云原生领域,持续深耕中...
自15年开始接触容器,当时容器就是Docker,Docker就是容器,当然现在docker仍是主流的容器runtime方案,但随着k8s带起来的云原生生态规模落地和全球企业数字化转型的战略倡导,如今也发生了太多变化...此篇会把以前编写的一些文章挪移到此处,顺便开启新的认知。
云原生领域,持续深耕中...
自15年开始接触容器,当时容器就是Docker,Docker就是容器,当然现在docker仍是主流的容器runtime方案,但随着k8s带起来的云原生生态规模落地和全球企业数字化转型的战略倡导,如今也发生了太多变化...此篇会把以前编写的一些文章挪移到此处,顺便开启新的认知。
容器基础界还在不断向前发展,持续更新认知。
自15年开始接触容器,当时容器就是Docker,Docker就是容器,当然现在docker仍是主流的容器runtime方案,随着k8s的规模落地,生态也在潜移默化的变化着,此篇会把以前编写的一些文章挪移到此处,顺便开启新的认知。
mkdir -p images && cd images
for image in `docker images | grep -v REPOSITORY | awk '{print $1":"$2}'`; do
echo "saving the image of ${image}"
docker save ${image} > ${image////-}.tar
echo -e "finished saving the image of \033[32m ${image} \033[0m"
done
for image in `ls *.tar`; do
echo "loading the image of ${image}"
docker load < ${image}
echo -e "finished loading the image of \033[32m ${image} \033[0m"
done
ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]' | awk '{print $2}' | xargs kill -9
自去年就开始推动公司业务使用docker了, 至今也一年多了,但对docker网络的认知一直一知半解。。。
主要是太忙,加上线上业务也没出过关于网络吞吐性能方面的问题,就没太大动力去搞明白, 现在闲下来了,搞之!
docker更新迭代速度太快了,公司业务只用到基本功能,所以没动力跟进它的更新了 各种新时代下的产物频出啊, CoreOS为linux的发行版, 没需求,好遗憾.
一开始安装完docker, 它就会默认创建3个网络, 使用__docker network ls__查看
➜ blog git:(master) docker network ls
NETWORK ID NAME DRIVER
46416a43fbc6 bridge bridge
45398901e9f0 none null
9440a8140e68 host host
当启动一个容器时, 默认使用bridge模式, 可以通过 --net 指定其它模式。
下面先简要说明下各自的概念
容器间之所以能通信,就靠宿主机上的docker0了, docker0就是bridge模式下默认创建的虚拟设备名称
➜ blog git:(master) ✗ ifconfig docker0
docker0 Link encap:Ethernet HWaddr 02:42:49:56:7c:3b
inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:49ff:fe56:7c3b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:78103 errors:0 dropped:0 overruns:0 frame:0
TX packets:47578 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:17485434 (17.4 MB) TX bytes:82163889 (82.1 MB)
ifocnfig可以看到很多信息, mac地址,IP等这些也可以通过参数指定成别的。
none网络模式下的容器里是缺少网络接口的,例如eth0等,但会有一个lo设备。
没用过也没见过这样的业务场景, 不做过多说明
容器直接操作宿主机的网络栈, 无疑是性能最好的网络模式, 可以认为是无带宽损耗的。
这也是我们线上正在在用的网络模式。
bridge模式主要利用了iptables的Masquerading和DNAT功能。
未完。。。
Docker内置容器编排方案
当年的swarm、k8s、mesos三大系统竞争之激烈,现在都归于k8s了。
此文档适用于低于1.12版本的docker,之后swarm已内置于docker-engine里。
至少5台PC服务器, 分别如下作用
一台一台的ssh上去执行,或者使用ansible批量部署工具。
安装docker-engine
curl -sSL https://get.docker.com/ | sh
启动之,并使之监听2375端口
sudo docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
亦可修改配置,使之永久生效
mkdir /etc/systemd/system/docker.service.d
cat <<EOF >>/etc/systemd/system/docker.service.d/docker.conf
[Service]
ExecStart=
ExecStart=/usr/bin/docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --dns 180.76.76.76 --insecure-registry registry.cecf.com -g /home/Docker/docker
EOF
在consul0上启动consul服务,manager用其来认证node连接并存储node状态, 理应建立discovery的高可用,这里简化之
docker run -d -p 8500:8500 --name=consul progrium/consul -server -bootstrap
在manager0上创建the primary manager, 自行替换manager0_ip和consul0_ip的真实IP地址。
docker run -d -p 4000:4000 swarm manage -H :4000 --replication --advertise <manager0_ip>:4000 consul://<consul0_ip>:8500
在manager1上启动replica manger
docker run -d -p 4000:4000 swarm manage -H :4000 --replication --advertise <manager1_ip>:4000 consul://<consul0_ip>:8500
--replication
分别在node0和node1上执行加入集群操作
docker run -d swarm join --advertise=<node_ip>:2375 consul://<consul0_ip>:8500
docker -H :4000 info
此文档适用于不低于1.12版本的docker,因为swarm已内置于docker-engine里。
这里以5台PC服务器为例, 分别如下作用
一台一台的ssh上去执行,或者使用ansible批量部署工具。
安装docker-engine
curl -sSL https://get.docker.com/ | sh
启动之,并使之监听2375端口
sudo docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
亦可修改配置,使之永久生效
mkdir /etc/systemd/system/docker.service.d
cat <<EOF >>/etc/systemd/system/docker.service.d/docker.conf
[Service]
ExecStart=
ExecStart=/usr/bin/docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --dns 180.76.76.76 --insecure-registry registry.cecf.com -g /home/Docker/docker
EOF
如果开启了防火墙,需要开启如下端口
docker swarm init --advertise-addr <MANAGER-IP>
我的实例里如下:
[root@manager0 ~]# docker swarm init --advertise-addr 10.42.0.243
Swarm initialized: current node (e5eqi0lue90uidzsfddeqwfl8) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-3iskhw3lsc9pkdtijj1d23lg9tp7duj18f477i5ywgezry7zlt-dfwjbsjleoajcdj13psu702s6 \
10.42.0.243:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
使用 --advertise-addr 来声明manager0的IP,其他的nodes必须可以和此IP互通,
一旦完整初始化,此node即是manger又是worker node.
通过docker info来查看
$ docker info
Containers: 2
Running: 0
Paused: 0
Stopped: 2
...snip...
Swarm: active
NodeID: e5eqi0lue90uidzsfddeqwfl8
Is Manager: true
Managers: 1
Nodes: 1
...snip...
通过docker node ls来查看集群的node信息
[root@manager0 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
e5eqi0lue90uidzsfddeqwfl8 * manager0 Ready Active Leader
这里的*来指明docker client正在链接在这个node上。
执行在manager0上产生docker swarm init产生的结果即可
如果当时没记录下来,还可以在manager上补看 想把node以worker身份加入,在manager0上执行下面的命令来补看。
docker swarm join-token worker
想把node以manager身份加入,在manager0上执行下面的命令来来补看。
docker swarm join-token manager
为了manager的高可用,我这里需要在manager1上执行
docker swarm join \
--token SWMTKN-1-3iskhw3lsc9pkdtijj1d23lg9tp7duj18f477i5ywgezry7zlt-86dk7l9usp1yh4uc3rjchf2hu \
10.42.0.243:2377
我这里就是依次在node0-2上执行
docker swarm join \
--token SWMTKN-1-3iskhw3lsc9pkdtijj1d23lg9tp7duj18f477i5ywgezry7zlt-dfwjbsjleoajcdj13psu702s6 \
10.42.0.243:2377
这样node就会加入之前我们创建的swarm集群里。
再通过docker node ls来查看现在的集群情况, swarm的集群里是以node为实例的
[root@manager0 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
0tr5fu8ebi27cp2ot210t67fx manager1 Ready Active Reachable
46irkik4idjk8rjy7pqjb84x0 node1 Ready Active
79hlu1m7x9p4cc4npa4xjuax3 node0 Ready Active
9535h8ow82s8mzuw5kud2mwl3 consul0 Ready Active
e5eqi0lue90uidzsfddeqwfl8 * manager0 Ready Active Leader
这里MANAFER标明各node的身份,空即为worker身份。
Usage: docker service COMMAND
Manage Docker services
Options:
--help Print usage
Commands:
create Create a new service
inspect Display detailed information on one or more services
ps List the tasks of a service
ls List services
rm Remove one or more services
scale Scale one or multiple services
update Update a service
部署示例如下:
docker service create --replicas 2 --name helloworld alpine ping 300.cn
docker service ls罗列swarm集群的所有services
docker service ps helloworld查看service部署到了哪个node上
docker service inspect helloworld 查看service 资源、状态等具体信息
docker servcie scale helloworld=5来扩容service的个数
docker service rm helloworld 来删除service
docker service update 来实现更新service的各项属性,包括滚动升级等。
可更新的属性包含如下:
Usage: docker service update [OPTIONS] SERVICE
Update a service
Options:
--args string Service command args
--constraint-add value Add or update placement constraints (default [])
--constraint-rm value Remove a constraint (default [])
--container-label-add value Add or update container labels (default [])
--container-label-rm value Remove a container label by its key (default [])
--endpoint-mode string Endpoint mode (vip or dnsrr)
--env-add value Add or update environment variables (default [])
--env-rm value Remove an environment variable (default [])
--help Print usage
--image string Service image tag
--label-add value Add or update service labels (default [])
--label-rm value Remove a label by its key (default [])
--limit-cpu value Limit CPUs (default 0.000)
--limit-memory value Limit Memory (default 0 B)
--log-driver string Logging driver for service
--log-opt value Logging driver options (default [])
--mount-add value Add or update a mount on a service
--mount-rm value Remove a mount by its target path (default [])
--name string Service name
--publish-add value Add or update a published port (default [])
--publish-rm value Remove a published port by its target port (default [])
--replicas value Number of tasks (default none)
--reserve-cpu value Reserve CPUs (default 0.000)
--reserve-memory value Reserve Memory (default 0 B)
--restart-condition string Restart when condition is met (none, on-failure, or any)
--restart-delay value Delay between restart attempts (default none)
--restart-max-attempts value Maximum number of restarts before giving up (default none)
--restart-window value Window used to evaluate the restart policy (default none)
--stop-grace-period value Time to wait before force killing a container (default none)
--update-delay duration Delay between updates
--update-failure-action string Action on update failure (pause|continue) (default "pause")
--update-parallelism uint Maximum number of tasks updated simultaneously (0 to update all at once) (default 1)
-u, --user string Username or UID
--with-registry-auth Send registry authentication details to swarm agents
-w, --workdir string Working directory inside the container
如前文所述,默认已经搭建好环境,基于docker1.12版本。
[root@manager0 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
0bbmd3r7aphs374qaea4zcieo node2 Ready Active
3qmxzyauc0bz4kjqvld9uogz5 manager1 Ready Active Reachable
5ewbdtvaopj4ltwqx0a4i65nt * manager0 Ready Drain Leader
5oxxpgk69fnwe5w210kovrqi9 node1 Ready Active
7s1ilay2wkjgt09bp2z0743m7 node0 Ready Active
docker network create -d overlay --subnet 10.254.0.0/16 --gateway 10.254.0.1 mynet1
docker service create --name redis --network mynet1 redis
[root@manager0 ~]# docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
9avksjfqr2gxm413dfrezrmgr redis.1 redis node1 Running Running 17 seconds ago
实例里,同样可以去node1上用docker ps查看
以上只是最基本的集群创建服务的用法,从中可见,swarm的的调度基本单元是task, 没有pod的概念,一个task可以简单理解成一个docker run的结果。目前swarm里也不支持compose。
docker官方称,以后会支持vm、pod的调度单元,具体日期未知。
使用docker service create创建服务, 这其中选择再哪个节点部署,docker 提供了三种调度策略;
通过--replicas参数可以设置服务容器的数量,已达到高可用状态;
#创建多副本
docker service update --replicas 4 redis
#查看副本部署情况
[root@manager0 ~]# docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
9avksjfqr2gxm413dfrezrmgr redis.1 redis node1 Running Running 13 minutes ago
0olv1sfz6d79wdnorw7jgoyri redis.2 redis manager1 Running Running about a minute ago
f3n6deesjlkxu4k48lzabieus redis.3 redis node2 Running Preparing 3 minutes ago
80bzarvkiytpv1690sla6unt2 redis.4 redis node0 Running Running about a minute ago
#验证多可用, 总共4个副本,docker内置的DNS服务会默认使用round-robin调度策略来解析主机。
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> set user 1
OK
redis:6379> exit
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> get user
(nil)
redis:6379> set user 2
OK
redis:6379> exit
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> get user
(nil)
redis:6379> set user 3
OK
redis:6379> exit
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> get user
(nil)
redis:6379> set user 4
OK
redis:6379> exit
root@9ed77b4b4432:/data# redis-cli -h redis
redis:6379> get user
"1"
redis:6379>
记录个人从docker迁移到containerd的事项
https://github.com/containerd/containerd
TODO.
下载必要组件:https://github.com/containerd/nerdctl/releases,
主要介绍k8s的核心功能和周边生态
此文应该不能运行成功了,,,陈年老文,有待验证。
git clone 代码步骤省略 ...
通过修改配置文件 cluster/centos/config-build.sh, 可自定义(k8s, docker, flannel, etcd)各自的下载地址和版本, 不同的版本的依赖可能会需要小改下脚本(版本变更有些打包路径发生了变化,兼容性问题)
cd cluster/centos && ./build.sh all
通过修改配置文件 cluster/centos/config-default.sh,定义你环境里的设备的IP和其他参数,推荐运行脚本前先通过ssh-copy-id做好免密钥认证;
export KUBERNETES_PROVIDER=centos && cluster/kube-up.sh
本步骤基于上一大步来说, 先来看下载各依赖的release后,cluster/centos下目录发生了什么变化
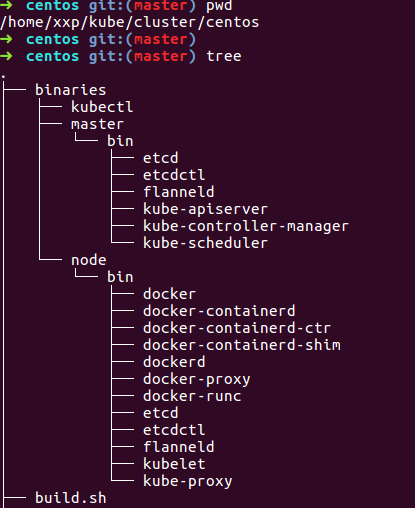
多了一个binaries的目录,里面是各master和minion上各依赖的二进制文件, 所以我们只要源码编译的结果,替换到这里来, 然后继续上一大步的第2小步即可。
这里说下,本地编译k8s的话,需要设置安装godep,然后命令本地化。
export PATH=$PATH:$GOPATH/bin
最后只需要去源码根目录下执行, 编译结果在_output目录下
make
替换到相应的binaries目录下,重新运行kube-up.sh即可。
虽然距离当前主流版本已经差之千里,但其中的思想仍记得借鉴。
经常遇到全新初始安装k8s集群的问题,所以想着搞成离线模式,本着最小依赖原则,提高安装速度
基于Centos7-1511-minimal, 非此版本脚本应该会运行出错,自行修改吧
本离线安装所有的依赖都打包放到了百度网盘
为了便于维护,已建立独立项目k8s-deploy
基本思路是,在k8s-deploy目录下,临时启个http server, node节点上会从此拉取所依赖镜像和rpms
# python -m SimpleHTTPServer
Serving HTTP on 0.0.0.0 port 8000 ...
windows上可以用hfs临时启个http server, 自行百度如何使用
运行以下命令,初始化master
192.168.56.1:8000 是我的http-server, 注意要将k8s-deploy.sh 里的HTTP-SERVER变量也改下
curl -L http://192.168.56.1:8000/k8s-deploy.sh | bash -s master
视自己的情况而定
curl -L http://192.168.56.1:8000/k8s-deploy.sh | bash -s join --token=6669b1.81f129bc847154f9 192.168.56.100
整个脚本实现比较简单, 坑都在脚本里解决了。脚本文件在这里
就一个master-up和node-up, 基本一个函数只做一件事,很清晰,可以自己查看具体过程。
1.5 与 1.3给我感觉最大的变化是网络部分, 1.5启用了cni网络插件 不需要像以前一样非要把flannel和docker绑在一起了(先启flannel才能启docker)。
具体可以看这里 https://github.com/containernetworking/cni/blob/master/Documentation/flannel.md
master侧如果是单核的话,会因资源不足, dns安装失败。
了解一个工具的特性可以从它的参数入手
在k8s内发挥的网关和api
CSR特性
flannel的设计就是为集群中所有节点能重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址, 并让属于不同节点上的容器能够直接通过内网IP通信。
实际上就是给每个节点的docker重新设置容器上可分配的IP段, --bip的妙用。
这恰好迎合了k8s的设计,即一个pod(container)在集群中拥有唯一、可路由到的IP,带来的好处就是减少跨主机容器间通信要port mapping的复杂性。
原理
[root@master1 ~]# etcdctl ls /coreos.com/network
/coreos.com/network/config
/coreos.com/network/subnets
[root@master1 ~]#
[root@master1 ~]# etcdctl get /coreos.com/network/config
{"Network":"172.16.0.0/16"}
[root@master1 ~]#
[root@master1 ~]# etcdctl ls /coreos.com/network/subnets
/coreos.com/network/subnets/172.16.29.0-24
/coreos.com/network/subnets/172.16.40.0-24
/coreos.com/network/subnets/172.16.60.0-24
[root@master1 ~]#
[root@master1 ~]# etcdctl get /coreos.com/network/subnets/172.16.29.0-24
{"PublicIP":"192.168.1.129"}
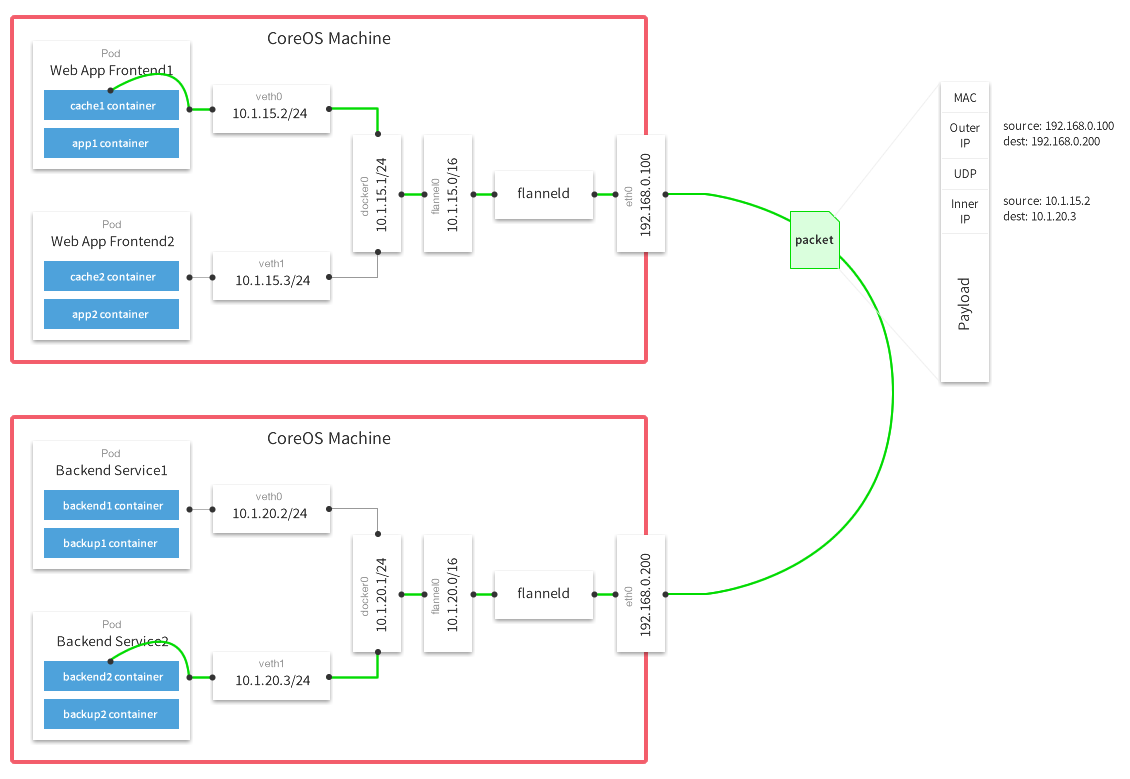
flannel0 还负责解封装报文,或者创建路由。 flannel有多种方式可以完成报文的转发。
下图是经典的UDP封装方式数据流图
Helm是一个管理kubernetes集群内应用的工具,提供了一系列管理应用的快捷方式,例如 inspect, install, upgrade, delete等,经验可以沿用以前apt,yum,homebrew的,区别就是helm管理的是kubernetes集群内的应用。
还有一个概念必须得提,就是chart, 它代表的就是被helm管理的应用包,里面具体就是放一些预先配置的Kubernetes资源(pod, rc, deployment, service, ingress),一个包描述文件(Chart.yaml), 还可以通过指定依赖来组织成更复杂的应用,支持go template语法,可参数化模板,让使用者定制化安装
charts可以存放在本地,也可以放在远端,这点理解成yum仓很合适。。。
这里有个应用市场 ,里面罗列了各种应用charts。由开源项目monocular支撑
下面主要介绍helm的基本使用流程和具体场景的实践。
先来准备k8s环境,可以通过k8s-deploy项目来离线安装高可用kubernetes集群,我这里是单机演示环境。
kubeadm init --kubernetes-version v1.6.2 --pod-network-cidr 12.240.0.0/12
#方便命令自动补全
source <(kubectl completion zsh)
#安装cni网络
cp /etc/kubernetes/admin.conf $HOME/.kube/config
kubectl apply -f kube-flannel-rbac.yml
kubectl apply -f kube-flannel.yml
#使能master可以被调度
kubectl taint node --all node-role.kubernetes.io/master-
#安装ingress-controller, 边界路由作用
kubectl create -f ingress-traefik-rbac.yml
kubectl create -f ingress-traefik-deploy.yml
这样一个比较完整的k8s环境就具备了,另外监控和日志不在此文的讨论范围内。
由于刚才创建的k8s集群默认启用RBAC机制,个人认为这个特性是k8s真正走向成熟的一大标志,废话不表,为了helm可以安装任何应用,我们先给他最高权限。
kubectl create serviceaccount helm --namespace kube-system
kubectl create clusterrolebinding cluster-admin-helm --clusterrole=cluster-admin --serviceaccount=kube-system:helm
初始化helm,如下执行,会在kube-system namepsace里安装一个tiller服务端,这个服务端就是用来解析helm语义的,后台再转成api-server的API执行:
➜ helm init --service-account helm
$HELM_HOME has been configured at /home/xxp/.helm.
Tiller (the helm server side component) has been installed into your Kubernetes Cluster.
Happy Helming!
