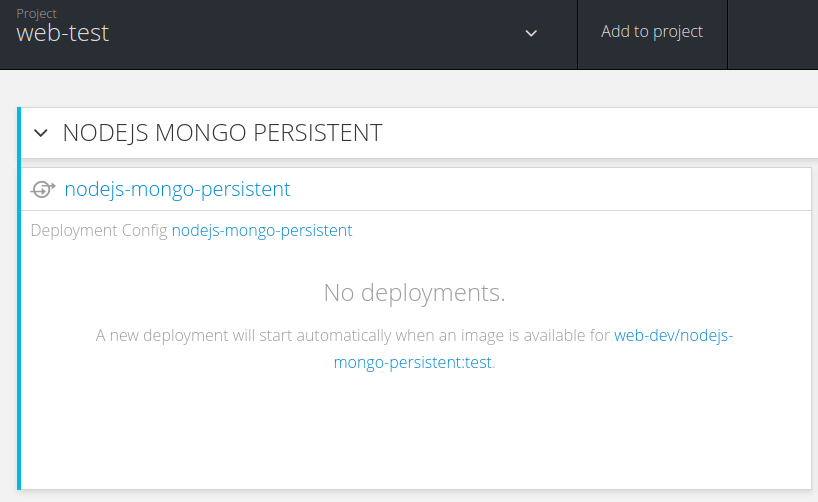
初始化生产环境, 这个生产的template.json有点儿简单,负载均衡和弹性伸缩都没有启用。
oc new-app -f openshift/template/nodejs-mongo-persistent-prod.json --name=nodejs-ex-prod -n web-prod
实战模拟,开发->测试->发布
-
developer开发完特性或者修复完bug,push代码到镜像仓。
这里分享一个很方便的技巧,就是
oc rsync, 这个可以实时的同步本地目录到容器了,避免了频繁编译镜像和临时挂载目录到镜像里的hack了。vim ... git add . git commit -m "fix bugs" git push gogs master如上,由于上篇中设置了webhook, developer提交代码会触发了自动编译并部署,确认部署后的环境是否修复了bug,如果单元测试通过,那就要通知测试团队(如今大部分公司,应该没有测试人员了吧,也可以直接变更到线上)
测试那边的环境里一直在等待这个镜像
web-dev/nodejs-mongo-persistent:test, 而默认developer配置成默认编译出来的是web-dev/nodejs-mongo-persistent:latestoc login -u developer oc tag web-dev/nodejs-mongo-persistent:latest web-dev/nodejs-mongo-persistent:v1.1 oc tag web-dev/nodejs-mongo-persistent:v1.1 web-dev/nodejs-mongo-persistent:test如上操作后,开发人员更新版本号,然后在web-dev环境里会打上一个test的镜像tag出来,操作完如下所示
➜ nodejs-ex git:(master) oc get is NAME DOCKER REPO TAGS UPDATED nodejs-mongo-persistent 172.30.1.1:5000/web-dev/nodejs-mongo-persistent test,v1.1,latest 49 seconds ago ➜ nodejs-ex git:(master) ➜ nodejs-ex git:(master) oc get istag NAME DOCKER REF UPDATED IMAGENAME nodejs-mongo-persistent:latest 172.30.1.1:5000/web-dev/nodejs-mongo-persistent@sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 3 minutes ago sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 nodejs-mongo-persistent:v1.1 172.30.1.1:5000/web-dev/nodejs-mongo-persistent@sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 2 minutes ago sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 nodejs-mongo-persistent:test 172.30.1.1:5000/web-dev/nodejs-mongo-persistent@sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 55 seconds ago sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7这样一来,测试环境里就会自动部署上刚才开发人员的环境了,再也不会有因为环境差异问题和测试吵吵了。
这一切都得益于openshift里新添加的imageStreams,它打通了编译和部署的环节,能自动通知对方,继而自动触发下一步动作。
测试通过后,通知Ops再重新tag成线上所需要的镜像tag,这样线上就会根据配置自动滚动升级了。
#假设一个叫ops的人负责上线,那首先ops得有具备web-dev项目里编辑is的能力 oc login -u developer #不该给ops这么高权限的,应该自定义一个只能tag is的role,这里为了简单演示 oc policy add-role-to-user edit ops -n web-dev如上操纵,ops就具备了tag web-dev项目的镜像的能力,也可以通过UI来查看和授权
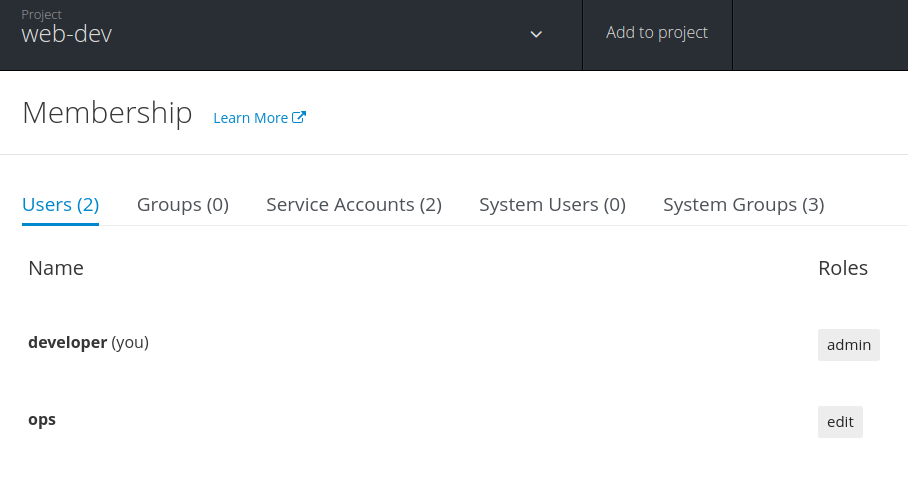
oc login -u ops oc tag web-dev/nodejs-mongo-persistent:v1.1 web-dev/nodejs-mongo-persistent:prod然后打上线上依赖的镜像tag即可,发布上线,这样就完成了开发->测试->发布一条线,很快捷的
人工干预上线了
总结
openshift 利用镜像tag的能力,来实现不同场景的同步,单纯基于docker也可以实现以上目标的,只是不够平台化,还是以前的脚本打天下,远不如openshift在API层面解决来的强大和灵活。
6 - 编译和目录结构介绍
介绍openshift的编译和目录结构介绍。
介绍openshift的源码编译和目录结构组织,为了方便代码调试和了解大型Golang项目的构建方式
编译
无论是openshift还是Kubernetes等大型Golang项目都用到了Makefile, 所以有必要从此开始说起,这里只说项目里用到的makefile特性,想了解更多的可以参考跟我一起写Makefile
Makefile介绍
makefile 关系到了整个工程的编译规则。一个工程中的源文件不计数,其按类型、功能、 模块分别放在若干个目录中,makefile 定义了一系列的规则来指定,哪些文件需要先编译, 哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为 makefile 就像一个 Shell 脚本一样,其中也可以执行操作系统的命令。 makefile 带来的好 处就是——“自动化编译”,一旦写好,只需要一个 make 命令,整个工程完全自动编译, 极大的提高了软件开发的效率。
Makefile里的规则,就在做两件事,一个是指明依赖关系,另一个是生成目标的方法
Golang项目里用到的Makefile规则比较简单,基本就是定义一个目标的生成方法,下面的示例是Openshift项目里makefile中定义的第一个目标。
all build:
