主要记录介绍对kubersphere的架构认知和储备二次开发所必备的知识。
本系列文章中会把kubesphere简说成KCP(Qingcloud kubernetes controller-manage platform)
主要记录介绍对kubersphere的架构认知和储备二次开发所必备的知识。
本系列文章中会把kubesphere简说成KCP(Qingcloud kubernetes controller-manage platform)
我本地4c/8G的小本儿,跑了两个集群,组建了多集群环境,还行,能玩动...
kind安装
镜像准备
视网络情况,可以把依赖镜像kindest/node提起pull到本地
docker的data-root目录
尽量不要放到/var目录下,kind起的集群容器会占用比较大的空间
执行完如下命令后,docker ps可以看到本地启动了两个容器,一个容器对应一个集群。
kind create cluster --image kindest/node:v1.19.16 --name host
kind create cluster --image kindest/node:v1.19.16 --name member
kubectl config use-context [kind-host | kind-member],可以切换kubecl执行的上下文
分别在两个集群各自安装ks组件
# 集群1安装
kubectl config use-context kind-host
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/cluster-configuration.yaml
# 集群2安装
kubectl config use-context kind-member
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/cluster-configuration.yaml
可以在上面的初始化阶段直接改好主和成员集群的关系,这里参考官文即可
host集群的UI地址,可以通过host容器IP:30880来访问,主集群的容器ip,可以如下获取:
docker inspect --format '{{ .NetworkSettings.Networks.kind.IPAddress }}' host-control-plane
实操添加集群时,需要member集群的kubeconfig,可以用如下命令获取到
kind get kubeconfig --name member
记得把kubeconfig中的server地址中改成member容器ip:6443,这样host集群才能访问到member集群
验证功能、测试开发,挺方便的,可以视本地资源紧张情况停掉监控的ns。
现在kind启动的集群默认使用了containerd的runtime,若想进一步调试查看集群内的情况,可以内部集成的crictl代替熟悉的docker工具。
遇到这样一个场景,在同一套环境中需要存在多个host控制面集群...bulabula... 因此想探索下kubesphere的异地多活混合容器云管理方案
一个兼容原生的k8s集群,可通过ks-installer来初始化完成安装,成为一个QKE集群。QKE集群分为多种角色,默认是none角色(standalone模式),开启多集群功能时,可以设置为host或者member角色。
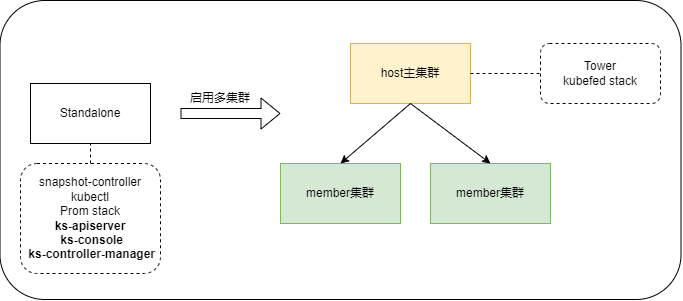
上段提到QKE有3种角色,可通过修改cc配置文件的clusterRole来使能, ks-installer监听到配置变化的事件,会初始化对应集群角色的功能。
kubectl edit cc ks-installer -n kubesphere-system
角色不要改来改去,会出现莫名问题,主要是背后ansible维护的逻辑有疏漏,没闭环
host角色的主集群会被创建25种联邦资源类型Kind,如下命令可查看,还会额外安装kubefed stack组件。
➜ kubectl get FederatedTypeConfig -A
此外api-server被重启后,会根据配置内容的变化,做两件事,注册多集群相关的路由和缓存同步部分联邦资源。
clusters/{cluster}路径的agent路由和转发的功能,要访问业务集群的信息,这样可以直接转发过去。当开启多集群后,如果某个member出现异常导致不可通信,那host的api-server此时遇到故障要重启,会卡在cacheSync这一步,导致无法启动,进而整个平台无法访问。