➜ helm version
Client: &version.Version{SemVer:"v2.4.1", GitCommit:"46d9ea82e2c925186e1fc620a8320ce1314cbb02", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.4.1", GitCommit:"46d9ea82e2c925186e1fc620a8320ce1314cbb02", GitTreeState:"clean"}
#命令行补全
➜ source <(helm completion zsh)
初始化Helm后,默认就导入了2个repos,后面安装和搜索应用时,都是从这2个仓里出的,当然也可以自己通过helm repo add添加本地私有仓
➜ helm repo list
NAME URL
stable https://kubernetes-charts.storage.googleapis.com
local http://127.0.0.1:8879/charts
其实上面的repo仓的索引信息是存放在~/.helm/repository的, 类似/etc/yum.repos.d/的作用
helm的使用基本流程如下:
这里举例安装redis
➜ helm install stable/redis --set persistence.enabled=false
如上,如果网络给力的话,很快就会装上最新的redis版本,Helm安装应用,目前有四种方式:
helm install stable/mariadb 通过chart仓来安装helm install ./nginx-1.2.3.tgz 通过本地打包后的压缩chart包来安装helm install ./nginx 通过本地的chart目录来安装helm install https://example.com/charts/nginx-1.2.3.tgz 通过绝对网络地址来安装chart压缩包主要从制作自己的chart, 构建自己的repo, 组装复杂应用的实战三方面来演示
helm有一个很好的引导教程模板, 如下会自动创建一个通用的应用模板
➜ helm create myapp
Creating myapp
➜ tree myapp
myapp
├── charts //此应用包的依赖包定义(如果有的话,也会是类似此包的目录结构)
├── Chart.yaml // 包的描述文件
├── templates // 包的主体目录
│ ├── deployment.yaml // kubernetes里的deployment yaml文件
│ ├── _helpers.tpl // 模板里如果复杂的话,可能需要函数或者其他数据结构,这里就是定义的地方
│ ├── ingress.yaml // kubernetes里的ingress yaml文件
│ ├── NOTES.txt // 想提供给使用者的一些注意事项,一般提供install后,如何访问之类的信息
│ └── service.yaml // kubernetes里的service yaml文件
└── values.yaml // 参数的默认值
2 directories, 7 files
如上操作,我们就有了一个myapp的应用,目录结构如上,来看看看values.yaml的内容, 这个里面就是模板里可定制参数的默认值
很容易看到,kubernetes里的rc实例数,镜像名,servie配置,路由ingress配置都可以轻松定制。
# Default values for myapp.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
replicaCount: 1
image:
repository: nginx
tag: stable
pullPolicy: IfNotPresent
service:
name: nginx
type: ClusterIP
externalPort: 80
internalPort: 80
ingress:
enabled: false
# Used to create Ingress record (should used with service.type: ClusterIP).
hosts:
- chart-example.local
annotations:
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
tls:
# Secrets must be manually created in the namespace.
# - secretName: chart-example-tls
# hosts:
# - chart-example.local
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 100m
memory: 128Mi
note.
一般拿到一个现有的app chart后,这个文件是必看的,通过
helm fetch myapp会得到一个类似上面目录的压缩包
我们可以通过 --set或传入values.yaml文件来定制化安装,
# 安装myapp模板: 启动2个实例,并可通过ingress对外提供myapp.192.168.31.49.xip.io的域名访问
➜ helm install --name myapp --set replicaCount=2,ingress.enabled=true,ingress.hosts={myapp.192.168.31.49.xip.io} ./myapp
➜ helm ls
NAME REVISION UPDATED STATUS CHART NAMESPACE
exasperated-rottweiler 1 Wed May 10 13:58:56 2017 DEPLOYED redis-0.5.2 default
myapp 1 Wed May 10 21:46:51 2017 DEPLOYED myapp-0.1.0 default
#通过传入yml文件来安装
#helm install --name myapp -f myvalues.yaml ./myapp
通过 helm repo list, 得知默认的local repo地址是http://127.0.0.1:8879/charts, 可以简单的通过helm serve来操作,再或者自己起个web server也是一样的。
这里举例,把刚才创建的myapp放到本地仓里
➜ helm search myapp
No results found
➜
➜ source <(helm completion zsh)
➜
➜ helm package myapp
➜
➜ helm serve &
[1] 10619
➜ Regenerating index. This may take a moment.
Now serving you on 127.0.0.1:8879
➜ deis helm search myapp
NAME VERSION DESCRIPTION
local/myapp 0.1.0 A Helm chart for Kubernetes
目前个人感觉体验不太好的是,私有仓里的app必须以tar包的形式存在。
透过例子学习,会加速理解,我们从deis里的workflow应用来介绍
➜ ~ helm repo add deis https://charts.deis.com/workflow
"deis" has been added to your repositories
➜ ~
➜ ~ helm search workflow
NAME VERSION DESCRIPTION
deis/workflow v2.14.0 Deis Workflow
➜ ~
➜ ~ helm fetch deis/workflow --untar
➜ ~ helm dep list workflow
NAME VERSION REPOSITORY STATUS
builder v2.10.1 https://charts.deis.com/builder unpacked
slugbuilder v2.4.12 https://charts.deis.com/slugbuilder unpacked
dockerbuilder v2.7.2 https://charts.deis.com/dockerbuilder unpacked
controller v2.14.0 https://charts.deis.com/controller unpacked
slugrunner v2.3.0 https://charts.deis.com/slugrunner unpacked
database v2.5.3 https://charts.deis.com/database unpacked
fluentd v2.9.0 https://charts.deis.com/fluentd unpacked
redis v2.2.6 https://charts.deis.com/redis unpacked
logger v2.4.3 https://charts.deis.com/logger unpacked
minio v2.3.5 https://charts.deis.com/minio unpacked
monitor v2.9.0 https://charts.deis.com/monitor unpacked
nsqd v2.2.7 https://charts.deis.com/nsqd unpacked
registry v2.4.0 https://charts.deis.com/registry unpacked
registry-proxy v1.3.0 https://charts.deis.com/registry-proxy unpacked
registry-token-refresher v1.1.2 https://charts.deis.com/registry-token-refresher unpacked
router v2.12.1 https://charts.deis.com/router unpacked
workflow-manager v2.5.0 https://charts.deis.com/workflow-manager unpacked
➜ ~ ls workflow
charts Chart.yaml requirements.lock requirements.yaml templates values.yaml
如上操作,我们会得到一个巨型应用,实际上便是deis出品的workflow开源paas平台,具体这个平台的介绍下次有机会再分享
整个大型应用是通过 wofkflow/requirements.yaml组织起来的,所有依赖的chart放到charts目录,然后charts目录里就是些类似myapp的小应用
更复杂的应用,甚至有人把openstack用helm安装到Kubernetes上,感兴趣的可以参考这里
如果已存在完善的监控系统的话,推荐使用k8s原生的heapster,比较轻量,容易集成。
我选择的是prometheus, 它是比较完善的云平台级监控方案,继k8s之后同样已被列入云计算基金会项目, 除了具备heapster的能力之外,还支持监控广泛的应用(mysql, JMX, HAProxy等)和灵活的告警的能力,并具备多IDC federation的能力,兼容多种开源监控系统(StatsD, Ganglia, collectd, nagios等)。
本文主要参考
下面分别介绍下两种方案
heapster的介绍:
通过向kubelet拉取stats的方式, 可提供15分钟内的缓存供k8s的dashboard用,也支持第三方存储,如influxdb等,还具备REST API(经我实验,这个API还不完善 缺少diskIO API).
heapster的监控范围
可监控的内容包括集群内的Container, Pod, Node 和 Namespace的性能或配置信息, 目前container级别还不支持网络和硬盘信息,具体性能项如下
| Metric Name | Description |
|---|---|
| cpu/limit | CPU hard limit in millicores. |
| cpu/node_capacity | Cpu capacity of a node. |
| cpu/node_allocatable | Cpu allocatable of a node. |
| cpu/node_reservation | Share of cpu that is reserved on the node allocatable. |
| cpu/node_utilization | CPU utilization as a share of node allocatable. |
| cpu/request | CPU request (the guaranteed amount of resources) in millicores. |
| cpu/usage | Cumulative CPU usage on all cores. |
| cpu/usage_rate | CPU usage on all cores in millicores. |
| filesystem/usage | Total number of bytes consumed on a filesystem. |
| filesystem/limit | The total size of filesystem in bytes. |
| filesystem/available | The number of available bytes remaining in a the filesystem |
| memory/limit | Memory hard limit in bytes. |
| memory/major_page_faults | Number of major page faults. |
| memory/major_page_faults_rate | Number of major page faults per second. |
| memory/node_capacity | Memory capacity of a node. |
| memory/node_allocatable | Memory allocatable of a node. |
| memory/node_reservation | Share of memory that is reserved on the node allocatable. |
| memory/node_utilization | Memory utilization as a share of memory allocatable. |
| memory/page_faults | Number of page faults. |
| memory/page_faults_rate | Number of page faults per second. |
| memory/request | Memory request (the guaranteed amount of resources) in bytes. |
| memory/usage | Total memory usage. |
| memory/working_set | Total working set usage. Working set is the memory being used and not easily dropped by the kernel. |
| network/rx | Cumulative number of bytes received over the network. |
| network/rx_errors | Cumulative number of errors while receiving over the network. |
| network/rx_errors_rate | Number of errors while receiving over the network per second. |
| network/rx_rate | Number of bytes received over the network per second. |
| network/tx | Cumulative number of bytes sent over the network |
| network/tx_errors | Cumulative number of errors while sending over the network |
| network/tx_errors_rate | Number of errors while sending over the network |
| network/tx_rate | Number of bytes sent over the network per second. |
| uptime | Number of milliseconds since the container was started. |
Prometheus集成了数据采集,存储,异常告警多项功能,是一款一体化的完整方案。 它针对大规模的集群环境设计了拉取式的数据采集方式、多维度数据存储格式以及服务发现等创新功能。
* 多维数据模型(有metric名称和键值对确定的时间序列)
* 灵活的查询语言
* 不依赖分布式存储
* 通过pull方式采集时间序列,通过http协议传输
* 支持通过中介网关的push时间序列的方式
* 监控数据通过服务或者静态配置来发现
* 支持多维度可视化分析和dashboard等
这个生态里包含的组件,大多是可选的: * 核心prometheus server提供收集和存储时间序列数据 * 大量的client libraries来支持应用业务代码的探针 * 适用于短时任务的push gateway * 基于Rails/SQL语句的可视化分析 * 特殊用途的exporter(包括HAProxy、StatsD、Ganglia等) * 用于报警的alertmanager * 支持命令行查询的工具 * 其他工具 大多数的组件都是用Go语言来完成的,使得它们方便构建和部署。
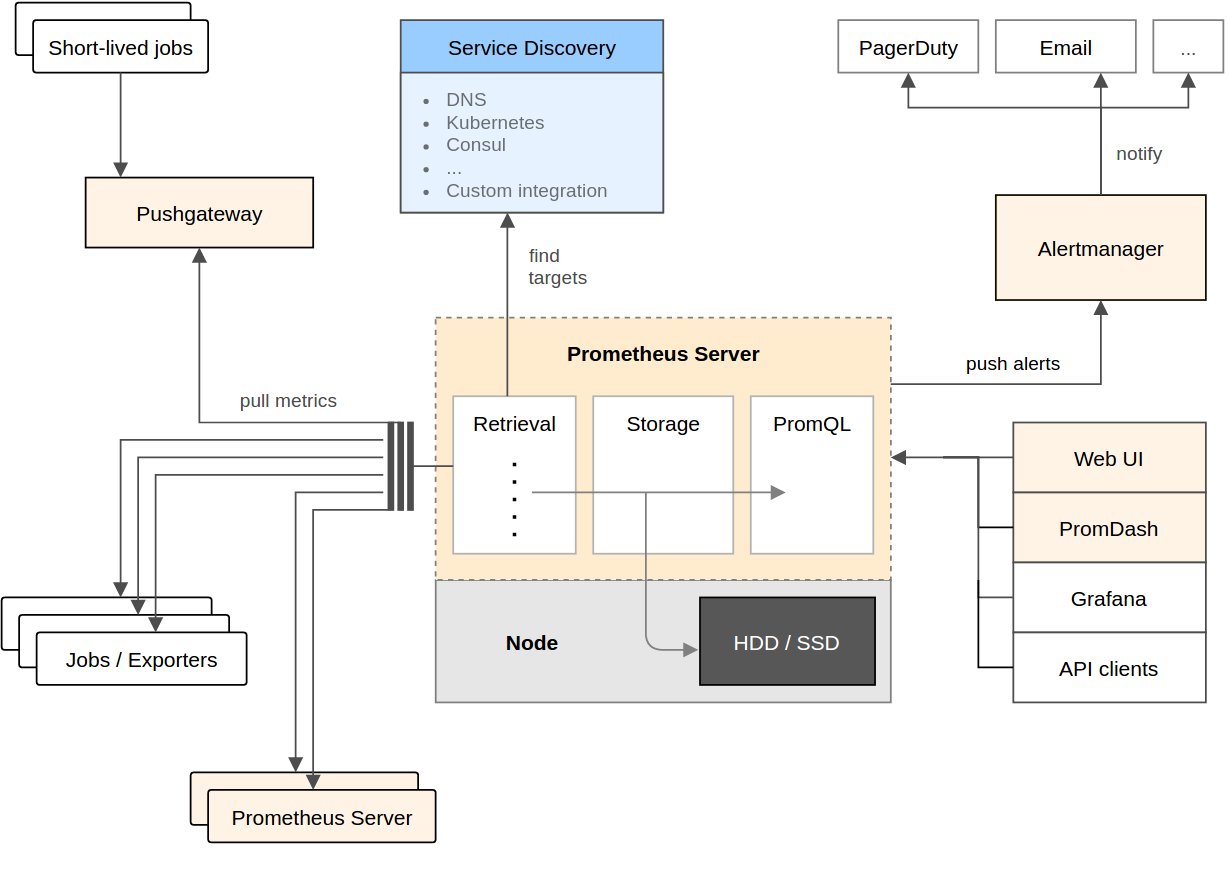
Promethues直接或通过短期Jobs的中介网关拉取收集指标。 它在本地存储所有抓取的数据样本,并对数据进行规则匹配检测,这样可以基于现有数据创建新的时间系列指标或生成警报。 PromDash或其他API使用者对收集的数据进行可视化。
下图是Redhat研发人员的回答
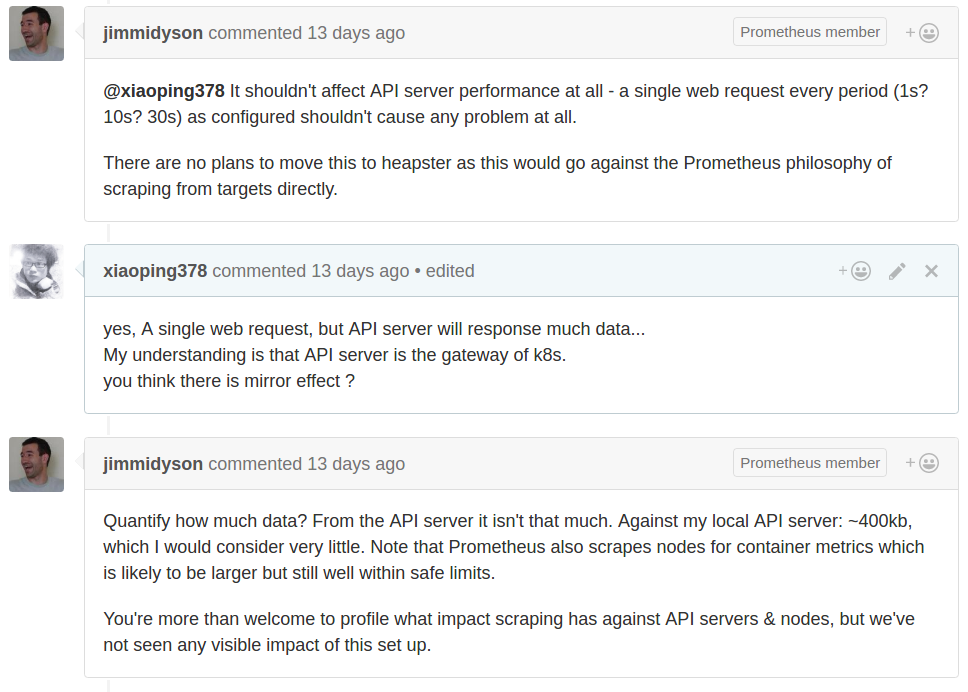
并不会对k8s产生太大的影响,其主要是通过api-server来发现需要监控的目标,然后会周期性的通过各个Node上kubelet来拉取数据。 更详细的讨论见这里
下文是基于k8s-monitor项目来说的
Prometheus is an open-source monitoring solution that includes the gathering of metrics, their storage in an internal time series database as well as querying and alerting based on that data.
It offers a lot of integrations incl. Docker, Kubernetes, etc.
Prometheus can also visualize your data. However, in this recipe we include another open-source tool, Grafana, for the visualization part, as it offers a more powerful and flexible way to generate visuals and dashboards.
If you just want to get Prometheus and Grafana up and running you can deploy the whole recipe with a single command instead of going through all steps detailed out below:
kubectl create --filename manifests/
First, we need to create the configuration for our Prometheus. For this we use a Config Map, which we later mount into our Prometheus pod to configure it. This way we can change the configuration without having to redeploy Prometheus itself.
kubectl create --filename manifests/prometheus-core-configmap.yaml
Then, we create a service to be able to access Prometheus.
kubectl create --filename manifests/prometheus-core-service.yaml
Finally, we can deploy Prometheus itself.
kubectl create --filename manifests/prometheus-core-deployment.yaml
Further, we need the Prometheus Node Exporter deployed to each node. For this we use a Daemon Set and a fronting service for Prometheus to be able to access the node exporters.
kubectl create --filename manifests/prometheus-node-exporter-service.yaml
kubectl create --filename manifests/prometheus-node-exporter-daemonset.yaml
Wait a bit for all the pods to come up. Then Prometheus should be ready and running. We can check the Prometheus targets at https://mycluster.k8s.gigantic.io/api/v1/proxy/namespaces/default/services/prometheus/targets
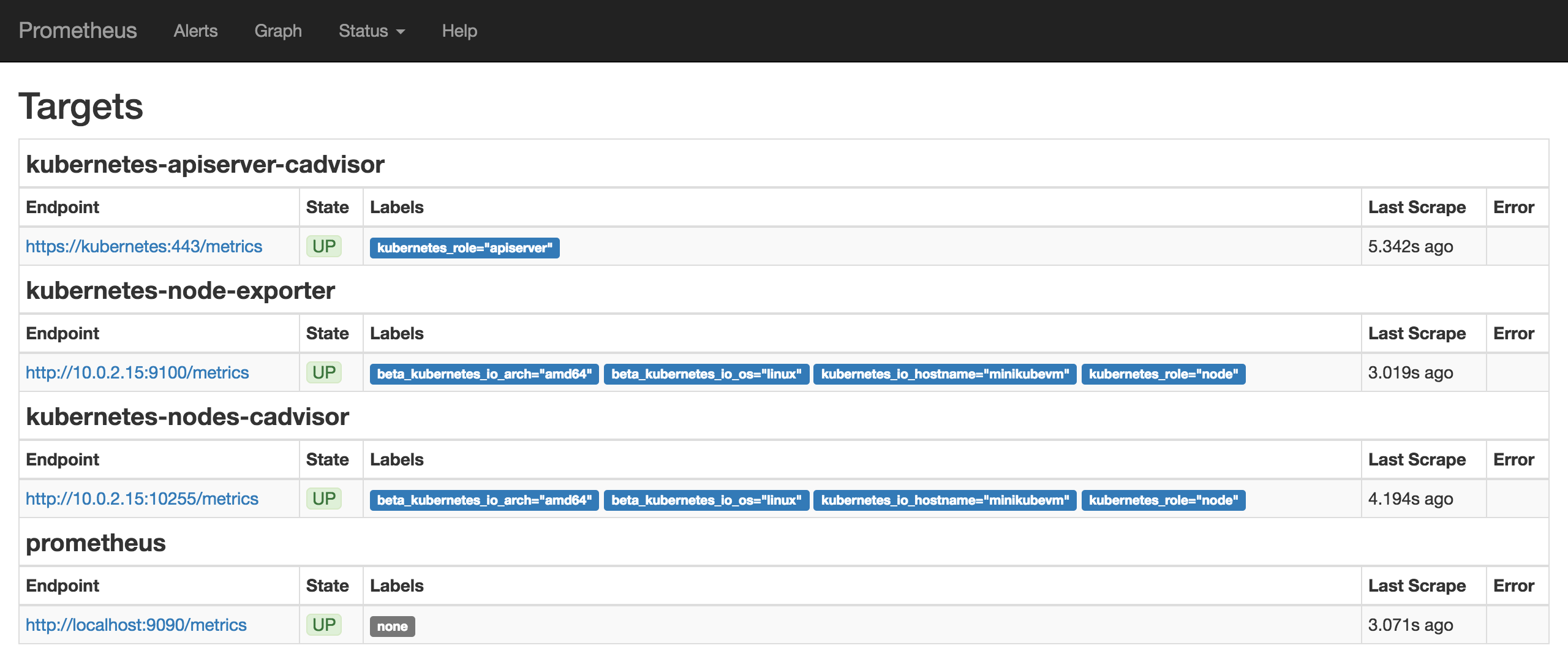
we need to create the configuration for our Alertmanager. For this we use a Config Map, which we later mount into our Alertmanager pod to configure it. This way we can change the configuration without having to redeploy Alertmanager itself.
kubectl create --filename manifests/prometheus-alert-configmap.yaml
Then, we create a service to be able to access Alertmanager.
kubectl create --filename manifests/prometheus-alert-service.yaml
Finally, we can deploy Alertmanager itself.
kubectl create --filename manifests/prometheus-alert-deployment.yaml
Wait a bit for all the pods to come up. Then Alertmanager should be ready and running. We can check the Alertmanager targets at https://mycluster.k8s.gigantic.io/api/v1/proxy/namespaces/default/services/alertmanager/
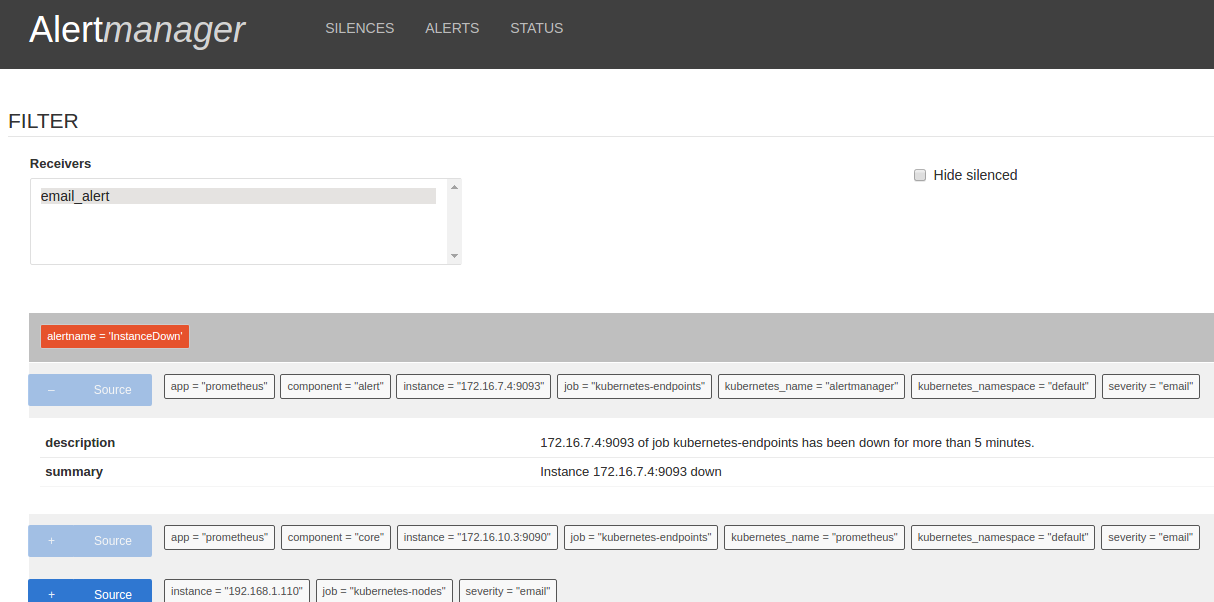
Now that we have Prometheus up and running we can deploy Grafana to have a nicer frontend for our metrics.