hack/build-go.sh $(WHAT) $(GOFLAGS)
.PHONY: all build
-
all build,是定义的目标,看到这个就知道可以在源码的根目录上执行make all build来编译了 -
第二行说明生成目标的方法,就是去hack目录下执行build-go.sh脚本,这里还支持传入一些参数
-
第三行
.PHONY,起到一个标识的作用,没什么实际意义,是用来告诉make命令,这里是个伪目标,也可以说成是默认目标,所以在openshift的根目录上直接执行make, 等效于make all build
还可以自己决定是否编译出镜像或者rpm包(make release, make build-rpms)
编译openshift
上边介绍了,直接敲make就可以自动编译出所有平台(linux, mac, windows)的二进制,编译前介绍两个hack方法,
-
在hack/build-go.sh的第二行加上
set -x, 这样的话,shell脚本在运行时,里面的所有变量和执行路径会全部打印出来,一目了然,不用自己一行一行的加echo debug了 -
如下修改hack/build-cross.sh,不然会编译出多平台的二进制,花的时间略长啊。。。
# by default, build for these platforms platforms=( linux/amd64 # darwin/amd64 # windows/amd64 # linux/386 )
下面简易说下执行make后,都发生了什么,只会捡关键点说。
➜ origin git:(xxpDev) ✗ make
hack/build-go.sh
# 初始化一大堆变量,关键函数都在common.sh里实现的
source hack/common.sh hack/util.sh hack/lib目录下的所有脚本
# 还会改动GOPATH,然后会在$GOPATH/src/github.com/openshift下建个软连指向origin目录
export GOPATH=_output/local/go
# 最终组合成下面一条最原始的命令,来进行编译
go install \
-pkgdir /home/xxp/Github/src/github.com/openshift/origin/_output/local/pkgdir/linux/amd64 \
-tags ' ' \
-ldflags '-X github.com/openshift/origin/pkg/bootstrap/docker.defaultImageStreams=centos7 \
-X github.com/openshift/origin/pkg/cmd/util/variable.DefaultImagePrefix=openshift/origin \
-X github.com/openshift/origin/pkg/version.majorFromGit=3 \
-X github.com/openshift/origin/pkg/version.minorFromGit=6+ \
-X github.com/openshift/origin/pkg/version.versionFromGit=v3.6.0-alpha.0+83e3250-176-dirty \
-X github.com/openshift/origin/pkg/version.commitFromGit=83e3250 \
-X github.com/openshift/origin/pkg/version.buildDate=2017-04-06T05:34:29Z \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.gitCommit=43a9be4 \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.gitVersion=v1.5.2+43a9be4 \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.buildDate=2017-04-06T05:34:29Z \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.gitTreeState=clean' \
github.com/openshift/origin/cmd/openshift \
github.com/openshift/origin/cmd/oc \
github.com/openshift/origin/pkg/sdn/plugin/sdn-cni-plugin \
github.com/openshift/origin/vendor/github.com/containernetworking/cni/plugins/ipam/host-local \
github.com/openshift/origin/vendor/github.com/containernetworking/cni/plugins/main/loopback
可以看到openshift会编译出5个二进制来,其中3个和网络CNI接口有关,最后会放置到_output/local/bin/linux/amd64, 并作相关的软链接(oadm, kubelet)
所以以后分析程序的切入点就从cmd/openshift和 cmd/oc入手就行了
来看下编译成果
➜ origin git:(xxpDev) ✗ _output/local/bin/linux/amd64/oc version
oc v3.6.0-alpha.0+83e3250-176-dirty
kubernetes v1.5.2+43a9be4
features: Basic-Auth
看到输出v3.6.0-alpha.0+83e3250-176-dirty, 这就是上面编译时传进去的参数。
-X github.com/openshift/origin/pkg/version.majorFromGit=3,意思是说编译文件github.com/openshift/origin/pkg/version.go时,对常量majorFromGit赋值为3
项目目录结构
-- 未完待续
7 - 多负载均衡方案
介绍openshift的多负载均衡方案。
haproxy在openshift里默认有两种用处,一个种负责master的高可用,一种是负责外部对内服务的访问(ingress controller)
平台部署情况:
- 3台master,etcd
- 1台node
- 1台lb(haproxy)
haproxy负载均衡master的高可用
lb负责master间的负载均衡,其实负载没那么大,更多得是用来避免单点故障
Debug介绍
-
默认安装haproxy1.5.18版本,开启debug方法