controller-manager被重启后,同样会根据配置的变化,把部分资源类型自动转化成联邦资源的逻辑,也就是说,在host集群创建的这部分资源会自动同步到所有成员集群,实际的多集群同步靠kubefed-controller-manager来执行。以下资源会被自动创建联邦资源下发:
此外还会启动cluster、group和一些globalRole*相关资源的控制器逻辑,同上也会通过kubefed自动下发到所有集群,clusters.cluster.kubesphere.io资源除外。
如果以上资源包含了
kubefed.io/managed: false标签,kubefed就不会再做下发同步,而host集群下发完以上资源后,都会自动加上该标签,防止进入死循环
修改为member集群时,需要cc中的jwtSecret与host集群的保持一致(若该值为空的话,ks-installer默认会随机生成),提取host集群的该值时,需要去cm里找,如下:
kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret
jwtSecret要保持一致,主要是为了在host集群签发的用户token,在用户访问业务集群时token校验能通过。
本文只关注直接连接这种情况,当填好成员集群的kubeconfig信息,点击添加集群后,会做如下校验:
jwtSecret是否和主集群的一致写稿时,此处有个问题,需要修复,如果kubeconfig使用了
insecure-skip-tls-verify: true会导致该集群添加失败,经定位主要是kubefed 空指针panic了,后续有时间我会去fix一下,已提issue。
校验完必要信息后,就执行实质动作joinFederation加入联邦,kubesphere多集群纳管,实质上是先组成联邦集群:
kubefedclusters.core.kubefed.io,由kubefed stack驱动联邦的建立上述一顿操作,等效于
kubefedctl join member-cluster --cluster-context member-cluster --host-cluster-context host-cluster
异地多活的方案主要是多个主集群能同时存在,且保证数据双向同步,经过上面的原理分析,可知多个主集群是可以同时存在的,也就是一个成员集群可以和多个主集群组成联邦。整体方案示意图设计如下:
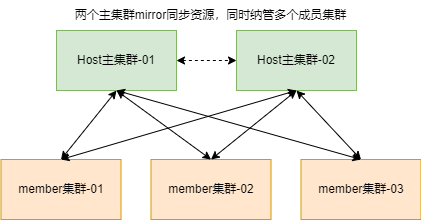
以下操作假设本地已具备三个QKE集群,如果不具备的可按照此处快速搭建
host、host2、member3个集群
大致实现逻辑的前提介绍:
jwtSecret得保持一致添加纳管同一个member集群etcdctl make-mirror实现双向同步实操双活前,先验证下可行性
实验1:
在两边创建一个同名用户,用户所有信息一致,可以添加成功,然后再修改一边的用户信息,使两边不一致
可以看到member集群的用户xxp,一直会被两边不断的更新...
root@member-control-plane:/# kubectl get user xxp -w
NAME EMAIL STATUS
xxp xxp@163.com Active
xxp xxp-2@163.com Active
xxp xxp@163.com Active
xxp xxp-2@163.com Active
... 周而复始 ...
这个实验,即使在创建用户时,页面表单上两边信息填的都一样,也会出现互相刷新覆盖的情况,因为yaml里的uid和time信息不一致
实验2:
在两边添加一个同名用户,但两边用户信息(用户角色)不一致,可以创建成功,但后创建者的kube-federa会同步失败, 到这里还能接受,毕竟有冲突直接就同步失败了
但member集群上该用户的关联角色会出现上文的情况,被两边的主集群持续反复地修改...
实验3:
在一侧的主集群上尝试修复冲突资源,即删除有冲突的用户资源,可以删除成功,但对应的联邦资源会出现删失败的情况
➜ ~ kubectl get users.iam.kubesphere.io
NAME EMAIL STATUS
admin admin@kubesphere.io Active
xxp3 xxp3@163.com Active
➜ ~
➜ ~ kubectl get federatedusers.types.kubefed.io
NAME AGE
admin 5h33m
xxp 65m #这里是个删不掉的资源,fed controller会重复做失败尝试
xxp3 61m
这样就会出现,两个主集群:一个要删,一个要同步,member集群上:持续上演“一会儿消失,一会儿又出现了”的奇观。
两个主集群可以同时工作,一旦出现同名冲突资源,处理起来会非常麻烦,尤其是背后的Dependent附属资源出现冲突时,往往问题点隐藏的更深,修复起来也棘手...