Again, we create a service to be able to access Grafana and a deployment to manage the pods.
kubectl create --filename manifests/grafana-services.yaml
kubectl create --filename manifests/grafana-deployment.yaml
Wait a bit for Grafana to come up. Then you can access Grafana at https://mycluster.k8s.gigantic.io/api/v1/proxy/namespaces/default/services/grafana/
TLDR: If you don't want to go through all the manual steps below you can let the following job use the API to configure Grafana to a similar state.
kubectl create --filename manifests/grafana-import-dashboards-job.yaml
Once we're in Grafana we need to first configure Prometheus as a data source.
Grafana UI / Data Sources / Add data source
Name: prometheusType: PrometheusUrl: http://prometheus:9090Add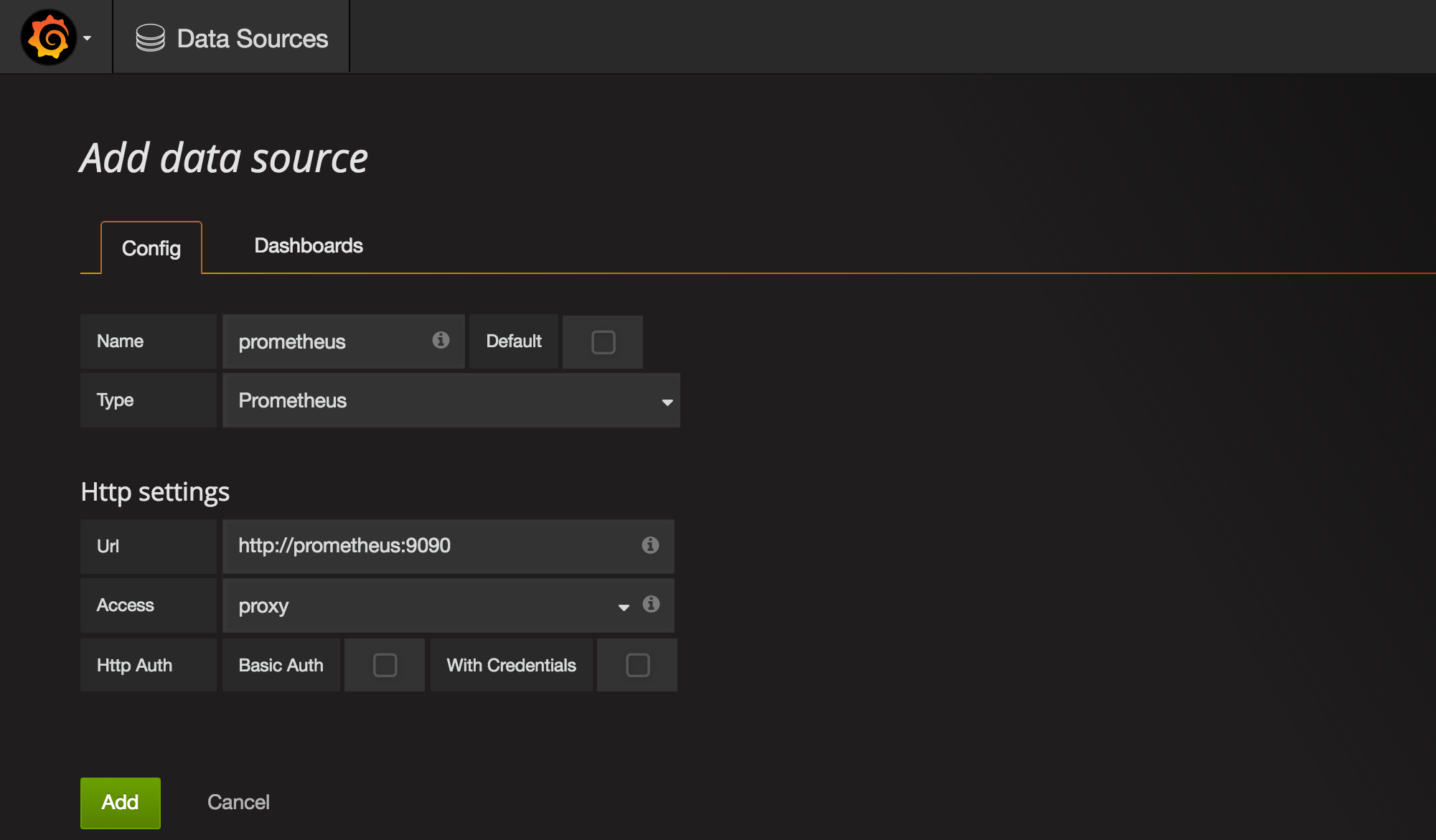
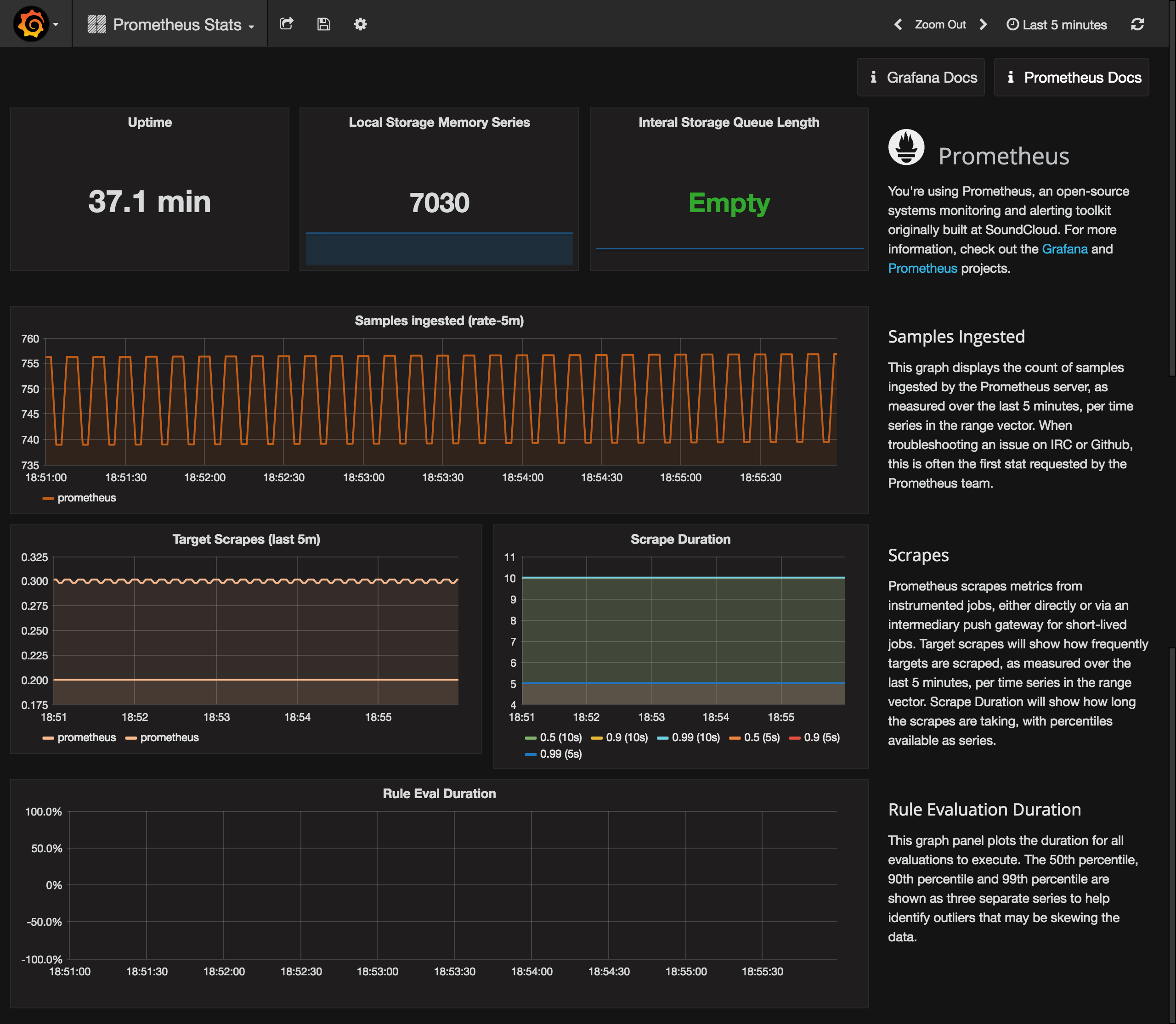
Then go to the Dashboards tab and import the Prometheus Stats dashboard, which shows the status of Prometheus itself.
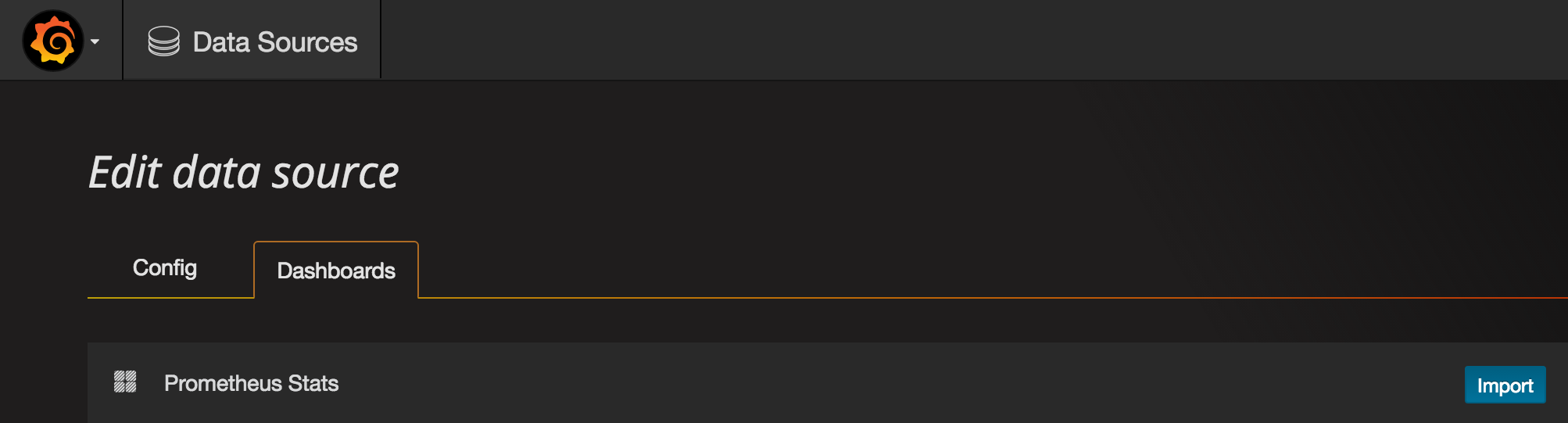
You can check it out to see how your Prometheus is doing.
Last, but not least we can import a sample Kubernetes cluster monitoring dashboard, to get a first overview over our cluster metrics.
Grafana UI / Dashboards / Import
Grafana.net Dashboard: https://grafana.net/dashboards/597LoadPrometheus: prometheusSave & Open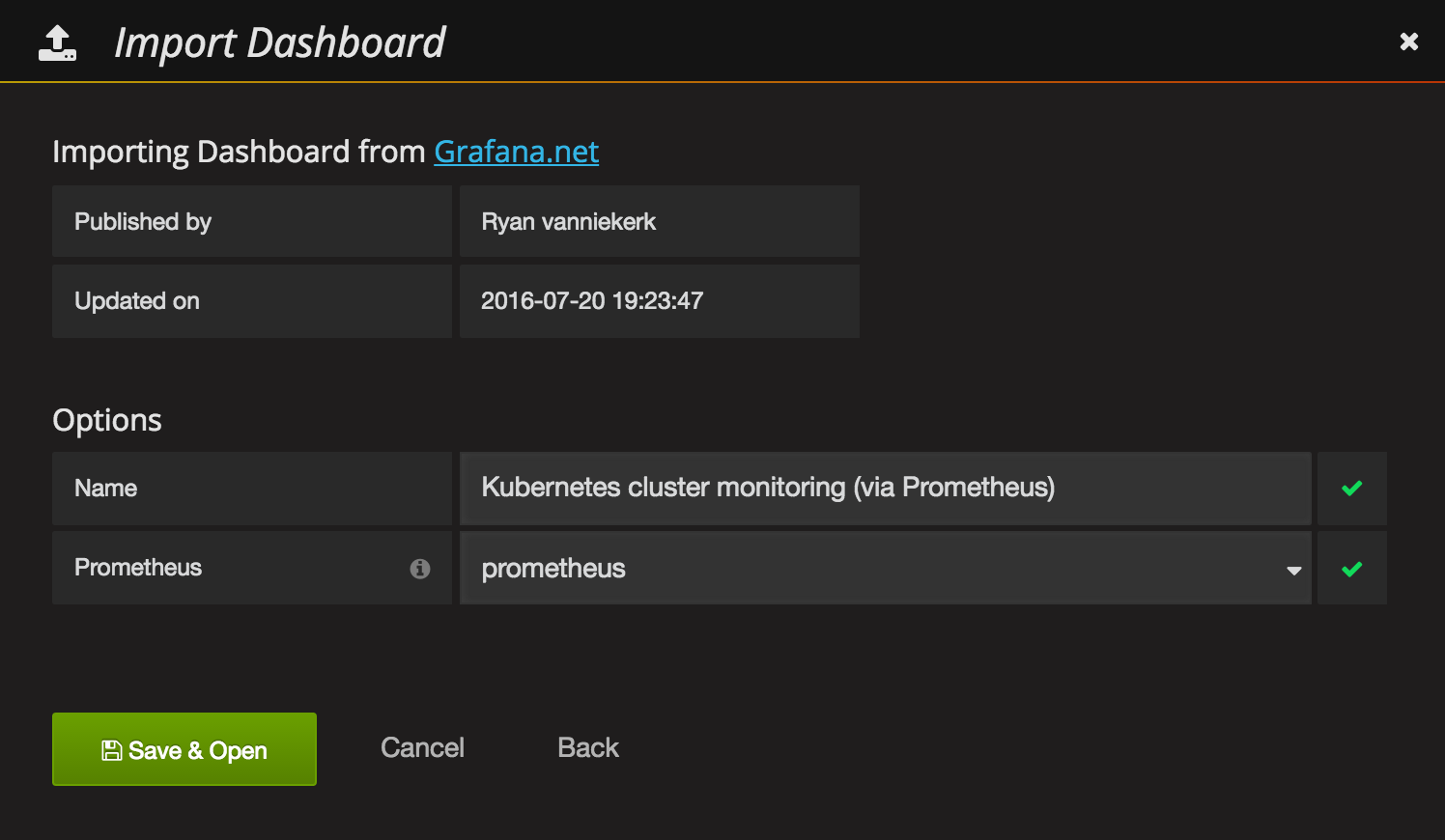
Voilá. You have a nice first dashboard with metrics of your Kubernetes cluster.
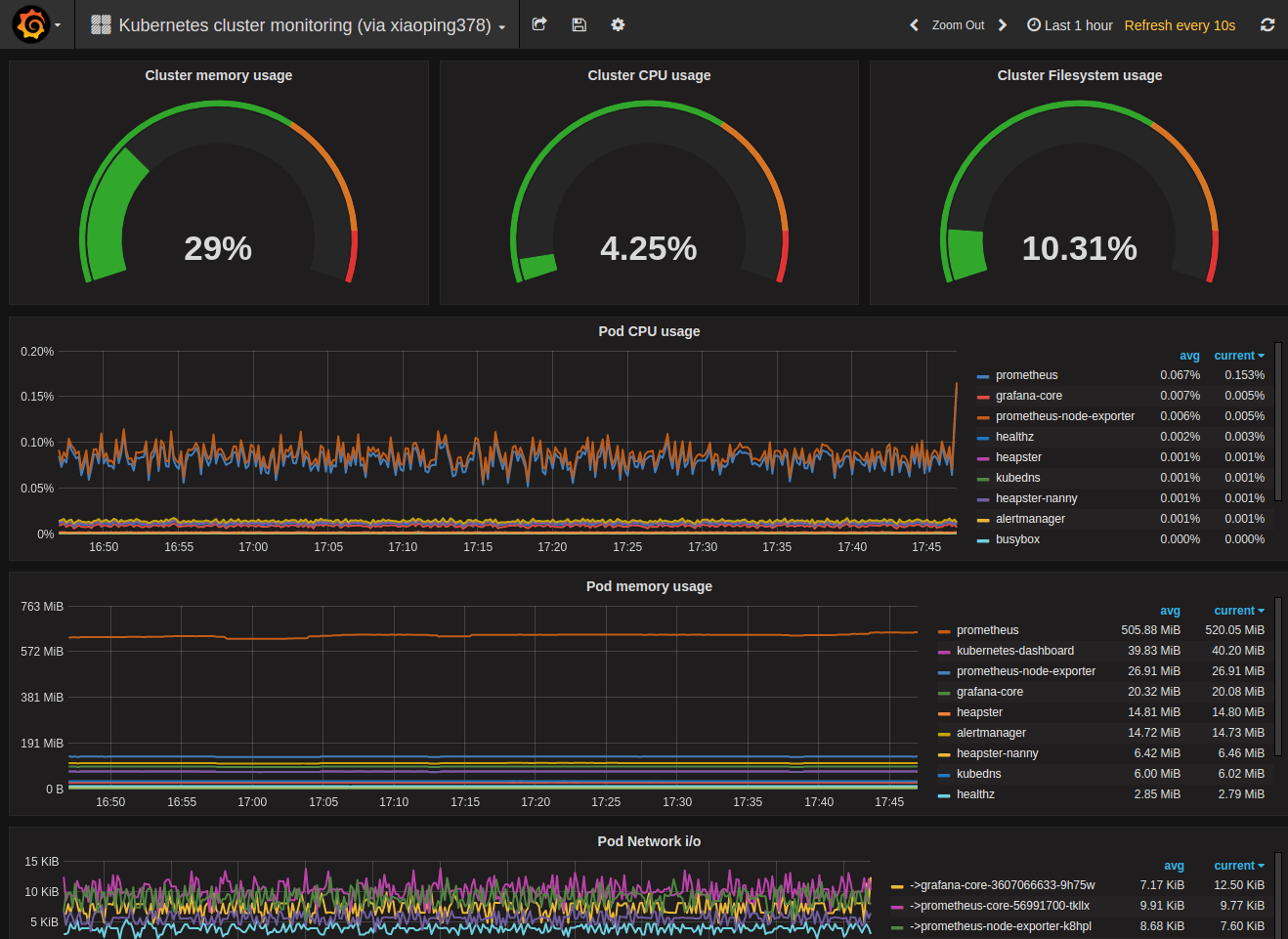
Next, you should get into the Grafana and Prometheus documentations to get to know the tools and either build your own dashboards or extend the samples from above.
You can also check out grafana.net for some more example dashboards and plugins.
More Alertmanager documentations in here
因为使用自签证书(reg.300.cn),所以需要把中间过程生成的ca.crt拷贝到需要pull/push的node上 (懒的翻译了,很详细的文档,已验证OK)
Because Harbor does not ship with any certificates, it uses HTTP by default to serve registry requests. This makes it relatively simple to configure. However, it is highly recommended that security be enabled for any production environment. Harbor has an Nginx instance as a reverse proxy for all services, you can configure Nginx to enable https.
##Getting a certificate
Assuming that your registry's hostname is reg.yourdomain.com, and that its DNS record points to the host where you are running Harbor. You first should get a certificate from a CA. The certificate usually contains a .crt file and a .key file, for example, yourdomain.com.crt and yourdomain.com.key.
In a test or development environment, you may choose to use a self-signed certificate instead of the one from a CA. The below commands generate your own certificate:
openssl req \
-newkey rsa:4096 -nodes -sha256 -keyout ca.key \
-x509 -days 365 -out ca.crt
If you use FQDN like reg.yourdomain.com to connect your registry host, then you must use reg.yourdomain.com as CN (Common Name). Otherwise, if you use IP address to connect your registry host, CN can be anything like your name and so on:
openssl req \
-newkey rsa:4096 -nodes -sha256 -keyout yourdomain.com.key \
-out yourdomain.com.csr
On Ubuntu, the config file of openssl locates at /etc/ssl/openssl.cnf. Refer to openssl document for more information. The default CA directory of openssl is called demoCA. Let's create necessary directories and files:
mkdir demoCA
cd demoCA
touch index.txt
echo '01' > serial
cd ..
If you're using FQDN like reg.yourdomain.com to connect your registry host, then run this command to generate the certificate of your registry host:
openssl ca -in yourdomain.com.csr -out yourdomain.com.crt -cert ca.crt -keyfile ca.key -outdir .
If you're using IP to connect your registry host, you may instead run the command below:
echo subjectAltName = IP:your registry host IP > extfile.cnf
openssl ca -in yourdomain.com.csr -out yourdomain.com.crt -cert ca.crt -keyfile ca.key -extfile extfile.cnf -outdir .
##Configuration of Nginx After obtaining the yourdomain.com.crt and yourdomain.com.key files, change the directory to Deploy/config/nginx in Harbor project.
cd Deploy/config/nginx
Create a new directory cert/, if it does not exist. Then copy yourdomain.com.crt and yourdomain.com.key to cert/, e.g. :
cp yourdomain.com.crt cert/
cp yourdomain.com.key cert/
Rename the existing configuration file of Nginx:
mv nginx.conf nginx.conf.bak
Copy the template nginx.https.conf as the new configuration file:
cp nginx.https.conf nginx.conf
Edit the file nginx.conf and replace two occurrences of harbordomain.com to your own host name, such as reg.yourdomain.com . If you use a customized port rather than the default port 443, replace the port "443" in the line "rewrite ^/(.*) https://$server_name:443/$1 permanent;" as well. Please refer to the installation guide for other required steps of port customization.
server {
listen 443 ssl;
server_name harbordomain.com;
...
server {
listen 80;
server_name harbordomain.com;
rewrite ^/(.*) https://$server_name:443/$1 permanent;
Then look for the SSL section to make sure the files of your certificates match the names in the config file. Do not change the path of the files.
...
# SSL
ssl_certificate /etc/nginx/cert/yourdomain.com.crt;
ssl_certificate_key /etc/nginx/cert/yourdomain.com.key;
Save your changes in nginx.conf.
##Installation of Harbor Next, edit the file Deploy/harbor.cfg , update the hostname and the protocol:
#set hostname
hostname = reg.yourdomain.com
#set ui_url_protocol
ui_url_protocol = https
Generate configuration files for Harbor:
./prepare
If Harbor is already running, stop and remove the existing instance. Your image data remain in the file system
docker-compose stop
docker-compose rm
Finally, restart Harbor:
docker-compose up -d
After setting up HTTPS for Harbor, you can verify it by the following steps:
Open a browser and enter the address: https://reg.yourdomain.com . It should display the user interface of Harbor.