# 默认systemd对haproxy做了封装,会以-Ds后台形式启动,debug信息是看不到的 systemctl stop harproxy # vi /etc/haproxy/haproxy.cfg log 127.0.0.1 local3 debug # 手动启动haproxy haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -d不知道是不是哪里还需要设置,打印出来的日志,信息并不是不太多
另外浏览
https://lbIP:9000, 可以看到统计信息
配置介绍
-
使用openshift-ansible部署后,harpxy的配置如下
[root@node4 ~]# cat /etc/haproxy/haproxy.cfg # Global settings #--------------------------------------------------------------------- global chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 20000 user haproxy group haproxy daemon log /dev/log local0 info #定义debug级别 # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults #默认配置,后面同KEY的设置会覆盖此处 mode http #工作在七层代理,客户端请求在转发至后端服务器之前将会被深度分板,所有不与RFC格式兼容的请求都会被拒绝,一些七层的过滤处理手段,可以使用。 log global #默认启用gloabl的日志设置 option httplog #默认日志类别为http日志格式 option dontlognull #不记录健康检查日志信息(端口扫描,空信息) # option http-server-close option forwardfor except 127.0.0.0/8 #如果上游服务器上的应用程序想记录客户端的真实IP地址,haproxy会把客户端的IP信息发送给上游服务器,在HTTP请求中添加”X-Forwarded-For”字段,但当是haproxy自身的健康检测机制去访问上游服务器时是不应该把这样的访问日志记录到日志中的,所以用except来排除127.0.0.0,即haproxy自身 option redispatch #代理的服务器挂掉后,强制定向到其他健康的服务器,避免cookie信息过时,仍可正常访问 retries 3 #3次连接失败就认为后端服务器不可用 timeout http-request 10s #默认客户端发送http请求的超时时间, 防DDOS攻击手段 timeout queue 1m #当后台服务器maxconn满了后,haproxy会把client发送来的请求放进一个队列中,一旦事件超过timeout queue,还没被处理,haproxy会自动返回503错误。 timeout connect 10s #haproxy与后端服务器连接超时时间,如果在同一个局域网可设置较小的时间 timeout client 300s #默认客户端与haproxy连接后,数据传输完毕,不再有数据传输,即非活动连接的超时时间 timeout server 300s #定义haproxy与后台服务器非活动连接的超时时间 timeout http-keep-alive 10s #默认新的http请求建立连接的超时时间,时间较短时可以尽快释放出资源,节约资源。和http-request配合使用 timeout check 10s #健康检测的时间的最大超时时间 maxconn 20000 #最大连接数 listen stats :9000 mode http stats enable stats uri / frontend atomic-openshift-api bind *:8443 default_backend atomic-openshift-api mode tcp #在此模式下,客户端和服务器端之前将建立一个全双工的连接,不会对七层(http)报文做任何检查 option tcplog backend atomic-openshift-api balance source #是基于请求源IP的算法,此算法对请求的源IP时行hash运算,然后将结果除以后端服务器的权重总和,来判断转发至哪台后端服务器,这种方法可保证同一客户端IP的请求始终转发到固定定的后端服务器。 mode tcp server master0 192.168.56.100:8443 check server master1 192.168.56.101:8443 check server master2 192.168.56.102:8443 check官方文档介绍的非常详细,感兴趣的可以继续深入研究
Router负责外部对内服务的访问
部署一个Router并实现高可用
router是由harpoxy来承担的, 可以理解成kubernetes里的ingress controller部分,默认跑在容器里。
-
使能 default项目下router,可以访问hostnetwork
oc adm policy add-scc-to-user hostnetwork system:serviceaccount:default:router -
使能其可以查看 label
oc adm policy add-cluster-role-to-user \ cluster-reader \ system:serviceaccount:default:router -
部署1个router, 选择具有标签
router=true的节点# 对节点设置标签 oc label 192.168.56.110 router=true # 部署并指定serviceaccount oc adm router router --replicas=1 --selector='router=true' --service-account=router -
设置router自身的高可用,参考这里
默认使用keepalived实现多个router的高可用,访问router变成访问VIP地址,keepalived再根据权重和健康监测,利用VRRP通告外界后台到底那个router在服务。