后来调研也发现:目前的社区方案make-mirror只支持单向同步,适合用来做灾备方案。
所以容器云平台的双活,除非具备跨AZ的etcd集群,否则需要二次开发改造类make-mirror方案来支持了。我最开始要考虑的问题答案也就显而易见了:如果要多个host集群共存,必须考虑通过行政管理手段,来尽量避免同名资源冲突。
Remote Development插件使用kt-connect,打通网络,本地可直接访问Kubernetes集群内网
sudo ktctl connect --context kind-host --portForwardTimeout 300
ktctl采用本地kubectl工具的集群配置,默认为~/.kube/config文件中配置的集群。--context指定要连接的具体集群kind集群,需要修改kubeconfig中server的127地址为容器IP:6443ERR Exit: pod kt-rectifier-tcxjk failed to start,可适当增加等待时间portForwardTimeout另外注意的是,kt-connect需要root权限,上条命令会默认读取
/root/.kube/config文件,自行copy或者另通过-c指定文件
不表.
首先编辑vscode的调试配置文件, 我是如下配置的:
➜ kubesphere git:(master) cat .vscode/launch.json
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "ks-apiserver",
"type": "go",
"request": "launch",
"mode": "auto",
"program": "${workspaceFolder}/cmd/ks-apiserver/apiserver.go"
},
{
"name": "controller-manager",
"type": "go",
"request": "launch",
"mode": "auto",
"program": "${workspaceFolder}/cmd/controller-manager/controller-manager.go"
}
]
}
按F5,启动调试,左上角选择要调试的组件,我这里以controller-manager举例(需要hack的注意点比较多)。
过会儿会发现出现错误,错误提示很明显,因缺少配置文件,导致无法启动,通过查看deployment yaml, 发现后面还会缺失Admission Webhooks的证书,可如下统一提取到本地:
# 提取启动的配置文件(调试apiserver的时候也需要这一步,但要把文件放到对应cmd/ks-apiserver目录下)
kubectl -n kubesphere-system get cm kubesphere-config -ojsonpath='{.data.kubesphere\.yaml}' > cmd/controller-manager/kubesphere.yaml
# 提取webhook用到的证书
mkdir -p /tmp/k8s-webhook-server/serving-certs/
export controller_pod=`kubectl -n kubesphere-system get pods -l app=ks-controller-manager -o jsonpath='{.items[0].metadata.name}'`
kubectl -n kubesphere-system exec -it ${controller_pod} -- cat /tmp/k8s-webhook-server/serving-certs/ca.crt > /tmp/k8s-webhook-server/serving-certs/ca.crt
kubectl -n kubesphere-system exec -it ${controller_pod} -- cat /tmp/k8s-webhook-server/serving-certs/tls.crt > /tmp/k8s-webhook-server/serving-certs/tls.crt
kubectl -n kubesphere-system exec -it ${controller_pod} -- cat /tmp/k8s-webhook-server/serving-certs/tls.key > /tmp/k8s-webhook-server/serving-certs/tls.key
继续启动,发现还会有缺文件的错误,应该是编译镜像时,内置了些文件,通过查看build/ks-controller-manager/Dockerfile,发现后面会缺的东西还是比较多的,推荐直接从运行中的pod直接copy到本地:
sudo mkdir /var/helm-charts/
sudo chmod -R a+rw /var/helm-charts
kubectl -n kubesphere-system cp ${controller_pod}:/var/helm-charts /var/helm-charts/
继续启动,成功 !
利用ktctl替换集群中的ks-controller-manager的服务为本地服务。
sudo ktctl exchange ks-controller-manager --namespace kubesphere-system --mode scale --recoverWaitTime 300 --expose 8443:8443
如果本地集群只有一个节点,上述命令会一直pending,可以通过如下命令替代
sudo ktctl exchange ks-controller-manager --namespace kubesphere-system --expose 8443:8443 kubectl -n kubesphere-system scale deployment ks-controller-manager --replicas=0结束调试,记得还原刚才缩容
replicas的设置。
后续就是vscode的正常断点调试或者本地开发验证了,有时间在整理贴图...