On a machine with Docker daemon, make sure the option "-insecure-registry" does not present, and you must copy ca.crt generated in the above step to /etc/docker/certs.d/yourdomain.com(or your registry host IP), if the directory does not exist, create it. If you mapped nginx port 443 to another port, then you should instead create the directory /etc/docker/certs.d/yourdomain.com:port(or your registry host IP:port). Then run any docker command to verify the setup, e.g.
docker login reg.yourdomain.com
If you've mapped nginx 443 port to another, you need to add the port to login, like below:
docker login reg.yourdomain.com:port
##Troubleshooting
You may get an intermediate certificate from a certificate issuer. In this case, you should merge the intermediate certificate with your own certificate to create a certificate bundle. You can achieve this by the below command:
cat intermediate-certificate.pem >> yourdomain.com.crt
On some systems where docker daemon runs, you may need to trust the certificate at OS level. On Ubuntu, this can be done by below commands:
cp youdomain.com.crt /usr/local/share/ca-certificates/reg.yourdomain.com.crt
update-ca-certificates
On Red Hat (CentOS etc), the commands are:
cp yourdomain.com.crt /etc/pki/ca-trust/source/anchors/reg.yourdomain.com.crt
update-ca-trust
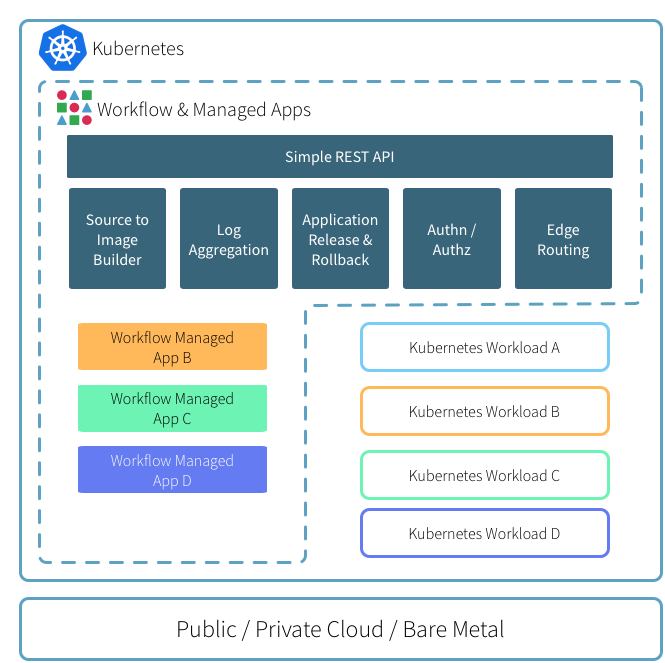
DEIS(目前已被微软收购)的workflow是开源的Paas平台,基于kubernetes做了一层面向开发者的CLI和接口,做到了让开发者对容器无感知的情况下快速的开发和部署线上应用。
workflow是 on top of k8s的,所有组件默认全是跑在pod里的,不像openshift那样对k8s的侵入性很大。
特性如下:
下面从环境搭建,安装workflow及其基本使用做个梳理。
可以通过k8s-deploy项目来离线安装高可用kubernetes集群,我这里是单机演示环境。
kubeadm init --kubernetes-version v1.6.2 --pod-network-cidr 12.240.0.0/12
#方便命令自动补全
source <(kubectl completion zsh)
#安装cni网络
cp /etc/kubernetes/admin.conf $HOME/.kube/config
kubectl apply -f kube-flannel-rbac.yml
kubectl apply -f kube-flannel.yml
#使能master可以被调度
kubectl taint node --all node-role.kubernetes.io/master-
#安装ingress-controller, 边界路由作用
kubectl create -f ingress-traefik-rbac.yml
kubectl create -f ingress-traefik-deploy.yml
helm相当于kubernetes里的包管理器,类似yum和apt的作用,只不过它操作的是charts(各种k8s yaml文件的集合,额外还有Chart.yaml -- 包的描述文件)可以理解为基于k8s的应用模板管理类工具, 后面会用它来安装workflow到上面跑起来的k8s集群里。
从k8s 1.6之后,kubeadm安装的集群,默认会开启RBAC机制,为了让helm可以安装任何应用,我们这里赋予tiller cluster-admin权限
kubectl create serviceaccount helm --namespace kube-system
kubectl create clusterrolebinding cluster-admin-helm --clusterrole=cluster-admin --serviceaccount=kube-system:helm
初始化helm:
➜ helm init --service-account helm
$HELM_HOME has been configured at /home/xxp/.helm.
Tiller (the helm server side component) has been installed into your Kubernetes Cluster.
Happy Helming!
➜ helm version
Client: &version.Version{SemVer:"v2.4.1", GitCommit:"46d9ea82e2c925186e1fc620a8320ce1314cbb02", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.4.1", GitCommit:"46d9ea82e2c925186e1fc620a8320ce1314cbb02", GitTreeState:"clean"}
安装后,默认导入了2个repos,后面安装和搜索应用时,都是从这2个仓里出的,当然也可以自己通过helm repo add添加本地私有仓
➜ helm repo list
NAME URL
stable https://kubernetes-charts.storage.googleapis.com
local http://127.0.0.1:8879/charts
helm的使用基本流程如下:
添加workflow的repo仓
helm repo add deis https://charts.deis.com/workflow
开始安装workflow,因为RBAC的原因,同样要赋予workflow各组件相应的权限,yml文件在[这里](https://gist.github.com/xiaoping378/798c39e0b607be4130db655f4873bd24)
kubectl apply -f workflow-rbac.yml --namespace deis
helm install deis/workflow --name workflow --namespace deis \
--set global.experimental_native_ingress=true,controller.platform_domain=192.168.31.49.xip.io
其中会拉取所需镜像,不出意外会有如下结果:
➜ kubectl --namespace=deis get pods
NAME READY STATUS RESTARTS AGE
deis-builder-1134410811-11xpp 1/1 Running 0 46m
deis-controller-2000207379-5wr10 1/1 Running 1 46m
deis-database-244447703-v2sh9 1/1 Running 0 46m
deis-logger-2533678197-pzmbs 1/1 Running 2 46m
deis-logger-fluentd-08hms 1/1 Running 0 42m
deis-logger-redis-1307646428-fz1kk 1/1 Running 0 46m
deis-minio-3195500219-tv7wz 1/1 Running 0 46m
deis-monitor-grafana-59098797-mdqh1 1/1 Running 0 46m
deis-monitor-influxdb-168332144-24ngs 1/1 Running 0 46m
deis-monitor-telegraf-vgbr9 1/1 Running 0 41m
deis-nsqd-1042535208-40fkm 1/1 Running 0 46m
deis-registry-2249489191-2jz3p 1/1 Running 2 46m
deis-registry-proxy-qsqc2 1/1 Running 0 46m
deis-router-3258454730-3rfpq 1/1 Running 0 41m
deis-workflow-manager-3582051402-m11zn 1/1 Running 0 46m
由于我们是本地ingress-controller, 必须保障deis-builder.$host可以被解析, 自行创建ingress of deis-builder.
kubectl apply -f deis-buidler-ingress.yml
确保traefik有如下状态:
如下操作注册,默认第一个用户为管理员用户,可操作所有其他用户。
➜ ~ kubectl get --namespace deis ingress
NAME HOSTS ADDRESS PORTS AGE
builder-api-server-ingress-http deis-builder.192.168.31.49.xip.io 80 18m
controller-api-server-ingress-http deis.192.168.31.49.xip.io 80 1h
➜ ~
➜ ~ deis register deis.192.168.31.49.xip.io
username: admin
password:
password (confirm):
email: xiaoping378@163.com
Registered admin
Logged in as admin
Configuration file written to /home/xxp/.deis/client.json
➜ ~
➜ ~ deis whoami
You are admin at http://deis.192.168.31.49.xip.io
本文主要介绍k3s的安装和核心组件解读。
k3s是all-in-one的轻量k8s发行版,把所有k8s组件打包成一个不到100M的二进制文件了。具备如下显著特点:
官方提供了一键安装脚本install.sh ,执行curl -sfL https://get.k3s.io | sh -可一键安装server端。此命令会从https://update.k3s.io/v1-release/channels/stable取到最新的稳定版安装,可以通过INSTALL_K3S_VERSION环境变量指定版本,本文将以1.19为例。
启动 k3s server端(master节点).
curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION=v1.19.16+k3s1 sh -
由于网络原因,可能会失败,自行想办法下载下来,放置
/usr/local/bin/k3s,附上执行权限chmod a+x /usr/local/bin/k3s, 然后上面的命令加上INSTALL_K3S_SKIP_DOWNLOAD=true再执行一遍即可。
安装里log里会输出一些重要信息:
kubectl、crictl、卸载脚本、systemd service
不出意外,k3s server会被systemd启动,执行命令查看systemctl status k3s或者通过软链的kubectl验证是否启动成功:
➜ kubectl get no
NAME STATUS ROLES AGE VERSION
gitlab-server Ready master 6m43s v1.19.16+k3s1
(Optional) 启动 k3s agent端 (添加worker节点).
curl -sfL https://get.k3s.io | K3S_URL=https://172.25.11.130:6443 K3S_TOKEN=bulabula INSTALL_K3S_VERSION=v1.19.16+k3s1 sh -
K3S_TOKEN内容需要从server端的/var/lib/rancher/k3s/server/node-token文件取出K3S_URL中的IP是master节点的IP。默认kubectl通过localhost访问本地集群,所以上文敲kubectl是没问题的,如果要被外部访问或者纳管的话,可以把kubeconfig文件拷走,默认路径是 /etc/rancher/k3s/k3s.yaml
。记得修改文件内的server字段,改成外部可访问到的IP。
TODO.
kubesphere 自研环境篇
首先调整心态,这是一个新的生态,秉承学习的心态。
git clone https://github.com/kubesphere/kubesphere.git
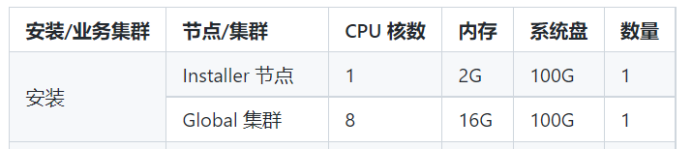
本文主要介绍当前最新版本TkeStack 1.8.1 的TKEStack的all-in-one安装、多租户和多集群管理功能解读。
官方推荐至少需要2节点方可安装,配置如下,硬盘空间一定要保障。也支持ALL-in-ONE的方式安装,但有BUG。
启动init服务,即安装tke-installer和registry服务,安装命令行如下:
arch=amd64 version=v1.8.1 \
&& wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} \
&& sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 \
&& chmod +x tke-installer-linux-$arch-$version.run \
&& ./tke-installer-linux-$arch-$version.run
如上命令执行后,会下载8G左右的安装包,并执行解压后的install.sh脚本,启动3个容器:1个为tke-installer和另2个为registry仓,且为containerd容器,需要使用nerdctl [images | ps]等命令查看相关信息。
通过查看脚本,上文启动的本地registry的启动命令等效如下:
nerdctl run --name registry-https -d --net=host --restart=always -p 443:443 \
-v /opt/tke-installer/registry:/var/lib/registry \
-v registry-certs:/certs \
-e REGISTRY_HTTP_ADDR=0.0.0.0:443 \
-e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/server.crt \
-e REGISTRY_HTTP_TLS_KEY=/certs/server.key \
tkestack/registry-amd64:2.7.1
还有个http 80的registry,这里不贴了,后面的部分坑,就是这里埋下的,预先占用了节点的80和443端口,后面tke的gateway pod会启动失败。
上章节执行完后,会启动tke-installer(一个web操作台),通过访问本地8080端口,可访问界面操作安装global集群。按照官方指引操作就行,此处不表。另外需要说明的是在安装过程中,如果要查看本地容器,不能使用docker ps了,需要使用nerdctl -n k8s.io ps。整个安装过程是使用ansible和kubeadm完成的,kubelet是通过systemd启动的,k8s组件为静态pod。
因为我是使用的ALL-in-ONE安装,遇到了不少问题,可详见FAQ如何解决。安装成功后会提示如下指引:
默认初始安装后,很多pod是双副本的,我这里仅是验证功能使用,全部改成了单副本。
tkestack采用Casbin框架实现的权限管理功能,默认集成的Model,查看源码得知:
[request_definition]
r = sub, dom, obj, act
[policy_definition]
p = sub, dom, obj, act, eft
[role_definition]
g = _, _, _
[policy_effect]
e = some(where (p.eft == allow)) && !some(where (p.eft == deny))
[matchers]
m = g(r.sub, p.sub, r.dom) && keyMatchCustom(r.obj, p.obj) && keyMatchCustom(r.act, p.act)
实现了多租户级的RBAC权限模型。
2022-01-19 14:43:32.225 error tke-installer.ClusterProvider.OnCreate.EnsureKubeadmInitPhaseWaitControlPlane check healthz error {"statusCode": 0, "error": "Get \"https://****:6443/healthz?timeout=30s\": net/http: TLS handshake timeout"}
我这里是因为在installer上指定的master的IP为外网IP(我使用外网IP是有原因的,穷... 后面需要跨云厂商组集群),通过查看kubelet日志提示本机找不到IP,如下开启网卡多IP,可通过。
ip addr add 118.*.*.* dev eth0
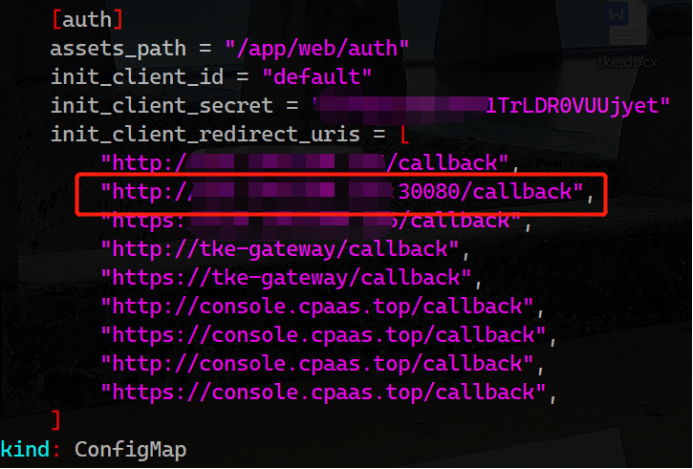
我这里是因为init节点和gobal master节点,共用了一个,本registry服务占用了80和443端口,需要修改gateway hostNetwork为false,另外可以通过修改svc 为nodePort,还需要修改targetPort,官方现在这里有bug,不知道为指到944*的端口上,我这里设置的30080来访问安装好的集群。
官方没有相关说明,一切都是ALL-in-ONE的原因,我改动了默认集群console的访问端口为30080。。。 通过查看源码发现是每次认证时dex会校验tke-auth-api向它注册过的合法client地址。于是我就修改了tke命名空间下tke-auth-api的相关configmap:
重启tke-auth-api后,问题依旧存在,继续源码走查,发现这玩意儿叫init真的只发挥一次作用,改完配置,不会重新读取,细读逻辑发现etcd中不存在这个key,会重新读取写入一次,于是决定删除etcd中的相关key。
etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/apiserver-etcd-client.crt --key=/etc/kubernetes/pki/apiserver-etcd-client.key del /tke/auth-api/client/default --prefix
ssh信息设置完后,如果中间出问题,会陷入无限重试...
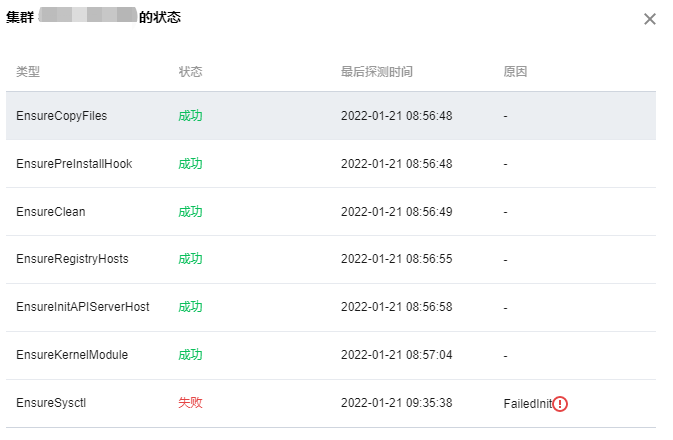
遇事不决,看日志,找不到日志,看源码...
通过翻找源码,发现是platform相关组件在负责,查看相关日志kubectl -n logs tke-platform-controller-*** --tail 100 -f,定位问题,我这里是以前各种安装的残留信息,导致添加节点初始化失败。删除之... 解决。
为避免添加节点no clean再次出现问题,建议预先执行下clean.sh脚本。
如下使用,可以愉快的敲命令了,因为我是用oh-my-zsh的shell主题(没有自动加载kubectl plugin),kubectl的命令补全使用zsh,可根据实际情况调整。
source <(nerdctl completion bash)
source <(kubectl completion zsh)
主要记录介绍以前个人的Openshfit实践总结。
不知道为什么openshift在国内热度这么低,那些要做自己容器云的公司,不知道有openshift项目的存在么?完全满足我的需求。
docker负责应用的隔离打包,k8s提供集群管理和容器的编排服务,而openshfit则负责整个应用的生命周期:
先说下自接触到openshift项目就遇到的一个困惑,就是openshift origin/enterprise /online/dedicated/ocp之间的关系: orgin相当于Fedora, 其他的相当于RHEL
接下来谈下我用自己的笔记本实践的过程与感受:
本人日常基于ubuntu16.04办公,所以用oc直接上, oc相当于kubectl
这里直接下载oc客户端,或者自行编译, 编译结果在_output目录下
git clone --depth=1 https://github.com/openshift/origin.git
cd origin && make
mv _output/local/bin/linux/amd64/oc /usr/local/bin
启动openshift, 默认开启监控并初始安装自最新版本,当前是v1.5.0-alpha.2
oc cluster up --metrics=true --version=latest --insecure-skip-tls-verify=true --public-hostname=air13
过程中会拉取所需镜像, 我这里显示比较多,之前已经做了些实验
➜ ~ docker images | grep openshift | awk '{print $1}'
openshift/node
openshift/origin-sti-builder
openshift/origin-docker-builder
openshift/origin-deployer
openshift/origin-gitserver
openshift/origin-docker-registry
openshift/origin-haproxy-router
openshift/origin
openshift/hello-openshift
openshift/openvswitch
openshift/origin-pod
openshift/origin-metrics-cassandra
openshift/origin-metrics-hawkular-metrics
openshift/origin-metrics-heapster
openshift/origin-metrics-deployer
openshift/mysql-55-centos7
openshift/origin-logging-curator
openshift/origin-logging-fluentd
openshift/origin-logging-deployment
openshift/origin-logging-elasticsearch
openshift/origin-logging-kibana
openshift/origin-logging-auth-proxy
启动后,会打印如下信息
OpenShift server started.
The server is accessible via web console at:
https://air13:8443
The metrics service is available at:
https://metrics-openshift-infra.192.168.31.49.xip.io
You are logged in as:
User: developer
Password: developer
To login as administrator:
oc login -u system:admin
打开浏览器,访问https://air13:8443,默认用developer登录,其实现在任意用户任意密码都可以的。
web console里是空空如野的,可以临时授权developer用户操作所有项目
oc adm policy add-cluster-role-to-user cluster-admin developer
2.技巧总结
source <(oc completion bash)
默认监控占用的资源太大了,可以如下降低资源占用,当然也可以web操作限制资源利用率
oc env rc hawkular-cassandra-1 MAX_HEAP_SIZE=1024M -n openshift-infra
#重建下变量才会生效
oc scale rc hawkular-cassandra-1 --replicas 0 -n openshift-infra
oc scale rc hawkular-cassandra-1 --replicas 1 -n openshift-infra
因为是rc,所以直接杀掉没关系,要不env不生效
自己编译离线文档
# 下载源文件
git clone --depth=1 https://github.com/openshift/openshift-docs.git
# 编译
cd openshift-docs && asciibinder build
# 结果会存放在 _preview下,
cd _preview && python -m SimpleHTTPServer
#打开浏览器访问127.0.0.1:8000
推荐此人blog,有几篇干货
3.后面会重点说下权限/资源管理和整个app开发的流程
重点介绍 project,limitRange,resourceQuta和 user, group, rule,role,policy,policybinding的关系, 我刚接触时,这几个概念老搞不太清楚,这里梳理下
可以对计算资源的大小和对象类型的数量来进行配额限制。
ResourceQuota是面向project(namespace的基础上加了些注解)层面的,只有集群管理员可以基于namespace设置。
limtRange是面向pod和container级别的,openshift额外还可以限制 image, imageStream和pvc,
也是只有集群管理员才可以基于project设置,而开发人员只能基于pod(container)设置cpu和内存的requests/limits。
看看具体可以管理哪些资源,期待网络相关的也加进来.简单来讲,可以基于project来限制可消耗的内存大小和可创建的pods数量
// The following identify resource constants for Kubernetes object types
const (
// Pods, number
ResourcePods ResourceName = "pods"
// Services, number
ResourceServices ResourceName = "services"
// ReplicationControllers, number
ResourceReplicationControllers ResourceName = "replicationcontrollers"
// ResourceQuotas, number
ResourceQuotas ResourceName = "resourcequotas"
// ResourceSecrets, number
ResourceSecrets ResourceName = "secrets"
// ResourceConfigMaps, number
ResourceConfigMaps ResourceName = "configmaps"
// ResourcePersistentVolumeClaims, number
ResourcePersistentVolumeClaims ResourceName = "persistentvolumeclaims"
// ResourceServicesNodePorts, number
ResourceServicesNodePorts ResourceName = "services.nodeports"
// ResourceServicesLoadBalancers, number
ResourceServicesLoadBalancers ResourceName = "services.loadbalancers"
// CPU request, in cores. (500m = .5 cores)
ResourceRequestsCPU ResourceName = "requests.cpu"
// Memory request, in bytes. (500Gi = 500GiB = 500 * 1024 * 1024 * 1024)
ResourceRequestsMemory ResourceName = "requests.memory"
// Storage request, in bytes
ResourceRequestsStorage ResourceName = "requests.storage"
// CPU limit, in cores. (500m = .5 cores)
ResourceLimitsCPU ResourceName = "limits.cpu"
// Memory limit, in bytes. (500Gi = 500GiB = 500 * 1024 * 1024 * 1024)
ResourceLimitsMemory ResourceName = "limits.memory"
)
openshift额外支持的images相关的限制策略
// ResourceImageStreams represents a number of image streams in a project.
ResourceImageStreams kapi.ResourceName = "openshift.io/imagestreams"
// ResourceImageStreamImages represents a number of unique references to images in all image stream
// statuses of a project.
ResourceImageStreamImages kapi.ResourceName = "openshift.io/images"
// ResourceImageStreamTags represents a number of unique references to images in all image stream specs
// of a project.