# 添加另一个node作为冗余 oc label no 192.168.56.111 router=true oc scale dc router --replicas=2 #绑定serviceaccount特权,因为keepalived要操作iptables oc adm policy add-scc-to-user privileged system:serviceaccount:default:ipfailover #创建keepalived并指定VIP oc adm ipfailover ha-router \ --replicas=2 --watch-port=80 \ --selector="router=true" \ --virtual-ips="192.168.56.170" \ --iptables-chain="INPUT" \ --service-account=ipfailover --create这样,刚才创建的router就自高可用了,通过
192.168.56.170来访问,有一点值得注意,- 按照现在的例子,如果以后还有router做高可用的话,要加上
--vrrp-id-offset=1,保证一个vip用一个独有的vrrp-id。
- 按照现在的例子,如果以后还有router做高可用的话,要加上
Router分片
路由分片的概念,就是集群内有多个router,通过label来负责不同的routes。
这样可以实现一个project独享一个router,或者某几个route独享一个router,再或者大型集群,更多样化的需求,用这个router sharding的概念也可以满足。
我现在还没有具体的场景,先不实践,后续有机会会跟进更新下。
8 - 镜像管理
介绍openshift的镜像管理方案。
刚接触docker时,第一个接触到的应该就是镜像了,docker之所以如此火热,个人认为一大部分原因就是这个镜像的提出,极大的促进了DevOps推广和软件复用的能力。
而openshift对镜像的管理非常强大,直到写这篇blog,我才真正意识到这点,甚至犹豫是不是要放到开发实战篇后再来写镜像管理。
简要说下openshift里使用镜像的情况:
- 首先openshift可以利用任何实现了
Docker registry API的镜像仓,比如,Vmware的Harbor项目,Docker hub以及集成镜像仓( integrated registry) - 集成镜像仓,openshift内部的,可以动态生成,自动让用户编译的镜像有地方存, 其次它还负责通知openshift镜像的变动,然后openshift会根据策略去决定编译其他依赖镜像还是部署应用
- 第三方镜像, 可通过命令
oc import-image <stream>来实时获取镜像tag信息并转换成镜像流,继而触发后续的编译或者部署。 - 当然
oc new-app也支持直接从第三方镜像仓或者本地镜像里启动一个应用
文末有安装集成镜像仓的说明,先介绍image Streams 和 istag的概念和应用场景。
镜像管理
-
openshift基于docker的image概念又延伸出了Image Streams和Image Stream Tags概念
默认openshift项目下会有一些镜像流,是供自带模板里用的,所以想加速部署模板的话,可以在改这里,通过istag指向本地镜像仓。
oc get is -n openshift oc get istag -n openshiftimage,通俗讲就是对应用运行依赖(库,配置,运行环境)的一个打包。
docker pull push, 就是操作的镜像。 为什么openshift还要抽象出is和istag呢,主要是为了打通集成编译和部署环节(bc和dc),原生API就支持了DevOps理念。后面会细讲bc和dcis,开发人员可以理解成git的分支,每个分支都会编译很多临时版本出来,这个就是对应到is~=分支和istag~=版本号。 其实is和istag只是记录了一些映射关系,并不会存放实际镜像数据,比如is里记录了build后要output的镜像仓地址和所有tags,而istag里又记录了具体某个tag与image(可能是存于外部镜像仓,也能是某个is)的关系, 利用此实现了bc/dc和镜像的解耦。
这里通过部署jenkins服务,来初步了解下具体的含义,
- 创建ci项目
oc new-project ci # 先拉取必要镜像 docker pull openshift/jenkins-1-centos7 #通过模板部署,下面一条命令就可以创建一个临时的jenkins服务的 #oc new-app jenkins-ephemeral #跑之前我们先来注意几点- 更改默认的is
先来查看默认的is
oc get template jenkins-ephemeral -n openshift -o json ... "triggers": [ { "imageChangeParams": { "automatic": true, "containerNames": [ "jenkins" ], "from": { "kind": "ImageStreamTag", "name": "${JENKINS_IMAGE_STREAM_TAG}", "namespace": "${NAMESPACE}" }, "lastTriggeredImage": "" }, "type": "ImageChange" }, { "type": "ConfigChange" } ] ... { "name": "NAMESPACE", "displayName": "Jenkins ImageStream Namespace", "description": "The OpenShift Namespace where the Jenkins ImageStream resides.", "value": "openshift" }, { "name": "JENKINS_IMAGE_STREAM_TAG", "displayName": "Jenkins ImageStreamTag", "description": "Name of the ImageStreamTag to be used for the Jenkins image.", "value": "jenkins:latest" } ...可以看到默认模板里部署jenkins时,会从openshfit的namespace里拉取jenkins:latest的镜像, 去openshift项目里找找看,确实存在对应的is
➜ ~ oc get is -n openshift | grep jenkins jenkins 170.16.131.234:5000/openshift/jenkins latest,1 2 days ago ➜ ~ oc get istag -n openshift | grep jenkins:latest jenkins:latest openshift/jenkins-1-centos7@sha256:ab590529e20470e53c1d4b6b970de5d4fd357d864320735a75c1df0e2fffde07 2 days ago sha256:ab590529e20470e53c1d4b6b970de5d4fd357d864320735a75c1df0e2fffde07上面的命令的输出,有两个点要阐述下,