ResourceImageStreamTags kapi.ResourceName = "openshift.io/image-tags"
此外,除了可以设置额度Quantity外,还可以指定配额的作用范围Scopes,其实就是作用于哪类pod上的:
目前只有pods数和计算资源(cpu,内存)才能指定作用域
// A ResourceQuotaScope defines a filter that must match each object tracked by a quota
type ResourceQuotaScope string
const (
// Match all pod objects where spec.activeDeadlineSeconds,这个是标明pod的运行时长参数
ResourceQuotaScopeTerminating ResourceQuotaScope = "Terminating"
// Match all pod objects where !spec.activeDeadlineSeconds , 长期运行的pod
ResourceQuotaScopeNotTerminating ResourceQuotaScope = "NotTerminating"
// Match all pod objects that have best effort quality of service, 只能用来描述资源无上限的pod数
ResourceQuotaScopeBestEffort ResourceQuotaScope = "BestEffort"
// Match all pod objects that do not have best effort quality of service, 资源有上限的pod
ResourceQuotaScopeNotBestEffort ResourceQuotaScope = "NotBestEffort"
)
下面举个例子
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources-long-running
spec:
hard:
pods: "4"
limits.cpu: "4"
limits.memory: "2Gi"
scopes:
- NotTerminating
上面的意思即是, 限制长期运行的pod最多只能创建4个,且共用4c和2G内存
如果不指定scopes的话,是描述的所有scopes的限制;
本文参考这里
可以看到,通过资源配额管理,可以帮助我们解决以下问题:
控制计算资源使用量
我们在实际生产环境中经常遇到的情况是,用户申请了过多的资源,用户应用的资源使用率太低,造成了资源的浪费。管理员通常会给集群设置超卖系数,来提高整个集群的资源使用率;另外管理员也会给用户设置资源配额上限,来限制用户使用资源的数量。通过上面的介绍我们可以看到,kubernetes的资源配额,我们可以从应用的层次上来进行配额管理,可以设置不同应用的资源配额上限。
控制besteffort类型POD资源使用量
如果POD中的所有容器都没有设置request和limit,那么这些POD的QoS类型是besteffort,这种类型的POD更方便kubernetes进行调度,但是存在的问题是,如果不对这些POD进行资源管理,那么就会导致这个kubernetes集群资源过载,会影响这个集群中的所有应用,所以通过将资源配额管理的作用范围设置成besteffort,kubernetes可以通过限制这些POD的资源,避免整个集群资源过载。
控制长期运行的应用和短暂运行的应用资源使用率
在实际使用中,在kubernetes集群中会同时存在两种类型的应用,一种是长期运行的应用,比如网站这种web应用,还有一种就是短暂运行的应用,比如编译网站的这种应用。通过资源配额管理,可以同时对这两种不同类型的应用设置资源使用上限,来控制不同应用的资源使用。
limtRange是面向pod和container级别的,为什么只能集群管理员才可设置呢,因为这个的提出是为了防止有些应用忘记加资源边界的限定,而占用过多的资源,那么有了limitRange就给它来个默认限制。
apiVersion: "v1"
kind: "LimitRange"
metadata:
name: "core-resource-limits"
spec:
limits:
- type: "Pod"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "200m"
memory: "6Mi"
- type: "Container"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "100m"
memory: "4Mi"
default:
cpu: "300m"
memory: "200Mi"
defaultRequest:
cpu: "200m"
memory: "100Mi"
maxLimitRequestRatio:
cpu: "10"
- type: "openshift.io/Image"
max:
storage: "1Gi"
- type: "openshift.io/ImageStream"
max:
openshift.io/image-tags: "10"
openshift.io/images: "12"
如上使用oc create后,会看到我们对某namespace下的pod和container做了默认的资源设置,

这里不涉及到认证登录的介绍,openshfit支持很多认证方式,比如AllowAll,CA认证, HTPasswd, KeyStone, LDAP, Oauth等,这里为了简化,用默认的AllowAll来做权限控制的说明
权限管理,即访问API资源之前,必须要经过的访问策略校验,主要分为5种: AlwaysDeny、AlwaysAllow(默认)、ABAC、RBAC、Webhook
主要说明user, group, rule,role,policy,policybinding之间的关系,以及提出这些概念,各自是为了解决什么问题
说到user其实就是一个用户账号(userAccount),用它来和k8s集群做交互(登录,kubectl等), 但还有一个容易混淆的概念就是sercieAccount,有了userAccount为什么还又来个serviceAccount的设计, 这两者有什么区别 ? 以下是kubernetes官方对两者的解释
user account是为人类设计的,而service account则是为跑在pod里的进程用的,运行在pod里的进程需要调用Kubernetes API以及非Kubernetes API的其它服务(如image repository/被mount到pod上的NFS volumes中的file等);
user account是global的,即跨namespace使用;而service account是namespaced内的,即仅在所属的namespace下使用;
user account可能会涉及到很多权限设定和商业逻辑在里面,而后者是更轻量级的,是集群用户针对某namespace内的服务使用的,一般遵循最小特权原则,如监控服务需要访问APIsever等;
useraccount需要借助第三方实现,后者系统都会默认在namesspace里创建default,亦可自定义
两者大部分流程是一致的,都是要先认证通过再校验权限,然后才是action, 实际上一般是由userAccount来控制serviceAccount来完成特定的任务, 比如一个用户A自建了服务1和服务2, 但只想把服务2开发给用户B,这样的serviceAccount就可以排上用场了, 又或者我有几个服务,有了serviceAccount就可以来限制用户的访问权限(list, watch, update, delete)了.
说到group就是方便对user的权限批量操作而设计;
用户可以被分配到一个或多个组,每个组代表一组特定的用户。组在同时向多个用户管理权限时非常有用。
rule是规则, 是对一组对象上被允许的动作(get, list, create, update, delete, deletecollection 和 watch)描述,可操作对象主要是 container,images,pod,servcie, project, user, build, imagestream, dc, route, templeate。
role 就是规则的集合,俗称角色, 不同对象上的不同动作,可以任意组成各种角色,系统默认的有 admin basic-user cluster-admin cluster-admin edit self-provisioner view;
policy,是策略, 保存特定namespace的所有角色roles的对象。 每个命名空间最多只有一个Policy策略。
rolebinding, 就是把user或者group与角色role进行关联,注意. user和group可以被关联到多个roles
pollicybing, 就是就是多个rolebindings的描述;
这样看,policy的概念提出有点儿扯淡了,感觉没什么用,其实不然,policy的提出主要是为了区分cluster-policy和local-policy的。
cluster policy是适用于所有namespace的角色和绑定; local policy则是试用于具体的某个namespace的;
以上可以通过oc describe clusterPolicy default来看查看所有详细的信息;
小节:
可以通过oc policy can-i --list查看自己可以干些什么
还可以通过oc policy who-can <动作> <资源对象>, 比如说查看谁能get pod之类的,就是oc policy who-can get pod
➜ openshift-docs git:(master) ✗ oc policy who-can get pod
Namespace: myproject
Verb: get
Resource: pods
Users: developer
system:admin
system:serviceaccount:default:pvinstaller
system:serviceaccount:myproject:deployer
system:serviceaccount:openshift-infra:build-controller
system:serviceaccount:openshift-infra:deployment-controller
system:serviceaccount:openshift-infra:deploymentconfig-controller
system:serviceaccount:openshift-infra:endpoint-controller
system:serviceaccount:openshift-infra:namespace-controller
system:serviceaccount:openshift-infra:pet-set-controller
system:serviceaccount:openshift-infra:pv-binder-controller
system:serviceaccount:openshift-infra:pv-recycler-controller
Groups: system:cluster-admins
system:cluster-readers
system:masters
system:nodes
如果openshift自带的角色不能满足的话,还可以自定义角色role
$ oc get clusterrole view -o yaml > clusterrole_view.yaml
$ cp clusterrole_view.yaml localrole_exampleview.yaml
$ vim localrole_exampleview.yaml
# 1. Update kind: ClusterRole to kind: Role
# 2. Update name: view to name: exampleview
# 3. Remove resourceVersion, selfLink, uid, and creationTimestamp
$ oc create -f path/to/localrole_exampleview.yaml -n <project_you_want_to_add_the_local_role_exampleview_to>
下面的所有操作,都可以通过cli,web console,RestFul API实现,默认使用cli说明
这里是接着oc cluster up后,来说的, 默认oc whoami是 developer,拥有admin的Role角色,俗称项目经理(管理员)
oc delete project myproject
oc new-project eshop --display-name="电商项目" --description="一个神奇的网站"
现在项目管理员可以创建任意多个项目,从前面的源码可以看到目前是没法针对项目管理员去限制可创建项目上限的。
#oc status
In project 电商项目 (eshop) on server https://192.168.31.49:8443
You have no services, deployment configs, or build configs.
Run 'oc new-app' to create an application.
空空如也,有提示语句提示可通过oc new-app去创建具体应用的
前面也说过,openshift的核心就是围绕应用的整个生命周期来的,所以从new-app说起
new-app的入口是NewCmdNewApplication(), 大部分实现是 func (c *AppConfig) Run() (*AppResult, error) 感兴趣的可以根据源码来理解openshift的devops理念。
# oc new-app -h
#此处省略。。。
Usage:
oc new-app (IMAGE | IMAGESTREAM | TEMPLATE | PATH | URL ...) [options]
#此处省略。。。
有很多灵活简便的方式来创建应用,甚至可以直接oc new-app mysql来创建一个mysql服务
比如下面的例子,是基于nodejs-ex项目的master分支,创建应用
oc new-app https://github.com/xiaoping378/nodejs-ex.git#master
接着上面的nodejs-ex项目来说, 实际上,oc new-app就做了两件事,先build, 再deploy。
new-app一般会先创建一个bc, bc会产出一个iamge,new-app典型的还会创建一个dc,去部署新生成的image,也会创建相应的service来负载均衡方访问刚部署上的镜像里的业务。
这一切都是自动完成的,因为openshift origin里面有一些检测机制和默认规则,下面就针对上面那条命令看看内部都发生了什么
首先openshift会执行 git ls-remote, 来查看此项目的所有remote分支,
如果存在master分支,下一步则直接clone和checkout了
checkout后,接着就是根据解析规则来定义如何build了。
build策略
首先会探测nodejs-ex项目根目录下,是否有dockerfile或者jenkinsfile,如果两者都没有则会根据“典型文件”判断这个项目的开发语言, 举例
如果存在app.json或者package.json文件,则认为是nodejs类型的项目, 更多的典型文件如下:
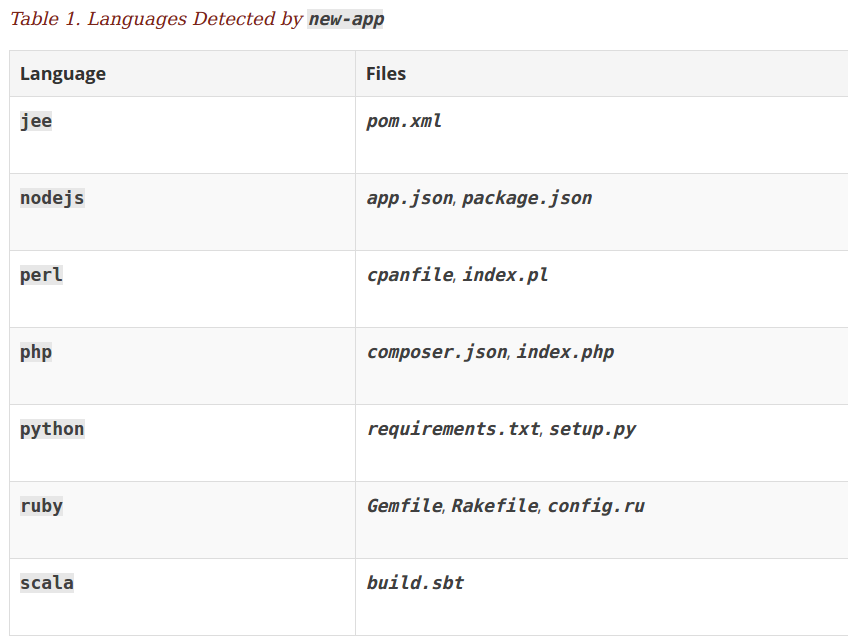
这部分的代码实现主要在 detector.go
未完,待续。。。
主要涉及到一键发布,快速回滚,弹性伸缩,蓝绿部署方面。
启动openshift
oc cluster up --version=v1.5.0-rc.0 --metrics --use-existing-config=true
默认负责监控的pods占用资源太大了,可以这样限制下,或者cluster up时不加 --metrics
oc login -u system:admin
oc env rc hawkular-cassandra-1 MAX_HEAP_SIZE=1024M -n openshift-infra
#重建下,变量才会生效
oc scale rc hawkular-cassandra-1 --replicas 0 -n openshift-infra
oc scale rc hawkular-cassandra-1 --replicas 1 -n openshift-infra
建立本地Git仓
默认官方给出的例子基本都需要和Github结合,实在不好本地实战演示,所以本地要来一个gogs代码仓。
oc login -u devloper
oc new-project ci
#先拉取所依赖镜像
docker pull openshiftdemos/gogs:0.9.97
docker pull centos/postgresql-94-centos7
#创建gogs服务,并禁用webhook时的TLS校验,不然无法触发build
oc new-app -f https://raw.githubusercontent.com/xiaoping378/gogs-openshift-docker/master/openshift/gogs-persistent-template.yaml -p SKIP_TLS_VERIFY=true -p HOSTNAME=gogs-ci.192.168.31.49.xip.io
上面的HOSTNAME,注意要换成自己宿主机的IPv4地址,默认创建的其他服务的路由都是这个形式的,
有个有意思的地方,为什么默认路由会是这种 name+IP+xip.io 形式呢,奥秘在 http://xip.io 的公共服务上。
这其实是个特殊的域DNS server,比如我们查询域名gogs-ci.192.168.31.49.xip.io时 ,会返回192.168.31.49的地址回来,
而这个地址恰好是我们Router的地址,这样子Router会根据route的配置负责负载到对应的POD上。自己试验下就知道怎么回事了。
dig http://gogs-ci.192.168.31.49.xip.io +short
只做功能性演示,先不考虑https加密安全访问,创建完后,访问gogs服务 http://gogs-ci.192.168.31.49.xip.io

这个项目,第一个注册用户即为管理员,比如我现在去页面注册一个叫developer的用户。
找个项目来实战吧
克隆远程项目,并设置
git clone https://github.com/xiaoping378/nodejs-ex.git && cd nodejs-ex
git remote add gogs http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git
通过web页面,在gogs上创建一个nodejs-ex仓库, 并如下push刚才克隆的项目
$ git push gogs master
Username for 'http://gogs-ci.192.168.31.49.xip.io': developer
Password for 'http://developer@gogs-ci.192.168.31.49.xip.io':
Counting objects: 431, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (210/210), done.
Writing objects: 100% (431/431), 145.16 KiB | 0 bytes/s, done.
Total 431 (delta 159), reused 431 (delta 159)
To http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git
* [new branch] master -> master
gogs的页面上会如实反馈信息
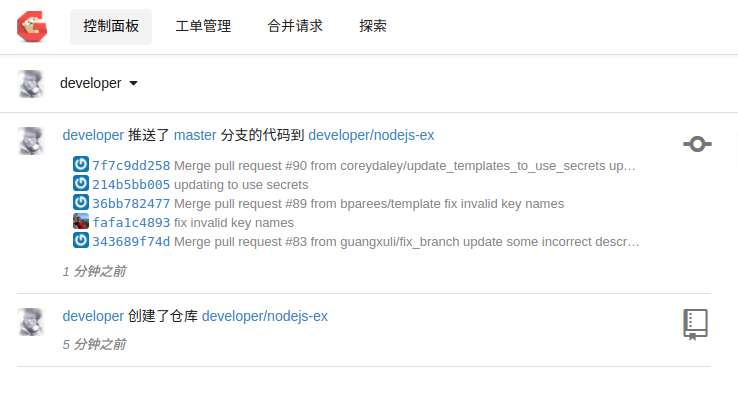
OK,现在本地项目就有了,接下来进入正题
在openshift部署此nodejs应用
#创建web namespace
oc new-project web
#先拉取依赖镜像
docker pull centos/mongodb-32-centos7
docker pull centos/nodejs-4-centos7
#部署此项目,并启用国内npm源和对应的git仓
oc new-app nodejs-mongo-persistent --name=nodejs-ex -p NPM_MIRROR=https://registry.npm.taobao.org -p SOURCE_REPOSITORY_URL=http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git
默认此模板会从指定的URL地址拉取代码,并根据预先的配置,采取Source编译策略,基于istag nodejs:4镜像编译出nodejs-mongo-persistent:latest镜像,编译出来的镜像又会自动触发部署。
最基本的DevOps能力
即push代码通过webhook触发自动编译,继而滚动部署
要实现这个目标前,需要先把webhook填写到gogs里。
在openshift界面上复制webhook地址
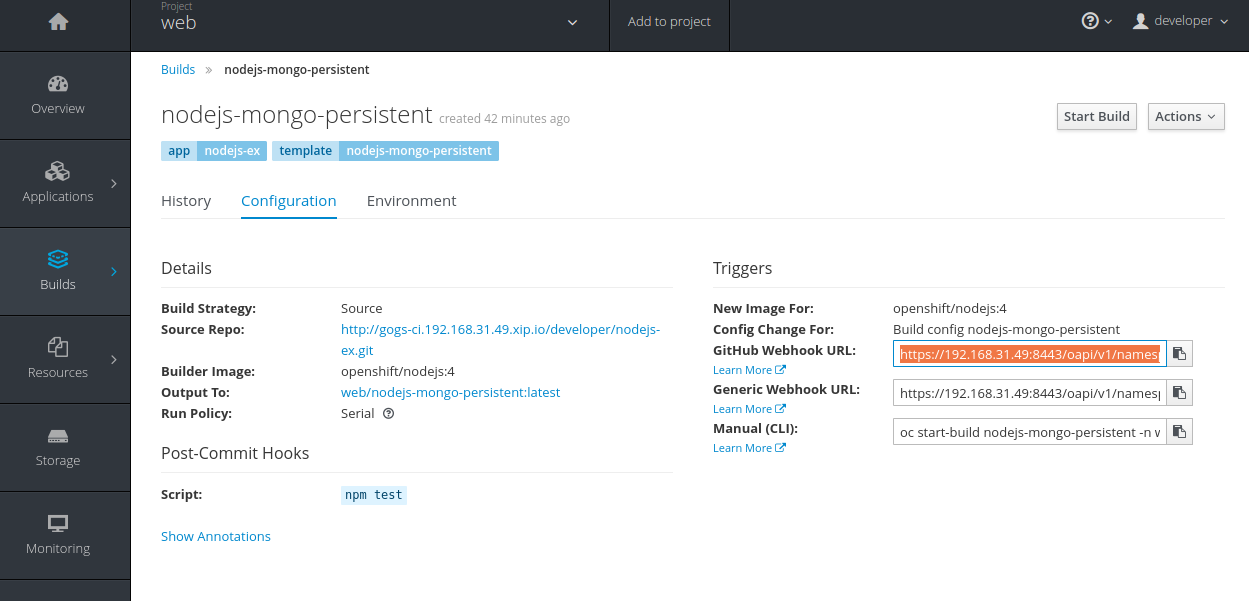
然后在gogs上填加一个webhook
这里我们随意修改些,然后推送代码,就会自动触发编译并滚动升级
➜ nodejs-ex git:(master) vim views/index.html
➜ nodejs-ex git:(master) ✗ git add .
➜ nodejs-ex git:(master) ✗ git commit -m "这又是个测试"
[master 082f05e] 这又是个测试
1 file changed, 1 insertion(+), 1 deletion(-)
➜ nodejs-ex git:(master) git push gogs master
Username for 'http://gogs-ci.192.168.31.49.xip.io': developer
Password for 'http://developer@gogs-ci.192.168.31.49.xip.io':
Counting objects: 4, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (4/4), 365 bytes | 0 bytes/s, done.
Total 4 (delta 2), reused 0 (delta 0)
To http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git
c3592e6..082f05e master -> master
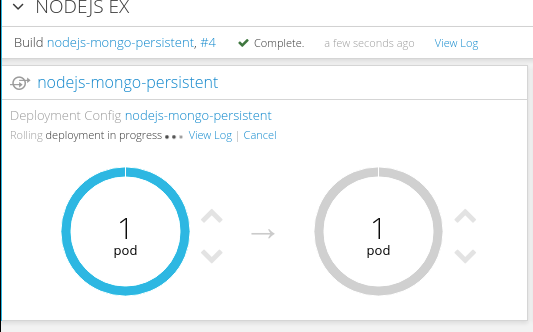
编译成功后,会产生新镜像,继而触发滚动升级的截图
现实中,如果项目没有很好的自动化测试的话,我们肯定不会这样操作的,除非想被开掉了。
其实可以简单的去掉webhook,采用手动触发build: 界面操作的话,去build界面点击Start Build,命令行的话如下
oc start-build nodejs-mongo-persistent
另外,如果发现新版本的应用有重大缺陷,想回滚以前的部署版本,也有对应的界面和命令
oc rollback nodejs-mongo-persistent --to-version=3
弹性伸缩
目前可以根据CPU使用率来进行弹性伸缩
有人问能不能基本mem进行弹性呢,其实这个是没什么意义的,一般应用都会自行缓存,内存基本只增不长, 所以cpu才能很好的实时反应业务的负载。
弹性伸缩前,要确保应用先行设置了cpu request,这点还没明白原因,为什么要这样,按理说,heapster一直会采集pod的资源使用情况的,HPA周期拿数据和设置的阈值对比就完了。
这里是部署界面的菜单栏,可以手动加上cpu request
添加 cpu request.
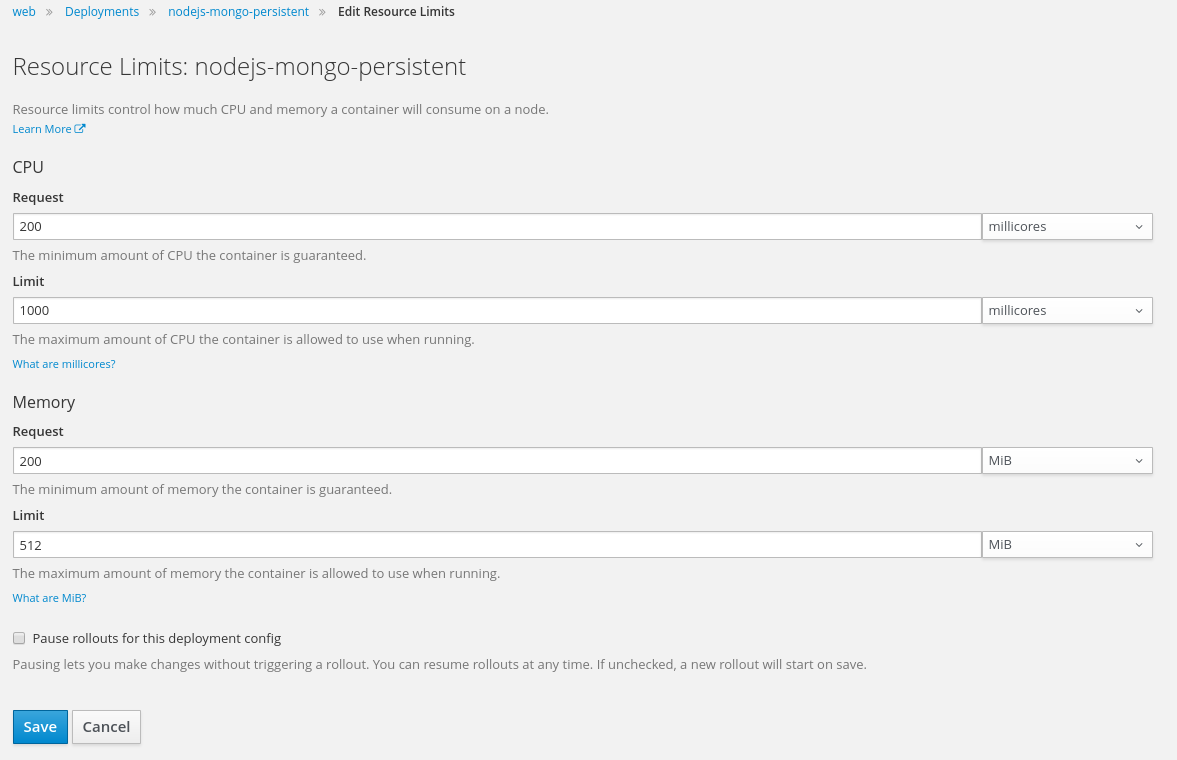
然后开启弹性伸缩特性,这里就不截图了,展示下命令行,我们设置成: 当cpu使用率达到80%时,就弹,最大可以弹出3个实例
oc autoscale dc/nodejs-mongo-persistent --max=3 --cpu-percent=80
OK,之后我们通过ab工具简单做个压力模拟,因为环境在我的笔记本上,所以只模拟发送100万个连接,并发100的量
ab -n 1000000 -c 100 http://nodejs-mongo-persistent-web.192.168.31.49.xip.io/
后台每1分钟采集一次cpu使用率,过不了一会儿,就会看到nodejs实例自动扩展了
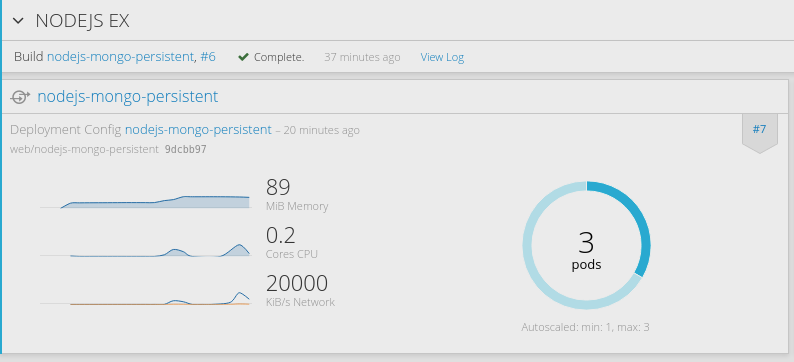
当业务量降下来时,会自动减少实例,是根据平均CPU使用率来操作的。
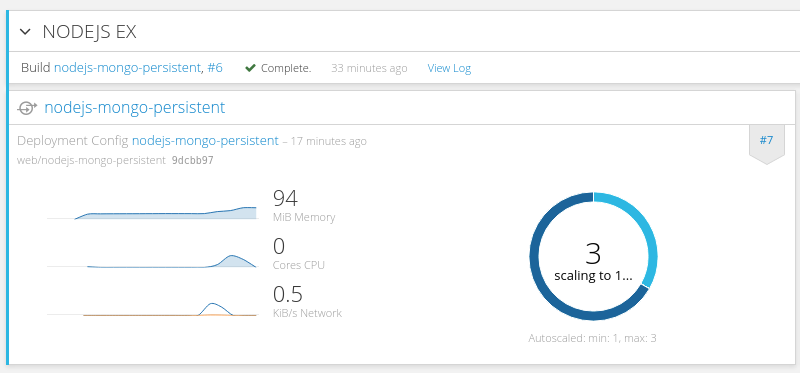
蓝绿部署
这个也是API级别的支持,不描述具体操作细节了,原理还是以前的,从负载均衡层面入手。 实现新旧版本同时存在。 并不是所有业务都适合蓝绿部署的,要看后台数据是否允许,新旧版本同时发生读写数据
在openshift里实现蓝绿部署的,就太简单了。具体就是在Route层面添加同一应用的多个版本的service,并设置分流权重 截图如下
界面设置,只是为了展示功能,我随便添加了个service
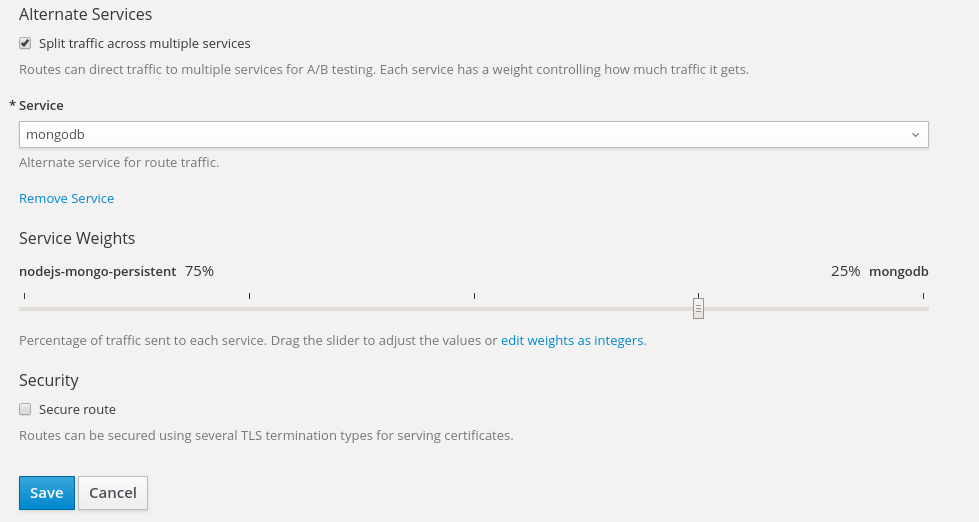
实际展示效果
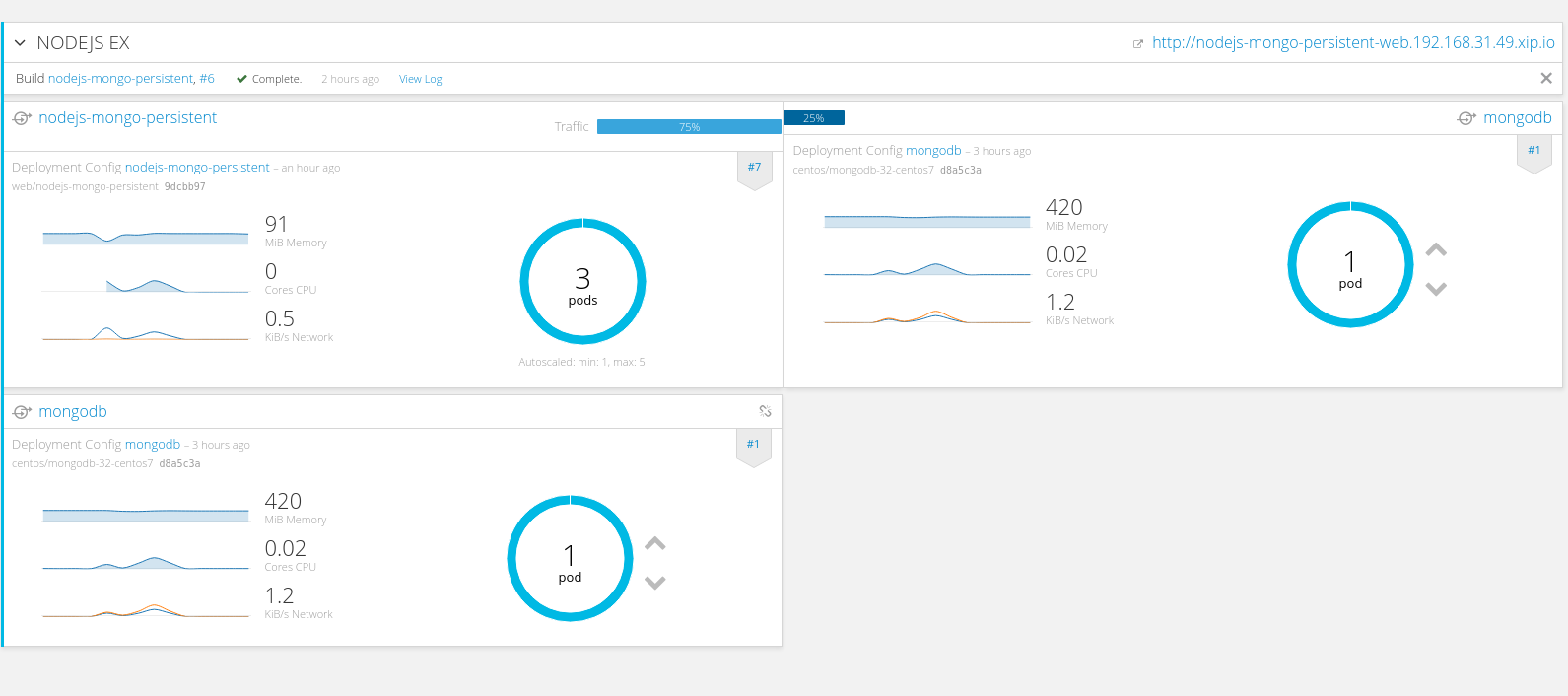
Openshift平台本身在API层面实现了DevOps,所以基于它很容易做到DevOps as an service, 上面的演示可能与现实世界不太一样,
比如真实情况是有,测试,预发布,线上环境的,下次再分享: openshift基于jenkins pipeline如果实现更真实场景的需求。
本文主要介绍基于openshift如何完成开发->测试->线上场景的变更,这是一个典型的应用生产流程,来看看openshift是如何利用容器优雅的完成整个过程的吧
下文基于上篇DevOps实战-0 的nodejs-ex项目来说, 假设到这里,你本地已经有了nodejs-ex项目
用这3个project来模拟开发,测试,线上环境
现实中一般各个场景的服务器都是物理隔离的,这里可以利用--node-selector,来指定项目可以跑在哪些节点上。
oc login -u sysetm:admin
#晚上在笔记本上写此blog,没合适的环境,单机模拟多台 -- start
oc label node 192.168.31.49 web-prod=true web-dev=true web-test=true
#晚上在笔记本上写此blog,没合适的环境,单机模拟多台 -- end
#1.创建web-dev项目
#2.授权developer为开发组项目管理员
#3.授权测试和运维人员可以从开发组拉取镜像
oc adm new-project web-dev --node-selector='web-dev=true'
oc policy add-role-to-user admin developer
oc policy add-role-to-group system:image-puller system:serviceaccounts:web-test -n web-dev
oc policy add-role-to-group system:image-puller system:serviceaccounts:web-prod -n web-dev
oc adm new-project web-test --node-selector='web-test=true'
oc policy add-role-to-user admin tester
oc adm new-project web-prod --node-selector='web-prod=true'
oc policy add-role-to-user admin ops
你可能会注意到,这里用的new-project 前面还加了adm, 其实oc adm等效于oadm, 一般管理集群相关的用这个命令,这里是因为需要读取节点的标签(label)信息。
指定项目要运行那些节点,则是利用了注解-annotations, 即在原有的project结构上设置了注解,这样openshift在相应的项目里创建任何pod时,都对会自动注入node-selector
另外需要注意的,默认项目的管理员(developer)是没有权限读取node标签信息的,以前写过权限管理相关blog,集群管理员可以授权node访问权限,即使如此developer还是不能改写项目级别的标签的,举个例子: developer在开发环境的pod上指定了--node-selector='web-dev=false', 最终这个pod的node-selector会是'web-dev=true, web-dev=flase', 导致最终不会被调度到任何节点上。
上面分别授权了3个用户,这里是不关心这些用户是否真实存在的,只是一个RABC的描述,因为是oc cluster up起来的环境,默认使用anypassword的身份认证,所以登录时,任意用户名和密码都是可以登录OK的。
通过oc describe policybinding -n web-dev 可以查看授权情况, 如果觉得默认的role不满足需求的话,也可以自定义role,另外通过oc policy remove-role-from-group/user <Role> <name>可以移除相关授权,
按照上篇DevOps实战-0里的方式
初始化我们的开发环境, 进入源码nodejs-ex目录
oc new-app -f openshift/template/nodejs-mongo-persistent.json --name=nodejs-ex \
-p NPM_MIRROR=https://registry.npm.taobao.org \
-p SOURCE_REPOSITORY_URL=http://gogs-ci.192.168.31.49.xip.io/developer/nodejs-ex.git \
-n web-dev
初始化测试环境,相较于上一步的模板json,只是注掉bc和更改了triggers的is,后面会详细介绍之间的差异
oc new-app -f openshift/template/nodejs-mongo-persistent-test.json --name=nodejs-ex-test -n web-test
以tester登录web console,会发现只有mongodb部署上了,而前端nodejs还在等待依赖的镜像 web-dev/nodejs-mongo-persistent:test。
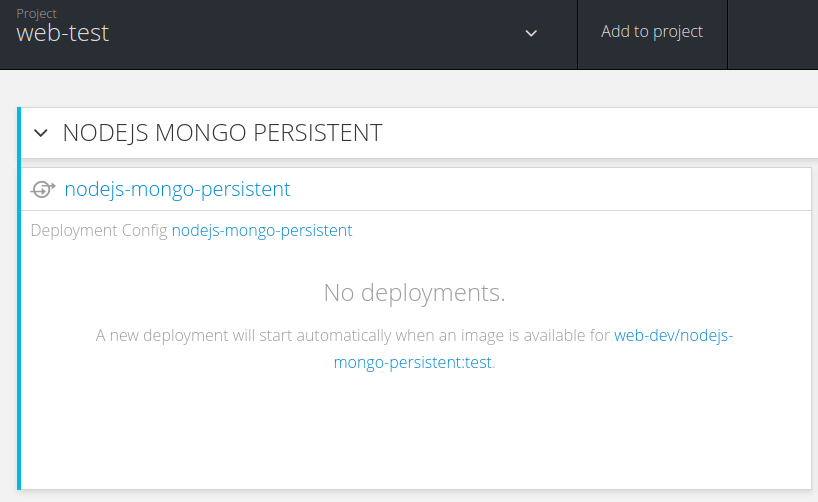
初始化生产环境, 这个生产的template.json有点儿简单,负载均衡和弹性伸缩都没有启用。
oc new-app -f openshift/template/nodejs-mongo-persistent-prod.json --name=nodejs-ex-prod -n web-prod
developer开发完特性或者修复完bug,push代码到镜像仓。
这里分享一个很方便的技巧,就是 oc rsync, 这个可以实时的同步本地目录到容器了,避免了频繁编译镜像和临时挂载目录到镜像里的hack了。
vim ...
git add .
git commit -m "fix bugs"
git push gogs master
如上,由于上篇中设置了webhook, developer提交代码会触发了自动编译并部署,确认部署后的环境是否修复了bug,如果单元测试通过,那就要通知测试团队(如今大部分公司,应该没有测试人员了吧,也可以直接变更到线上)
测试那边的环境里一直在等待这个镜像web-dev/nodejs-mongo-persistent:test, 而默认developer配置成默认编译出来的是web-dev/nodejs-mongo-persistent:latest
oc login -u developer
oc tag web-dev/nodejs-mongo-persistent:latest web-dev/nodejs-mongo-persistent:v1.1
oc tag web-dev/nodejs-mongo-persistent:v1.1 web-dev/nodejs-mongo-persistent:test
如上操作后,开发人员更新版本号,然后在web-dev环境里会打上一个test的镜像tag出来,操作完如下所示
➜ nodejs-ex git:(master) oc get is
NAME DOCKER REPO TAGS UPDATED
nodejs-mongo-persistent 172.30.1.1:5000/web-dev/nodejs-mongo-persistent test,v1.1,latest 49 seconds ago
➜ nodejs-ex git:(master)
➜ nodejs-ex git:(master) oc get istag
NAME DOCKER REF UPDATED IMAGENAME
nodejs-mongo-persistent:latest 172.30.1.1:5000/web-dev/nodejs-mongo-persistent@sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 3 minutes ago sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7
nodejs-mongo-persistent:v1.1 172.30.1.1:5000/web-dev/nodejs-mongo-persistent@sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 2 minutes ago sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7
nodejs-mongo-persistent:test 172.30.1.1:5000/web-dev/nodejs-mongo-persistent@sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7 55 seconds ago sha256:55615da49dd299064e7bba75923ac7996bf0d109e0322d4f84f9b41665b2e4c7
这样一来,测试环境里就会自动部署上刚才开发人员的环境了,再也不会有因为环境差异问题和测试吵吵了。
这一切都得益于openshift里新添加的imageStreams,它打通了编译和部署的环节,能自动通知对方,继而自动触发下一步动作。
测试通过后,通知Ops再重新tag成线上所需要的镜像tag,这样线上就会根据配置自动滚动升级了。
#假设一个叫ops的人负责上线,那首先ops得有具备web-dev项目里编辑is的能力
oc login -u developer
#不该给ops这么高权限的,应该自定义一个只能tag is的role,这里为了简单演示
oc policy add-role-to-user edit ops -n web-dev
如上操纵,ops就具备了tag web-dev项目的镜像的能力,也可以通过UI来查看和授权
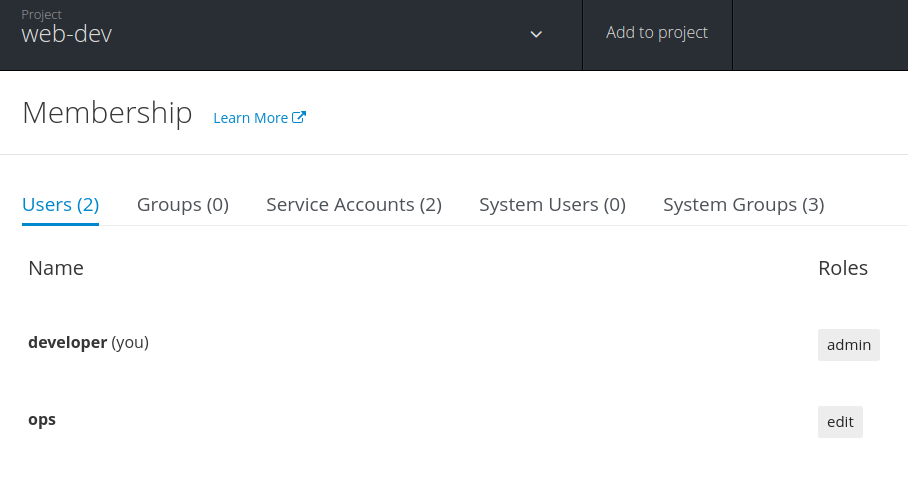
oc login -u ops
oc tag web-dev/nodejs-mongo-persistent:v1.1 web-dev/nodejs-mongo-persistent:prod
然后打上线上依赖的镜像tag即可,发布上线,这样就完成了开发->测试->发布一条线,很快捷的人工干预上线了
openshift 利用镜像tag的能力,来实现不同场景的同步,单纯基于docker也可以实现以上目标的,只是不够平台化,还是以前的脚本打天下,远不如openshift在API层面解决来的强大和灵活。
介绍openshift的源码编译和目录结构组织,为了方便代码调试和了解大型Golang项目的构建方式
无论是openshift还是Kubernetes等大型Golang项目都用到了Makefile, 所以有必要从此开始说起,这里只说项目里用到的makefile特性,想了解更多的可以参考跟我一起写Makefile
makefile 关系到了整个工程的编译规则。一个工程中的源文件不计数,其按类型、功能、 模块分别放在若干个目录中,makefile 定义了一系列的规则来指定,哪些文件需要先编译, 哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为 makefile 就像一个 Shell 脚本一样,其中也可以执行操作系统的命令。 makefile 带来的好 处就是——“自动化编译”,一旦写好,只需要一个 make 命令,整个工程完全自动编译, 极大的提高了软件开发的效率。
Makefile里的规则,就在做两件事,一个是指明依赖关系,另一个是生成目标的方法
Golang项目里用到的Makefile规则比较简单,基本就是定义一个目标的生成方法,下面的示例是Openshift项目里makefile中定义的第一个目标。
all build:
hack/build-go.sh $(WHAT) $(GOFLAGS)
.PHONY: all build
all build,是定义的目标,看到这个就知道可以在源码的根目录上执行make all build来编译了
第二行说明生成目标的方法,就是去hack目录下执行build-go.sh脚本,这里还支持传入一些参数
第三行 .PHONY,起到一个标识的作用,没什么实际意义,是用来告诉make命令,这里是个伪目标,也可以说成是默认目标,所以在openshift的根目录上直接执行make, 等效于make all build
还可以自己决定是否编译出镜像或者rpm包(make release, make build-rpms)
上边介绍了,直接敲make就可以自动编译出所有平台(linux, mac, windows)的二进制,编译前介绍两个hack方法,
在hack/build-go.sh的第二行加上set -x, 这样的话,shell脚本在运行时,里面的所有变量和执行路径会全部打印出来,一目了然,不用自己一行一行的加echo debug了
如下修改hack/build-cross.sh,不然会编译出多平台的二进制,花的时间略长啊。。。
# by default, build for these platforms
platforms=(
linux/amd64
# darwin/amd64
# windows/amd64
# linux/386
)
下面简易说下执行make后,都发生了什么,只会捡关键点说。
➜ origin git:(xxpDev) ✗ make
hack/build-go.sh
# 初始化一大堆变量,关键函数都在common.sh里实现的
source hack/common.sh hack/util.sh hack/lib目录下的所有脚本
# 还会改动GOPATH,然后会在$GOPATH/src/github.com/openshift下建个软连指向origin目录
export GOPATH=_output/local/go
# 最终组合成下面一条最原始的命令,来进行编译
go install \
-pkgdir /home/xxp/Github/src/github.com/openshift/origin/_output/local/pkgdir/linux/amd64 \
-tags ' ' \
-ldflags '-X github.com/openshift/origin/pkg/bootstrap/docker.defaultImageStreams=centos7 \
-X github.com/openshift/origin/pkg/cmd/util/variable.DefaultImagePrefix=openshift/origin \
-X github.com/openshift/origin/pkg/version.majorFromGit=3 \
-X github.com/openshift/origin/pkg/version.minorFromGit=6+ \
-X github.com/openshift/origin/pkg/version.versionFromGit=v3.6.0-alpha.0+83e3250-176-dirty \
-X github.com/openshift/origin/pkg/version.commitFromGit=83e3250 \
-X github.com/openshift/origin/pkg/version.buildDate=2017-04-06T05:34:29Z \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.gitCommit=43a9be4 \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.gitVersion=v1.5.2+43a9be4 \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.buildDate=2017-04-06T05:34:29Z \
-X github.com/openshift/origin/vendor/k8s.io/kubernetes/pkg/version.gitTreeState=clean' \
github.com/openshift/origin/cmd/openshift \
github.com/openshift/origin/cmd/oc \
github.com/openshift/origin/pkg/sdn/plugin/sdn-cni-plugin \
github.com/openshift/origin/vendor/github.com/containernetworking/cni/plugins/ipam/host-local \
github.com/openshift/origin/vendor/github.com/containernetworking/cni/plugins/main/loopback
可以看到openshift会编译出5个二进制来,其中3个和网络CNI接口有关,最后会放置到_output/local/bin/linux/amd64, 并作相关的软链接(oadm, kubelet)
所以以后分析程序的切入点就从cmd/openshift和 cmd/oc入手就行了
来看下编译成果
➜ origin git:(xxpDev) ✗ _output/local/bin/linux/amd64/oc version
oc v3.6.0-alpha.0+83e3250-176-dirty
kubernetes v1.5.2+43a9be4
features: Basic-Auth
看到输出v3.6.0-alpha.0+83e3250-176-dirty, 这就是上面编译时传进去的参数。
-X github.com/openshift/origin/pkg/version.majorFromGit=3,意思是说编译文件github.com/openshift/origin/pkg/version.go时,对常量majorFromGit赋值为3
-- 未完待续
haproxy在openshift里默认有两种用处,一个种负责master的高可用,一种是负责外部对内服务的访问(ingress controller)
平台部署情况:
lb负责master间的负载均衡,其实负载没那么大,更多得是用来避免单点故障
默认安装haproxy1.5.18版本,开启debug方法
# 默认systemd对haproxy做了封装,会以-Ds后台形式启动,debug信息是看不到的
systemctl stop harproxy
# vi /etc/haproxy/haproxy.cfg
log 127.0.0.1 local3 debug
# 手动启动haproxy
haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -d
不知道是不是哪里还需要设置,打印出来的日志,信息并不是不太多
另外浏览https://lbIP:9000, 可以看到统计信息
使用openshift-ansible部署后,harpxy的配置如下
[root@node4 ~]# cat /etc/haproxy/haproxy.cfg
# Global settings
#---------------------------------------------------------------------
global
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 20000
user haproxy
group haproxy
daemon
log /dev/log local0 info #定义debug级别
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults #默认配置,后面同KEY的设置会覆盖此处
mode http #工作在七层代理,客户端请求在转发至后端服务器之前将会被深度分板,所有不与RFC格式兼容的请求都会被拒绝,一些七层的过滤处理手段,可以使用。
log global #默认启用gloabl的日志设置
option httplog #默认日志类别为http日志格式
option dontlognull #不记录健康检查日志信息(端口扫描,空信息)
# option http-server-close
option forwardfor except 127.0.0.0/8 #如果上游服务器上的应用程序想记录客户端的真实IP地址,haproxy会把客户端的IP信息发送给上游服务器,在HTTP请求中添加”X-Forwarded-For”字段,但当是haproxy自身的健康检测机制去访问上游服务器时是不应该把这样的访问日志记录到日志中的,所以用except来排除127.0.0.0,即haproxy自身
option redispatch #代理的服务器挂掉后,强制定向到其他健康的服务器,避免cookie信息过时,仍可正常访问
retries 3 #3次连接失败就认为后端服务器不可用
timeout http-request 10s #默认客户端发送http请求的超时时间, 防DDOS攻击手段
timeout queue 1m #当后台服务器maxconn满了后,haproxy会把client发送来的请求放进一个队列中,一旦事件超过timeout queue,还没被处理,haproxy会自动返回503错误。
timeout connect 10s #haproxy与后端服务器连接超时时间,如果在同一个局域网可设置较小的时间
timeout client 300s #默认客户端与haproxy连接后,数据传输完毕,不再有数据传输,即非活动连接的超时时间
timeout server 300s #定义haproxy与后台服务器非活动连接的超时时间
timeout http-keep-alive 10s #默认新的http请求建立连接的超时时间,时间较短时可以尽快释放出资源,节约资源。和http-request配合使用
timeout check 10s #健康检测的时间的最大超时时间
maxconn 20000 #最大连接数
listen stats :9000
mode http
stats enable
stats uri /
frontend atomic-openshift-api
bind *:8443
default_backend atomic-openshift-api
mode tcp #在此模式下,客户端和服务器端之前将建立一个全双工的连接,不会对七层(http)报文做任何检查
option tcplog
backend atomic-openshift-api
balance source #是基于请求源IP的算法,此算法对请求的源IP时行hash运算,然后将结果除以后端服务器的权重总和,来判断转发至哪台后端服务器,这种方法可保证同一客户端IP的请求始终转发到固定定的后端服务器。
mode tcp
server master0 192.168.56.100:8443 check
server master1 192.168.56.101:8443 check
server master2 192.168.56.102:8443 check
官方文档介绍的非常详细,感兴趣的可以继续深入研究
router是由harpoxy来承担的, 可以理解成kubernetes里的ingress controller部分,默认跑在容器里。
使能 default项目下router,可以访问hostnetwork
oc adm policy add-scc-to-user hostnetwork system:serviceaccount:default:router
使能其可以查看 label
oc adm policy add-cluster-role-to-user \
cluster-reader \
system:serviceaccount:default:router
部署1个router, 选择具有标签router=true的节点
# 对节点设置标签
oc label 192.168.56.110 router=true