- is里的
170.16.131.234:5000/openshift/jenkins是个可有可无的地址,一般系统会填写集成镜像仓的地址 - 而istag里
openshift/jenkins-1-centos7@sha256:ab则是指明了对应tag的镜像来源,
这样的话,默认执行
oc new-app jenkins-ephemeral的话,会从docker.io那里拉取镜像 openshift/jenkins-1-centos7@sha256:ab590529e20470e53c1d4b6b970de5d4fd357d864320735a75c1df0e2fffde07为了加速部署,我们把刚才pull下来的镜像,push到集成镜像仓里
#添加用户 #htpasswd /etc/origin/master/htpasswd xxp docker tag openshift/jenkins-1-centos7 hub2.300.cn/openshift/jenkins docker login -u developer -p `oc whoami -t` hub2.300.cn docker push hub2.300.cn/openshift/jenkinspush完后再来看istag的变化,由以前的
openshift/jenkins-1-centos变为了170.16.131.234:5000/openshift/jenkins➜ ~ oc get istag -n openshift | grep jenkins:latest jenkins:latest 170.16.131.234:5000/openshift/jenkins@sha256:dc0f434a492d11d6ae13711e77f87303a06a8fc0fb3a97ae327a4b88c33435b6 21 hours ago sha256:dc0f434a492d11d6ae13711e77f87303a06a8fc0fb3a97ae327a4b88c33435b6这里是push到集成镜像仓后,系统会自动更新对应的is和istag, 为了加速部署,更改istag还可以通过import-image从私有镜像仓(harbor)里来完成
这样再来部署jenkins应用就快速多了
还有很多更细致的东西,比如如何周期同步第三方镜像仓等等,有需要的查看官文
安装独立镜像仓
可以通过openshift-ansible一次性安装OK,这里使用CLI安装,正好可以串一下openshift里的各种概念的使用场景。
部署
oc project default
oc adm policy add-scc-to-user privileged system:serviceaccount:default:registry
oc label node 192.168.56.102 registry=true
#使用hostPath存储,要在node上放行权限,默认registry用的1001 userID, 不然后续挂载进去的volume,没有写权限
sudo chown 1001:root /home/registry
#注意要指定使用的镜像版本,默认是拉取最新的, 一定要指明``--volume``参数,不然deploy,不会挂载主机目录,官文这里遗漏了。
oc adm registry --images="openshift/origin-docker-registry:v1.4.1" --selector="registry=true" --mount-host="/home/registry" --service-account=registry --volume='/registry'```
中间莫名出现部署``error``的状态,重新部署了下``oc deploy docker-registry --retry``
### 加密镜像仓
- 先拿到serviceIP
```bash
[root@node0 master]# oc get svc docker-registry
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
docker-registry 170.16.132.252 <none> 5000/TCP 1h
- 创建自签名证书,如果已经有了,跳过此步
oc adm ca create-server-cert \
--signer-cert=/etc/origin/master/ca.crt \
--signer-key=/etc/origin/master/ca.key \
--signer-serial=/etc/origin/master/ca.serial.txt \
--hostnames='hub.example.com,docker-registry.default.svc.cluster.local,170.16.132.252:5000' \
--cert=/etc/secrets/registry.crt \
--key=/etc/secrets/registry.key
-
创建secret, secret是专门来保存敏感信息的,比如密码,sshkey,token信息等等
更详细的介绍可以查看这里
oc secrets new registry-secret \ /etc/secrets/registry.crt \ /etc/secrets/registry.key -
绑定secret到serviceaccount
oc secrets link registry registry-secret
oc secrets link default registry-secret
- 更新dc,添加volume,把新创建的secret挂进去
oc volume dc/docker-registry --add --type=secret \
--name=docker-registry --secret-name=registry-secret -m /etc/secrets
如果想移除的话,如下
oc volume dc/docker-registry --remove --name=docker-registry
- 更新环境变量
oc set env dc/docker-registry \
REGISTRY_HTTP_TLS_CERTIFICATE=/etc/secrets/registry.crt \
REGISTRY_HTTP_TLS_KEY=/etc/secrets/registry.key
- 更新健康监测 HTTP->HTTPS
oc patch dc/docker-registry -p '{"spec": {"template": {"spec": {"containers":[{
"name":"registry",
"livenessProbe": {"httpGet": {"scheme":"HTTPS"}}
}]}}}}'
oc patch dc/docker-registry -p '{"spec": {"template": {"spec": {"containers":[{
"name":"registry",
"readinessProbe": {"httpGet": {"scheme":"HTTPS"}}
}]}}}}'
- 验证是否OK
[root@node0 master]# oc logs dc/docker-registry | grep tls
time="2017-03-02T16:01:41.113619323Z" level=info msg="listening on :5000, tls" go.version=go1.7.4 instance.id=594aa09b-4540-4e38-a85a-851261cd1254
添加路由
oc create route passthrough registry --service=docker-registry --hostname=hub2.300.cn
登录镜像仓
oc policy add-role-to-user admin developer -n default
oc login -u developer
docker login -u developer -p `oc whoami -t` hub2.300.cn
- push镜像
docker push hub2.300.cn/default/busybox
安装镜像仓console
- oc利用官方模板安装
oc create -n default -f https://raw.githubusercontent.com/openshift/openshift-ansible/master/roles/openshift_hosted_templates/files/v1.4/origin/registry-console.yaml
oc create route passthrough --service registry-console \
--hostname hub3.300.cn \
-n default
oc new-app -n default --template=registry-console \
-p OPENSHIFT_OAUTH_PROVIDER_URL="https://192.168.31.100:8443" \
-p REGISTRY_HOST=$(oc get route docker-registry -n default --template='{{ .spec.host }}') \
-p COCKPIT_KUBE_URL=$(oc get route registry-console -n default --template='https://{{ .spec.host }}')
- 登录浏览器打开
https://hub3.300.cn/registry,使用已有的账户登录,比如这里是默认的developer和developer。
9 - 性能优化指南
介绍openshift的性能优化方案。
主要参考的官方链接, 本文是基于openshift 3.5说的。
概览
本指南提供了如何提高OpenShift容器平台的集群性能和生产环境下的最佳实践。 主要包括建立,扩展和调优OpenShift集群的推荐做法。
个人看法,其实性能这个东西是个权衡的过程,根据自身硬件条件和实际需求,选择适合自己的调优手段。
安装实践
网络依赖
首先安装自然要选择官方的openshift-ansible项目, 默认是rpm安装方式,需要依赖网络,比如要去联网下载atomic-openshift-*, iptables, 和 docker包依赖,
如果有不能联网的节点,可以参考我之前写的离线安装openshift。
ansible优化
官方推荐使用ansible安装,这里说下针对ansible的优化,以提高安装效率,主要参考ansible官方blog,
如果参考上文离线安装的话,不建议跨外网连接rpm仓或者镜像仓,下面是推荐的ansible配置
# cat /etc/ansible/ansible.cfg
# config file for ansible -- http://ansible.com/
# ==============================================
[defaults]
forks = 20 # 20个并发是理想值,太高的话中间会有概率出错
host_key_checking = False
remote_user = root
roles_path = roles/
gathering = smart
fact_caching = jsonfile
fact_caching_connection = $HOME/ansible/facts
fact_caching_timeout = 600
log_path = $HOME/ansible.log
nocows = 1
callback_whitelist = profile_tasks
[privilege_escalation]
become = False
[ssh_connection]
ssh_args = -o ControlMaster=auto -o ControlPersist=600s
control_path = %(directory)s/%%h-%%r
pipelining = True # 多路复用,减少了控制机和目标间的连接次数,加速了性能。
timeout = 10
网络配置
这里必须要提下,一定要安装前做好网络规划,不然后面改起来很麻烦,
默认是每个node上最多可跑110个pods,这个要看自身硬件条件,比如说我的环境全是高配物理机,我就改成了,每个节点可以跑1024个pods,这个主要改下面的地方。
openshift_node_kubelet_args={'pods-per-core': ['0'], 'max-pods': ['1024'], 'image-gc-high-threshold': ['90'], 'image-gc-low-threshold': ['80']}
osm_host_subnet_length=10
osm_cluster_network_cidr=12.1.0.0/12
关于网络的更多优化项,后面有单独介绍。
主机节点优化
openhshift集群里,除了pod间的网络通信外,最大的开销就是master和etcd间的通信了,openshift的master集成了k8s里的api-server, master主要通过etcd来交互node状态,网络配置,secrets和卷挂载等等信息
master侧
主要优化点包括:
- master和etcd尽量部署在一起.
- 高可用集群里,master尽量部署在低延迟的网络里.
- 确保**/etc/origin/master/master-config.yaml**里的etcds,第一个是本地的etcd实例.
node侧
node节点的配置主要在**/etc/origin/node/node-config.yaml**里, 优化点视具体情况定,主要可以优化的点有:
- iptables synchronization period,
- MTU值
- 代理模式
配合自文件里还可以配置kubelet的启动参数,主要关注两点pods-per-core 和 max-pods,这两个决定了node节点的pod数,两者不一致时,取值小的。如果数值过大(严重超卖)会导致:
- 增加cpu消耗,主要是docker和openshift自身管理消耗的
- 降低pod调度效率
- 加大了OOM的风险
- 分配pod ip出异常(可能地址池不够了,默认254个ip)
- 影响应用的性能
有一点要注意,k8s体系的平台,跑一个pod,实际会启动两个容器,一个pause先于业务容器启动,主要负责网络事项,所以跑10个pods,实际上会运行20个容器
etcd节点
etcd是一个分布式的key-value存储,所以有条件的话,存储读写性能的提升,上ssd最好了。
其次是网络的优化,比如和masters部署在一起,或者提供专网连接。
etcd实际使用中,最好的提升手段,是关注内存,这个官网有个换算公式的,多少pods推荐多大内存的使用
内核优化
上面的所有节点,内核层面都需要做些优化,这里推荐使用tuned工具来做,这点属于常规运维优化了,具体可以参考这里来做, 不想明白原理的,可以如下 快速操作,redhat的人已经自动化了。
yum install tuned
systemctl start tune
systemctl enable tuned
tuned-adm profile throughput-performance)来做
资源优化
超卖现象
主要是资源管理这块儿的注意点, 我以前有blog专门介绍过,主要值得一提的是,这里有个隐形的QoS级别
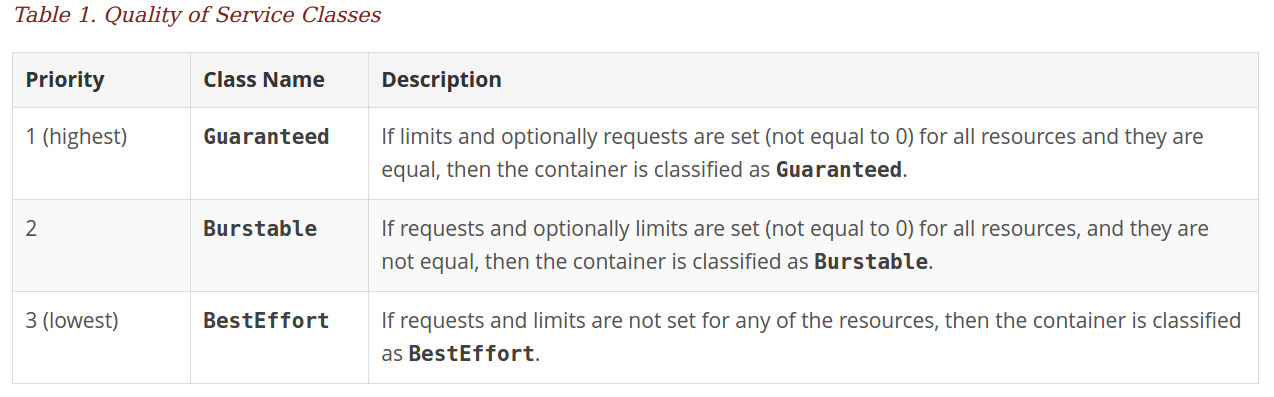
Guaranteed类型的pod是优先级最高的,是有保证的,只会在程序本身“异常”超出limits(一般的应用在pod层设置了limits,就不会超过该限制的,除非是java系的,其需要用环境变量来控制),才会被杀掉,其他类型的配额在集群资源紧张时会被kill掉的。
这块儿更多的细节也可以参考官文
镜像
这里需要注意的是,可以提前把需要的基础镜像先pull到node节点上,比如origin-pod镜像等,还有其他自定义的Gold 镜像,这样可以减少应用部署时间。
如果是采用镜像方式部署集群的话,也可以采取提前pull镜像的方式,当然有私有镜像仓的,可以忽略。
主要是现在默认的镜像拉取策略就是IfNotPresent,才能完成加速部署的效果
线上debug容器
线上容器环境可能很干净, 如何调试一个线上正在运行的容器,估计困扰过很多开发人员,这个其实利用docker原生特性,可以很easy的做到
比如你自己build一个工具包镜像tools,里面装有tcpdump,perf,strace等等debug工具,如下可以很方便的动态的嵌入到运行的线上容器中。
docker run -t --pid=container:production \
--net=container:production \
--cap-add sys_admin \
--cap-add sys_ptrace \
tools
当然万能的日志调式,也是OK的。
存储优化
这里的存储说的是docker的graph驱动( Device Mapper, Overlay, 和 Btrfs),首先overlay在启停容器速度方面要优于devicemapper,其还能带来更优良的页面缓存共享,但存在POSIX兼容性问题,比如不支持SELinux。
官方是推荐使用thin devicemapper的,但需要额外的独立块盘才能搞定。如果系统是7.2的话,使用overlay亦可,关闭selinux的代价就是牺牲部分容器安全。
路由和网络优化
openshift里的Router是基于haproxy做的,等价于k8s里的nginx ingress服务,提供集群内的service供外访问能力。
一般一个4 vCPU/16GB RAM的虚机,可以提供7000-32000 HTTP keep-alive连接请求,这取决于连接是否加密和页面大小,如果是物理机的话,性能会翻倍。
可通过Router sharding的技术来扩展性能。下图各种配置是统计性能(默认100个routes)
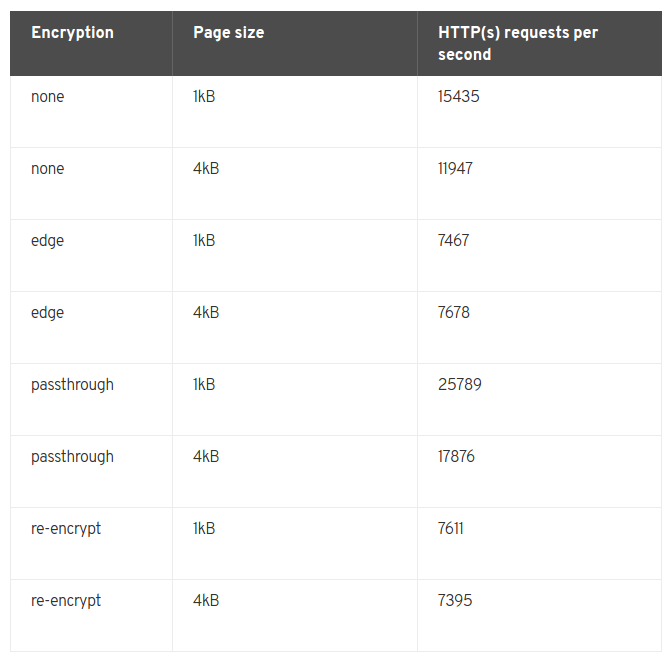
网络优化
默认openshift提供了一个基于ovs的sdn方案,其中涉及到了vxlan, OpenFlow和iptables,当然这些相关的优化项社区已经有很成熟的优化点和方法了,比如增大MTU,UDP-offload,多路复用等等,
这里重点说下vxlan, 基于二层网络,vxlan从4096提升到了16百万多个,vxlan就是把原报文封装进UDP报文,以提供所有pods间通信的能力,自然这样会增加cpu解封包的开销,具体网络吞吐取决于cpu的性能,另外还会额外增加延时响应。
直白的说,现在云主机或物理机的cpu都可以打满千兆网卡,如果是万兆网卡,那vxlan网络的吞吐带宽会卡在CPU上,这是所有overlay网络的现状。
如果你的主机用用万兆或者40Gbps, 那就要考虑网络的性能优化了:
- 通过直接路由,负责pod间通信,不过需要手动维护node节点添加删除时的路由变化。
- 条件允许的话,可以考虑BGP的calico网络方案
- 另外就是购置支持udp-offload的网卡
值得注意点是,及时使用了udp-offload的网卡,和非overlay网络比,延迟是不会减少的,只是减少了cpu开销,从而提高了带宽吞吐。
子网大小
现在openshift-ansible项目默认的安装出来的配置是:
- 集群里内最多1024个节点
- 每个节点最多可以跑510个pods
- 支持65,536个service
比如我要搞一个8192个节点的集群,每个节点允许510个pods运行:
[OSE3:vars]
osm_cluster_network_cidr=10.128.0.0/10
监控
都知道k8s里的弹性伸缩,依赖于Heapster, 而openshift内置的监控系统又是用的自家的Haw系列,导致监控镜像相当的大
在opneshift里有两点要提的是METRICS_RESOLUTION和METRICS_DURATION变量,前者是默认是30s,指的是监控时间间隔,后者默认是7天,指的是监控数据保留时长(过期就会删掉)。
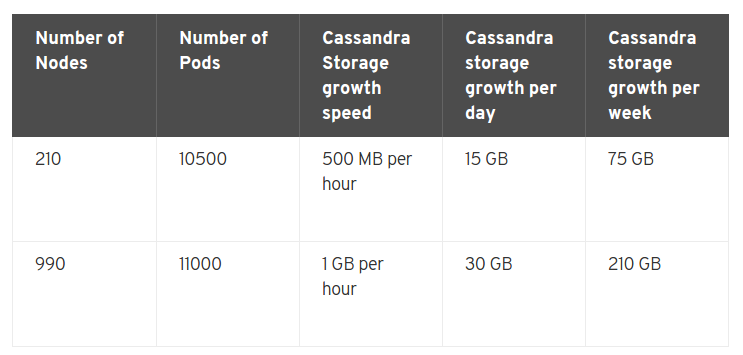
默认的监控体系(Cassandra/Hawkular/Heapster)可以监控25000个pods。
总结
其实openshift基于k8s提供了一站式解决方案, 如果公司不具备k8s二次开发能力,openshift足矣。
10 - 网络整理
介绍openshift的网络方案。
介绍利用openshift-ansible项目安装后的生产环境里的网络情况。
待整理。。。
11 - 监控梳理
介绍openshift的监控方案。
未完搞 ...
12 - 日志分析
介绍openshift的日志方案。
未完搞 ...