# 部署并指定serviceaccount
oc adm router router --replicas=1 --selector='router=true' --service-account=router
设置router自身的高可用,参考这里
默认使用keepalived实现多个router的高可用,访问router变成访问VIP地址,keepalived再根据权重和健康监测,利用VRRP通告外界后台到底那个router在服务。
# 添加另一个node作为冗余
oc label no 192.168.56.111 router=true
oc scale dc router --replicas=2
#绑定serviceaccount特权,因为keepalived要操作iptables
oc adm policy add-scc-to-user privileged system:serviceaccount:default:ipfailover
#创建keepalived并指定VIP
oc adm ipfailover ha-router \
--replicas=2 --watch-port=80 \
--selector="router=true" \
--virtual-ips="192.168.56.170" \
--iptables-chain="INPUT" \
--service-account=ipfailover --create
这样,刚才创建的router就自高可用了,通过192.168.56.170来访问,有一点值得注意,
--vrrp-id-offset=1,保证一个vip用一个独有的vrrp-id。路由分片的概念,就是集群内有多个router,通过label来负责不同的routes。
这样可以实现一个project独享一个router,或者某几个route独享一个router,再或者大型集群,更多样化的需求,用这个router sharding的概念也可以满足。
我现在还没有具体的场景,先不实践,后续有机会会跟进更新下。
刚接触docker时,第一个接触到的应该就是镜像了,docker之所以如此火热,个人认为一大部分原因就是这个镜像的提出,极大的促进了DevOps推广和软件复用的能力。
而openshift对镜像的管理非常强大,直到写这篇blog,我才真正意识到这点,甚至犹豫是不是要放到开发实战篇后再来写镜像管理。
简要说下openshift里使用镜像的情况:
Docker registry API的镜像仓,比如,Vmware的Harbor项目,Docker hub以及集成镜像仓( integrated registry)oc import-image <stream>来实时获取镜像tag信息并转换成镜像流,继而触发后续的编译或者部署。oc new-app也支持直接从第三方镜像仓或者本地镜像里启动一个应用文末有安装集成镜像仓的说明,先介绍image Streams 和 istag的概念和应用场景。
openshift基于docker的image概念又延伸出了Image Streams和Image Stream Tags概念
默认openshift项目下会有一些镜像流,是供自带模板里用的,所以想加速部署模板的话,可以在改这里,通过istag指向本地镜像仓。
oc get is -n openshift
oc get istag -n openshift
image,通俗讲就是对应用运行依赖(库,配置,运行环境)的一个打包。docker pull push, 就是操作的镜像。
为什么openshift还要抽象出is和istag呢,主要是为了打通集成编译和部署环节(bc和dc),原生API就支持了DevOps理念。后面会细讲bc和dc
is,开发人员可以理解成git的分支,每个分支都会编译很多临时版本出来,这个就是对应到is~=分支和istag~=版本号。 其实is和istag只是记录了一些映射关系,并不会存放实际镜像数据,比如is里记录了build后要output的镜像仓地址和所有tags,而istag里又记录了具体某个tag与image(可能是存于外部镜像仓,也能是某个is)的关系, 利用此实现了bc/dc和镜像的解耦。
这里通过部署jenkins服务,来初步了解下具体的含义,
oc new-project ci
# 先拉取必要镜像
docker pull openshift/jenkins-1-centos7
#通过模板部署,下面一条命令就可以创建一个临时的jenkins服务的
#oc new-app jenkins-ephemeral
#跑之前我们先来注意几点
先来查看默认的is
oc get template jenkins-ephemeral -n openshift -o json
...
"triggers": [
{
"imageChangeParams": {
"automatic": true,
"containerNames": [
"jenkins"
],
"from": {
"kind": "ImageStreamTag",
"name": "${JENKINS_IMAGE_STREAM_TAG}",
"namespace": "${NAMESPACE}"
},
"lastTriggeredImage": ""
},
"type": "ImageChange"
},
{
"type": "ConfigChange"
}
]
...
{
"name": "NAMESPACE",
"displayName": "Jenkins ImageStream Namespace",
"description": "The OpenShift Namespace where the Jenkins ImageStream resides.",
"value": "openshift"
},
{
"name": "JENKINS_IMAGE_STREAM_TAG",
"displayName": "Jenkins ImageStreamTag",
"description": "Name of the ImageStreamTag to be used for the Jenkins image.",
"value": "jenkins:latest"
}
...
可以看到默认模板里部署jenkins时,会从openshfit的namespace里拉取jenkins:latest的镜像, 去openshift项目里找找看,确实存在对应的is
➜ ~ oc get is -n openshift | grep jenkins
jenkins 170.16.131.234:5000/openshift/jenkins latest,1 2 days ago
➜ ~ oc get istag -n openshift | grep jenkins:latest
jenkins:latest openshift/jenkins-1-centos7@sha256:ab590529e20470e53c1d4b6b970de5d4fd357d864320735a75c1df0e2fffde07 2 days ago sha256:ab590529e20470e53c1d4b6b970de5d4fd357d864320735a75c1df0e2fffde07
上面的命令的输出,有两个点要阐述下,
170.16.131.234:5000/openshift/jenkins是个可有可无的地址,一般系统会填写集成镜像仓的地址openshift/jenkins-1-centos7@sha256:ab则是指明了对应tag的镜像来源,这样的话,默认执行oc new-app jenkins-ephemeral的话,会从docker.io那里拉取镜像 openshift/jenkins-1-centos7@sha256:ab590529e20470e53c1d4b6b970de5d4fd357d864320735a75c1df0e2fffde07
为了加速部署,我们把刚才pull下来的镜像,push到集成镜像仓里
#添加用户
#htpasswd /etc/origin/master/htpasswd xxp
docker tag openshift/jenkins-1-centos7 hub2.300.cn/openshift/jenkins
docker login -u developer -p `oc whoami -t` hub2.300.cn
docker push hub2.300.cn/openshift/jenkins
push完后再来看istag的变化,由以前的openshift/jenkins-1-centos变为了170.16.131.234:5000/openshift/jenkins
➜ ~ oc get istag -n openshift | grep jenkins:latest
jenkins:latest 170.16.131.234:5000/openshift/jenkins@sha256:dc0f434a492d11d6ae13711e77f87303a06a8fc0fb3a97ae327a4b88c33435b6 21 hours ago sha256:dc0f434a492d11d6ae13711e77f87303a06a8fc0fb3a97ae327a4b88c33435b6
这里是push到集成镜像仓后,系统会自动更新对应的is和istag, 为了加速部署,更改istag还可以通过import-image从私有镜像仓(harbor)里来完成
这样再来部署jenkins应用就快速多了
还有很多更细致的东西,比如如何周期同步第三方镜像仓等等,有需要的查看官文
可以通过openshift-ansible一次性安装OK,这里使用CLI安装,正好可以串一下openshift里的各种概念的使用场景。
oc project default
oc adm policy add-scc-to-user privileged system:serviceaccount:default:registry
oc label node 192.168.56.102 registry=true
#使用hostPath存储,要在node上放行权限,默认registry用的1001 userID, 不然后续挂载进去的volume,没有写权限
sudo chown 1001:root /home/registry
#注意要指定使用的镜像版本,默认是拉取最新的, 一定要指明``--volume``参数,不然deploy,不会挂载主机目录,官文这里遗漏了。
oc adm registry --images="openshift/origin-docker-registry:v1.4.1" --selector="registry=true" --mount-host="/home/registry" --service-account=registry --volume='/registry'```
中间莫名出现部署``error``的状态,重新部署了下``oc deploy docker-registry --retry``
### 加密镜像仓
- 先拿到serviceIP
```bash
[root@node0 master]# oc get svc docker-registry
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
docker-registry 170.16.132.252 <none> 5000/TCP 1h
oc adm ca create-server-cert \
--signer-cert=/etc/origin/master/ca.crt \
--signer-key=/etc/origin/master/ca.key \
--signer-serial=/etc/origin/master/ca.serial.txt \
--hostnames='hub.example.com,docker-registry.default.svc.cluster.local,170.16.132.252:5000' \
--cert=/etc/secrets/registry.crt \
--key=/etc/secrets/registry.key
创建secret, secret是专门来保存敏感信息的,比如密码,sshkey,token信息等等
更详细的介绍可以查看这里
oc secrets new registry-secret \
/etc/secrets/registry.crt \
/etc/secrets/registry.key
绑定secret到serviceaccount
oc secrets link registry registry-secret
oc secrets link default registry-secret
oc volume dc/docker-registry --add --type=secret \
--name=docker-registry --secret-name=registry-secret -m /etc/secrets
如果想移除的话,如下
oc volume dc/docker-registry --remove --name=docker-registry
oc set env dc/docker-registry \
REGISTRY_HTTP_TLS_CERTIFICATE=/etc/secrets/registry.crt \
REGISTRY_HTTP_TLS_KEY=/etc/secrets/registry.key
oc patch dc/docker-registry -p '{"spec": {"template": {"spec": {"containers":[{
"name":"registry",
"livenessProbe": {"httpGet": {"scheme":"HTTPS"}}
}]}}}}'
oc patch dc/docker-registry -p '{"spec": {"template": {"spec": {"containers":[{
"name":"registry",
"readinessProbe": {"httpGet": {"scheme":"HTTPS"}}
}]}}}}'
[root@node0 master]# oc logs dc/docker-registry | grep tls
time="2017-03-02T16:01:41.113619323Z" level=info msg="listening on :5000, tls" go.version=go1.7.4 instance.id=594aa09b-4540-4e38-a85a-851261cd1254
oc create route passthrough registry --service=docker-registry --hostname=hub2.300.cn
oc policy add-role-to-user admin developer -n default
oc login -u developer
docker login -u developer -p `oc whoami -t` hub2.300.cn
docker push hub2.300.cn/default/busybox
oc create -n default -f https://raw.githubusercontent.com/openshift/openshift-ansible/master/roles/openshift_hosted_templates/files/v1.4/origin/registry-console.yaml
oc create route passthrough --service registry-console \
--hostname hub3.300.cn \
-n default
oc new-app -n default --template=registry-console \
-p OPENSHIFT_OAUTH_PROVIDER_URL="https://192.168.31.100:8443" \
-p REGISTRY_HOST=$(oc get route docker-registry -n default --template='{{ .spec.host }}') \
-p COCKPIT_KUBE_URL=$(oc get route registry-console -n default --template='https://{{ .spec.host }}')
https://hub3.300.cn/registry,使用已有的账户登录,比如这里是默认的developer和developer。
主要参考的官方链接, 本文是基于openshift 3.5说的。
本指南提供了如何提高OpenShift容器平台的集群性能和生产环境下的最佳实践。 主要包括建立,扩展和调优OpenShift集群的推荐做法。
个人看法,其实性能这个东西是个权衡的过程,根据自身硬件条件和实际需求,选择适合自己的调优手段。
首先安装自然要选择官方的openshift-ansible项目, 默认是rpm安装方式,需要依赖网络,比如要去联网下载atomic-openshift-*, iptables, 和 docker包依赖,
如果有不能联网的节点,可以参考我之前写的离线安装openshift。
官方推荐使用ansible安装,这里说下针对ansible的优化,以提高安装效率,主要参考ansible官方blog,
如果参考上文离线安装的话,不建议跨外网连接rpm仓或者镜像仓,下面是推荐的ansible配置
# cat /etc/ansible/ansible.cfg
# config file for ansible -- http://ansible.com/
# ==============================================
[defaults]
forks = 20 # 20个并发是理想值,太高的话中间会有概率出错
host_key_checking = False
remote_user = root
roles_path = roles/
gathering = smart
fact_caching = jsonfile
fact_caching_connection = $HOME/ansible/facts
fact_caching_timeout = 600
log_path = $HOME/ansible.log
nocows = 1
callback_whitelist = profile_tasks
[privilege_escalation]
become = False
[ssh_connection]
ssh_args = -o ControlMaster=auto -o ControlPersist=600s
control_path = %(directory)s/%%h-%%r
pipelining = True # 多路复用,减少了控制机和目标间的连接次数,加速了性能。
timeout = 10
这里必须要提下,一定要安装前做好网络规划,不然后面改起来很麻烦,
默认是每个node上最多可跑110个pods,这个要看自身硬件条件,比如说我的环境全是高配物理机,我就改成了,每个节点可以跑1024个pods,这个主要改下面的地方。
openshift_node_kubelet_args={'pods-per-core': ['0'], 'max-pods': ['1024'], 'image-gc-high-threshold': ['90'], 'image-gc-low-threshold': ['80']}
osm_host_subnet_length=10
osm_cluster_network_cidr=12.1.0.0/12
关于网络的更多优化项,后面有单独介绍。
openhshift集群里,除了pod间的网络通信外,最大的开销就是master和etcd间的通信了,openshift的master集成了k8s里的api-server, master主要通过etcd来交互node状态,网络配置,secrets和卷挂载等等信息
主要优化点包括:
node节点的配置主要在**/etc/origin/node/node-config.yaml**里, 优化点视具体情况定,主要可以优化的点有:
配合自文件里还可以配置kubelet的启动参数,主要关注两点pods-per-core 和 max-pods,这两个决定了node节点的pod数,两者不一致时,取值小的。如果数值过大(严重超卖)会导致:
有一点要注意,k8s体系的平台,跑一个pod,实际会启动两个容器,一个pause先于业务容器启动,主要负责网络事项,所以跑10个pods,实际上会运行20个容器
etcd是一个分布式的key-value存储,所以有条件的话,存储读写性能的提升,上ssd最好了。
其次是网络的优化,比如和masters部署在一起,或者提供专网连接。
etcd实际使用中,最好的提升手段,是关注内存,这个官网有个换算公式的,多少pods推荐多大内存的使用
上面的所有节点,内核层面都需要做些优化,这里推荐使用tuned工具来做,这点属于常规运维优化了,具体可以参考这里来做, 不想明白原理的,可以如下 快速操作,redhat的人已经自动化了。
yum install tuned
systemctl start tune
systemctl enable tuned
tuned-adm profile throughput-performance)来做
主要是资源管理这块儿的注意点, 我以前有blog专门介绍过,主要值得一提的是,这里有个隐形的QoS级别
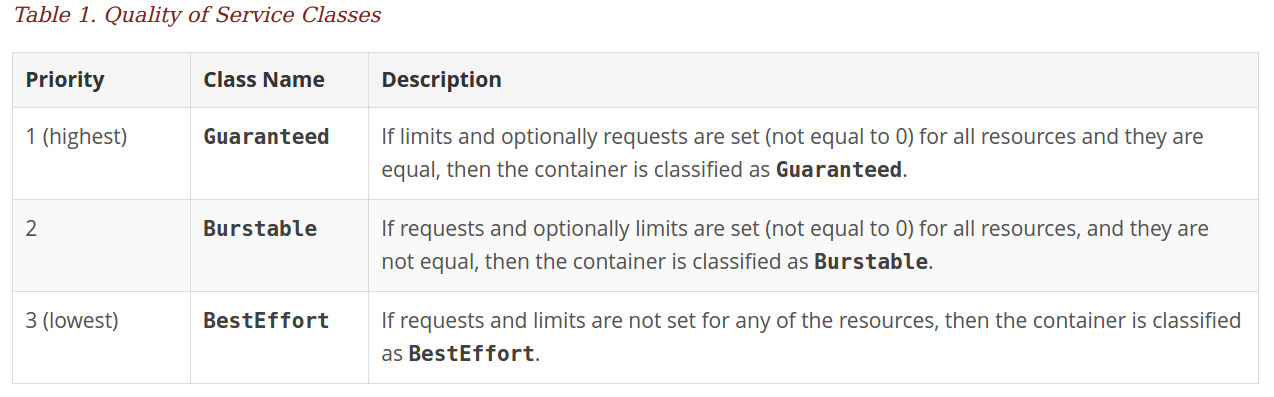
Guaranteed类型的pod是优先级最高的,是有保证的,只会在程序本身“异常”超出limits(一般的应用在pod层设置了limits,就不会超过该限制的,除非是java系的,其需要用环境变量来控制),才会被杀掉,其他类型的配额在集群资源紧张时会被kill掉的。
这块儿更多的细节也可以参考官文
这里需要注意的是,可以提前把需要的基础镜像先pull到node节点上,比如origin-pod镜像等,还有其他自定义的Gold 镜像,这样可以减少应用部署时间。
如果是采用镜像方式部署集群的话,也可以采取提前pull镜像的方式,当然有私有镜像仓的,可以忽略。
主要是现在默认的镜像拉取策略就是IfNotPresent,才能完成加速部署的效果
线上容器环境可能很干净, 如何调试一个线上正在运行的容器,估计困扰过很多开发人员,这个其实利用docker原生特性,可以很easy的做到
比如你自己build一个工具包镜像tools,里面装有tcpdump,perf,strace等等debug工具,如下可以很方便的动态的嵌入到运行的线上容器中。
docker run -t --pid=container:production \
--net=container:production \
--cap-add sys_admin \
--cap-add sys_ptrace \
tools
当然万能的日志调式,也是OK的。
这里的存储说的是docker的graph驱动( Device Mapper, Overlay, 和 Btrfs),首先overlay在启停容器速度方面要优于devicemapper,其还能带来更优良的页面缓存共享,但存在POSIX兼容性问题,比如不支持SELinux。
官方是推荐使用thin devicemapper的,但需要额外的独立块盘才能搞定。如果系统是7.2的话,使用overlay亦可,关闭selinux的代价就是牺牲部分容器安全。
openshift里的Router是基于haproxy做的,等价于k8s里的nginx ingress服务,提供集群内的service供外访问能力。
一般一个4 vCPU/16GB RAM的虚机,可以提供7000-32000 HTTP keep-alive连接请求,这取决于连接是否加密和页面大小,如果是物理机的话,性能会翻倍。
可通过Router sharding的技术来扩展性能。下图各种配置是统计性能(默认100个routes)
默认openshift提供了一个基于ovs的sdn方案,其中涉及到了vxlan, OpenFlow和iptables,当然这些相关的优化项社区已经有很成熟的优化点和方法了,比如增大MTU,UDP-offload,多路复用等等,
这里重点说下vxlan, 基于二层网络,vxlan从4096提升到了16百万多个,vxlan就是把原报文封装进UDP报文,以提供所有pods间通信的能力,自然这样会增加cpu解封包的开销,具体网络吞吐取决于cpu的性能,另外还会额外增加延时响应。
直白的说,现在云主机或物理机的cpu都可以打满千兆网卡,如果是万兆网卡,那vxlan网络的吞吐带宽会卡在CPU上,这是所有overlay网络的现状。
如果你的主机用用万兆或者40Gbps, 那就要考虑网络的性能优化了:
值得注意点是,及时使用了udp-offload的网卡,和非overlay网络比,延迟是不会减少的,只是减少了cpu开销,从而提高了带宽吞吐。
现在openshift-ansible项目默认的安装出来的配置是:
比如我要搞一个8192个节点的集群,每个节点允许510个pods运行:
[OSE3:vars]
osm_cluster_network_cidr=10.128.0.0/10
都知道k8s里的弹性伸缩,依赖于Heapster, 而openshift内置的监控系统又是用的自家的Haw系列,导致监控镜像相当的大
在opneshift里有两点要提的是METRICS_RESOLUTION和METRICS_DURATION变量,前者是默认是30s,指的是监控时间间隔,后者默认是7天,指的是监控数据保留时长(过期就会删掉)。
默认的监控体系(Cassandra/Hawkular/Heapster)可以监控25000个pods。
其实openshift基于k8s提供了一站式解决方案, 如果公司不具备k8s二次开发能力,openshift足矣。
介绍利用openshift-ansible项目安装后的生产环境里的网络情况。
待整理。。。
未完搞 ...
未完搞 ...
主要记录介绍对kubersphere的架构认知和储备二次开发所必备的知识。
本系列文章中会把kubesphere简说成KCP(Qingcloud kubernetes controller-manage platform)
我本地4c/8G的小本儿,跑了两个集群,组建了多集群环境,还行,能玩动...
kind安装
镜像准备
视网络情况,可以把依赖镜像kindest/node提起pull到本地
docker的data-root目录
尽量不要放到/var目录下,kind起的集群容器会占用比较大的空间
执行完如下命令后,docker ps可以看到本地启动了两个容器,一个容器对应一个集群。
kind create cluster --image kindest/node:v1.19.16 --name host
kind create cluster --image kindest/node:v1.19.16 --name member
kubectl config use-context [kind-host | kind-member],可以切换kubecl执行的上下文
分别在两个集群各自安装ks组件
# 集群1安装
kubectl config use-context kind-host
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/cluster-configuration.yaml
# 集群2安装
kubectl config use-context kind-member
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/cluster-configuration.yaml
可以在上面的初始化阶段直接改好主和成员集群的关系,这里参考官文即可
host集群的UI地址,可以通过host容器IP:30880来访问,主集群的容器ip,可以如下获取:
docker inspect --format '{{ .NetworkSettings.Networks.kind.IPAddress }}' host-control-plane
实操添加集群时,需要member集群的kubeconfig,可以用如下命令获取到
kind get kubeconfig --name member
记得把kubeconfig中的server地址中改成member容器ip:6443,这样host集群才能访问到member集群
验证功能、测试开发,挺方便的,可以视本地资源紧张情况停掉监控的ns。
现在kind启动的集群默认使用了containerd的runtime,若想进一步调试查看集群内的情况,可以内部集成的crictl代替熟悉的docker工具。
遇到这样一个场景,在同一套环境中需要存在多个host控制面集群...bulabula... 因此想探索下kubesphere的异地多活混合容器云管理方案
一个兼容原生的k8s集群,可通过ks-installer来初始化完成安装,成为一个QKE集群。QKE集群分为多种角色,默认是none角色(standalone模式),开启多集群功能时,可以设置为host或者member角色。
上段提到QKE有3种角色,可通过修改cc配置文件的clusterRole来使能, ks-installer监听到配置变化的事件,会初始化对应集群角色的功能。
kubectl edit cc ks-installer -n kubesphere-system
角色不要改来改去,会出现莫名问题,主要是背后ansible维护的逻辑有疏漏,没闭环
host角色的主集群会被创建25种联邦资源类型Kind,如下命令可查看,还会额外安装kubefed stack组件。
➜ kubectl get FederatedTypeConfig -A
此外api-server被重启后,会根据配置内容的变化,做两件事,注册多集群相关的路由和缓存同步部分联邦资源。
clusters/{cluster}路径的agent路由和转发的功能,要访问业务集群的信息,这样可以直接转发过去。当开启多集群后,如果某个member出现异常导致不可通信,那host的api-server此时遇到故障要重启,会卡在cacheSync这一步,导致无法启动,进而整个平台无法访问。
controller-manager被重启后,同样会根据配置的变化,把部分资源类型自动转化成联邦资源的逻辑,也就是说,在host集群创建的这部分资源会自动同步到所有成员集群,实际的多集群同步靠kubefed-controller-manager来执行。以下资源会被自动创建联邦资源下发:
此外还会启动cluster、group和一些globalRole*相关资源的控制器逻辑,同上也会通过kubefed自动下发到所有集群,clusters.cluster.kubesphere.io资源除外。
如果以上资源包含了
kubefed.io/managed: false标签,kubefed就不会再做下发同步,而host集群下发完以上资源后,都会自动加上该标签,防止进入死循环
修改为member集群时,需要cc中的jwtSecret与host集群的保持一致(若该值为空的话,ks-installer默认会随机生成),提取host集群的该值时,需要去cm里找,如下:
kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret
jwtSecret要保持一致,主要是为了在host集群签发的用户token,在用户访问业务集群时token校验能通过。
本文只关注直接连接这种情况,当填好成员集群的kubeconfig信息,点击添加集群后,会做如下校验:
jwtSecret是否和主集群的一致写稿时,此处有个问题,需要修复,如果kubeconfig使用了
insecure-skip-tls-verify: true会导致该集群添加失败,经定位主要是kubefed 空指针panic了,后续有时间我会去fix一下,已提issue。
校验完必要信息后,就执行实质动作joinFederation加入联邦,kubesphere多集群纳管,实质上是先组成联邦集群:
kubefedclusters.core.kubefed.io,由kubefed stack驱动联邦的建立上述一顿操作,等效于
kubefedctl join member-cluster --cluster-context member-cluster --host-cluster-context host-cluster
异地多活的方案主要是多个主集群能同时存在,且保证数据双向同步,经过上面的原理分析,可知多个主集群是可以同时存在的,也就是一个成员集群可以和多个主集群组成联邦。整体方案示意图设计如下:
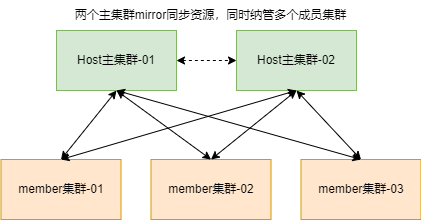
以下操作假设本地已具备三个QKE集群,如果不具备的可按照此处快速搭建
host、host2、member3个集群
大致实现逻辑的前提介绍:
jwtSecret得保持一致添加纳管同一个member集群etcdctl make-mirror实现双向同步实操双活前,先验证下可行性
实验1:
在两边创建一个同名用户,用户所有信息一致,可以添加成功,然后再修改一边的用户信息,使两边不一致
可以看到member集群的用户xxp,一直会被两边不断的更新...
root@member-control-plane:/# kubectl get user xxp -w
NAME EMAIL STATUS
xxp xxp@163.com Active
xxp xxp-2@163.com Active
xxp xxp@163.com Active
xxp xxp-2@163.com Active
... 周而复始 ...
这个实验,即使在创建用户时,页面表单上两边信息填的都一样,也会出现互相刷新覆盖的情况,因为yaml里的uid和time信息不一致
实验2:
在两边添加一个同名用户,但两边用户信息(用户角色)不一致,可以创建成功,但后创建者的kube-federa会同步失败, 到这里还能接受,毕竟有冲突直接就同步失败了
但member集群上该用户的关联角色会出现上文的情况,被两边的主集群持续反复地修改...
实验3:
在一侧的主集群上尝试修复冲突资源,即删除有冲突的用户资源,可以删除成功,但对应的联邦资源会出现删失败的情况
➜ ~ kubectl get users.iam.kubesphere.io
NAME EMAIL STATUS
admin admin@kubesphere.io Active
xxp3 xxp3@163.com Active
➜ ~
➜ ~ kubectl get federatedusers.types.kubefed.io
NAME AGE
admin 5h33m
xxp 65m #这里是个删不掉的资源,fed controller会重复做失败尝试
xxp3 61m
这样就会出现,两个主集群:一个要删,一个要同步,member集群上:持续上演“一会儿消失,一会儿又出现了”的奇观。
两个主集群可以同时工作,一旦出现同名冲突资源,处理起来会非常麻烦,尤其是背后的Dependent附属资源出现冲突时,往往问题点隐藏的更深,修复起来也棘手...
后来调研也发现:目前的社区方案make-mirror只支持单向同步,适合用来做灾备方案。
所以容器云平台的双活,除非具备跨AZ的etcd集群,否则需要二次开发改造类make-mirror方案来支持了。我最开始要考虑的问题答案也就显而易见了:如果要多个host集群共存,必须考虑通过行政管理手段,来尽量避免同名资源冲突。
Remote Development插件使用kt-connect,打通网络,本地可直接访问Kubernetes集群内网
sudo ktctl connect --context kind-host --portForwardTimeout 300
ktctl采用本地kubectl工具的集群配置,默认为~/.kube/config文件中配置的集群。--context指定要连接的具体集群kind集群,需要修改kubeconfig中server的127地址为容器IP:6443ERR Exit: pod kt-rectifier-tcxjk failed to start,可适当增加等待时间portForwardTimeout另外注意的是,kt-connect需要root权限,上条命令会默认读取
/root/.kube/config文件,自行copy或者另通过-c指定文件
不表.
首先编辑vscode的调试配置文件, 我是如下配置的:
➜ kubesphere git:(master) cat .vscode/launch.json
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "ks-apiserver",
"type": "go",
"request": "launch",
"mode": "auto",
"program": "${workspaceFolder}/cmd/ks-apiserver/apiserver.go"
},
{
"name": "controller-manager",
"type": "go",
"request": "launch",
"mode": "auto",
"program": "${workspaceFolder}/cmd/controller-manager/controller-manager.go"
}
]
}
按F5,启动调试,左上角选择要调试的组件,我这里以controller-manager举例(需要hack的注意点比较多)。
过会儿会发现出现错误,错误提示很明显,因缺少配置文件,导致无法启动,通过查看deployment yaml, 发现后面还会缺失Admission Webhooks的证书,可如下统一提取到本地:
# 提取启动的配置文件(调试apiserver的时候也需要这一步,但要把文件放到对应cmd/ks-apiserver目录下)
kubectl -n kubesphere-system get cm kubesphere-config -ojsonpath='{.data.kubesphere\.yaml}' > cmd/controller-manager/kubesphere.yaml
# 提取webhook用到的证书
mkdir -p /tmp/k8s-webhook-server/serving-certs/
export controller_pod=`kubectl -n kubesphere-system get pods -l app=ks-controller-manager -o jsonpath='{.items[0].metadata.name}'`
kubectl -n kubesphere-system exec -it ${controller_pod} -- cat /tmp/k8s-webhook-server/serving-certs/ca.crt > /tmp/k8s-webhook-server/serving-certs/ca.crt
kubectl -n kubesphere-system exec -it ${controller_pod} -- cat /tmp/k8s-webhook-server/serving-certs/tls.crt > /tmp/k8s-webhook-server/serving-certs/tls.crt
kubectl -n kubesphere-system exec -it ${controller_pod} -- cat /tmp/k8s-webhook-server/serving-certs/tls.key > /tmp/k8s-webhook-server/serving-certs/tls.key
继续启动,发现还会有缺文件的错误,应该是编译镜像时,内置了些文件,通过查看build/ks-controller-manager/Dockerfile,发现后面会缺的东西还是比较多的,推荐直接从运行中的pod直接copy到本地:
sudo mkdir /var/helm-charts/
sudo chmod -R a+rw /var/helm-charts
kubectl -n kubesphere-system cp ${controller_pod}:/var/helm-charts /var/helm-charts/
继续启动,成功 !
利用ktctl替换集群中的ks-controller-manager的服务为本地服务。
sudo ktctl exchange ks-controller-manager --namespace kubesphere-system --mode scale --recoverWaitTime 300 --expose 8443:8443
如果本地集群只有一个节点,上述命令会一直pending,可以通过如下命令替代
sudo ktctl exchange ks-controller-manager --namespace kubesphere-system --expose 8443:8443 kubectl -n kubesphere-system scale deployment ks-controller-manager --replicas=0结束调试,记得还原刚才缩容
replicas的设置。
后续就是vscode的正常断点调试或者本地开发验证了,有时间在整理贴图...
此前一直用Virtualbox操作虚机的东西,对于个人搭建环境还是显的有些笨重,不能实现Iac的目标,故尝试了Vagrant和Libvirt,综合考虑我选择libvirt继续深入下去,也是希望以后有机会可以深入搞下openstack的nova组件。
sudo apt install bridge-utils qemu-kvm virtinst -y
安装完输入kvm-ok查看是否安装OK,另外还需要重启以使kvm和libvirt daemon启动。
未完。。。
很早就听说vagrant的大名,是个创建和管理虚机环境的工具,但一直没有机会实践下,近日我的VirtuablBox让我搞砸了,决定试用下,便于快速搭建各种环境。
图省事儿的话,直接sudo apt install vagrant就可以安装,不过版本有点儿低,是1.8.1。
通过官方下载地址, 可直接下载最新的安装包。我这里安装的是1.9.4
➜ ~ vagrant -v
Vagrant 1.9.4
一个打包好的操作系统在Vagrant中称为Box,即Box是一个打包好的操作系统环境,网上有很多打包好的环境,官方也有下载各种Boxes的地址
一般使用流程如下:
额外还有些常用的命令
目前vagrant 1.9.4支持适配VirtualBox, VMware,Hyper-V, 和 Docker,本文使用的是VirtualBox。
需要你本机已经安装virtuablbox环境
一般只要如下初始化,就会有个最新的centos-7虚机环境
➜ vagrant init centos/7
A `Vagrantfile` has been placed in this directory. You are now
ready to `vagrant up` your first virtual environment! Please read
the comments in the Vagrantfile as well as documentation on
`vagrantup.com` for more information on using Vagrant.
➜ ls
Vagrantfile
➜ vagrant up --provider virtualbox
Bringing machine 'default' up with 'virtualbox' provider...
==> default: Box 'centos/7' could not be found. Attempting to find and install...
default: Box Provider: virtualbox
default: Box Version: >= 0
==> default: Loading metadata for box 'centos/7'
default: URL: https://atlas.hashicorp.com/centos/7
==> default: Adding box 'centos/7' (v1704.01) for provider: virtualbox
default: Downloading: https://atlas.hashicorp.com/centos/boxes/7/versions/1704.01/providers/virtualbox.box
default: Progress: 2% (Rate: 94086/s, Estimated time remaining: 1:52:14)
但如上需要依赖外网, 国内环境一般会下载失败,我这里介绍一种通过本地iso创建Box的方法,然后通过本地Box启动虚机环境。
这个iso转box的方法需要Packer工具,此工具同样和vagrant都是HashiCorp公司出品的,目前国外很火的工具,
支持创建各式各样的镜像,包括各种国内外主流的公有云, openstack的镜像,甚至docker镜像都是可以OK的。
介绍现在的Consul前,有必要先介绍下Service Mesh的概念,
Service Mesh
Service Mesh是一种面向服务间安全通信的基础设施层,俗称代理服务的东西向流量。 典型的实现包含控制面板和数据面。
传统 vs 微服务优势 :
Consul
Consul是Service mesh中的控制面的实现,主要有一下几大特色:
下图为经典的多中心consul集群配置。
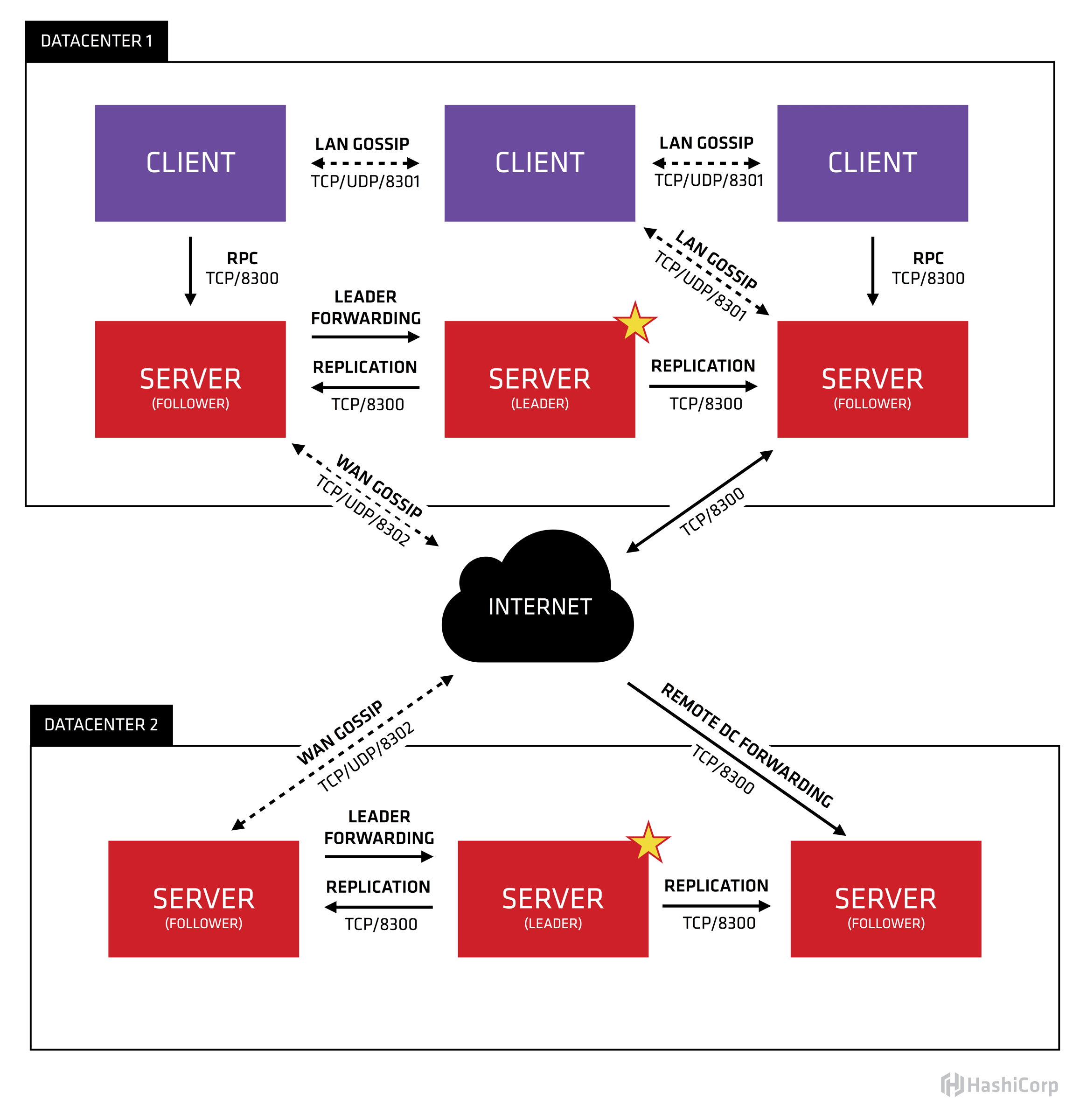
目前分布式系统的高可靠实现,均受限于CAP(一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance))理论,根据不同业务场景的会采取三者之间的平衡取舍。本文的Consul是采用Raft算法来实现的,采用此算法的还有EverDB、RocketDB、Etcd、Kafka3等系统。
Raft算法状态机:
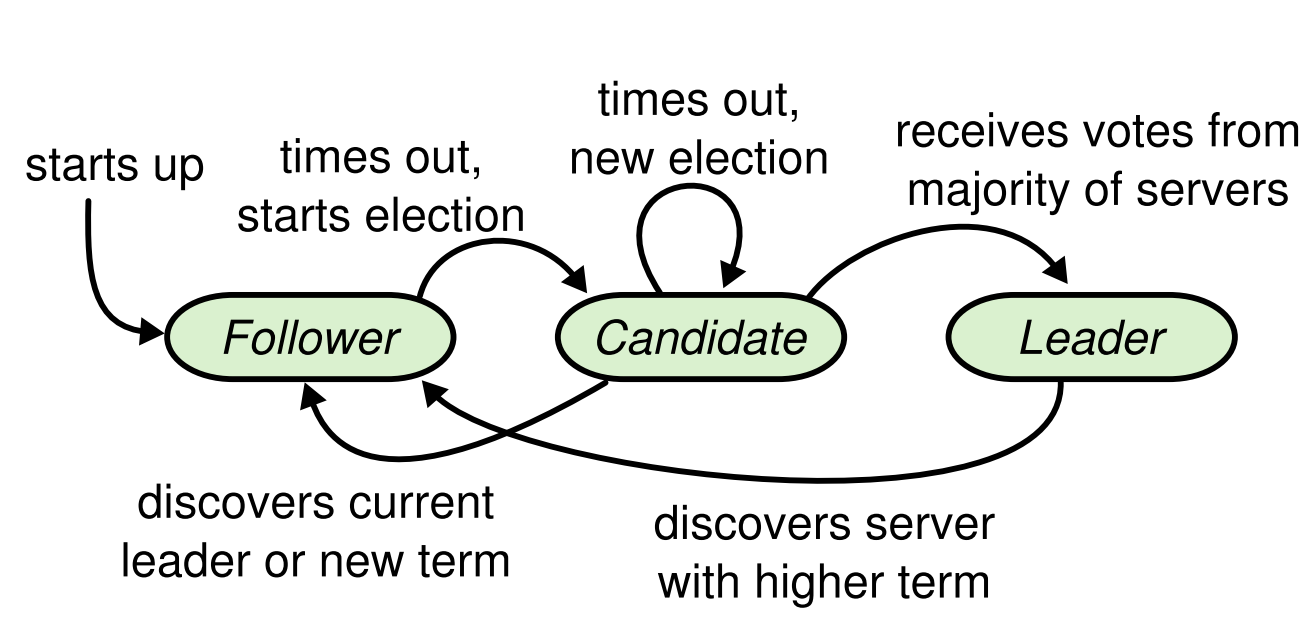
主要有三种状态Follower、Candidate和Leader,其中值得关注有以下几个方面:
Follower,经过随机时间(Election Time)后,进入Candidate状态,发起投票流程。Leader详情可查看动画展示。
从Raft算法原理可以得出,Leader选举和日志同步都只需要大多数的节点正常互联即可,所以少量节点故障或网络异常不会影响系统的可用性。
即使Leader故障,在选举超时后,剩余节点会自发选举新Leader,无需人工干预,RTO时间极小。如果网络发生脑裂,待网络恢复后,也会保证数据最终一致性。
Gossip通信
Gossip是Consul节点间状态同步的,下图为形象表示:
可以理解为一传十、十传百,随机选择几个节点发出消息,收到信息的节点在向其他节点传播,这种方式在数据量大、环境复杂的情况下比一传百更具备可扩展性和可靠性。Consul默认有两个Gossip池,LAN池和WAN池。
LAN池 :Consul中的每个数据中心有一个LAN池,它包含了这个数据中心的所有成员,包括clients和servers。LAN池用于以下几个目的:
WAN池: WAN池是全局唯一的,因为所有的server都应该加入到WAN池中,无论它位于哪个数据中心。由WAN池提供的成员关系信息允许server做一些跨数据中心的请求。一体化的失败检测机制允许Consul优雅地去处理:整个数据中心失去连接, 或者仅仅是别的数据中心的某一台失去了连接。
数据写入必须走Leader,经过两阶段提交(propose、prewrite(append、replicate)、commited、apply)过程,详情可以参考这里,读取数据Consul有三个级别可以配置。
TODO.
client说明:
configmap中的字段: client的配置datacenter、encrypt
-encrypt:和sever段保持一致,可用consul keygen生成,只在启动后加载一次,之后便不需要了,用于加密consul的gossip协议通信。datacenter: 和要接入的server端保持一致,代表consul集群名称。acl.tokens.agent: acl申请的token,代表了该client可以操作服务、配置的权限deployment的字段:
CONSUL_RETRY_JOIN_ADDR里的值,会填充到 join和 --retry-join参数中,代表要接入的consul集群,前者加入一次不成功会失败,后者会重复尝试直到成功。CONSUL_NODE_NAME,会填充到-node参数,默认是hostname,要求全局唯一,此处代表要接入注册中心的系统的名字。AGENT_TOKEN:acl里申请的tokenserver说明: