监控之我见
概述
监控是整个运维乃至整个产品生命周期中非常重要的一环,可以事前及时预警发现故障,事后提供详实的数据用于追查定位问题。
目前业界存在各种开源监控产品,如Zabbix,ELK体系,Prometheus等等,各有自身的适用场景,所以选择基于一款开源的的监控系统会是事半功倍的事情。
监控目标
站在公司各业务角度考虑,整理如下四点目标:

- 对系统不间断实时监控: 实际上是对系统不间断的实时监控(这就是监控)
- 实时反馈系统当前状态: 我们监控某个硬件、某个系统,某个进程服务,都是需要能实时看到当前系统的状态,是正常、异常、或者故障
- 保证服务可靠性安全性:我们监控的目的就是要保证系统、服务、业务正常运行
- 保证业务持续稳定运行:如果我们的监控做得很完善,即使出现故障,能第一时间接收到故障报警,在第一时间处理解决,从而保证业务持续性的稳定运行;
监控方法
既然我们了解到了监控的重要性、以及监控的目的,那么下面我们需要了解下监控有哪些方法。

- 了解监控对象:我们要监控的对象你是否了解呢?比如 CPU 到底是如何工作的?
- 性能基准指标:我们要监控这个东西的什么属性?比如 CPU 的使用率、负载、用户态、内核态、上下文切换。
- 报警阈值定义:怎么样才算是故障,要报警呢?比如 CPU 的负载到底多少算高,用户态、内核态分别跑多少算高?
- 故障处理流程:收到了故障报警,我们怎么处理呢?有什么更高效的处理流程吗?
监控核心
我们了解了监控的方法、监控对象、性能指标、报警阈值定义、以及故障处理流程几步骤,当然我们更需要知道监控的核心是什么?
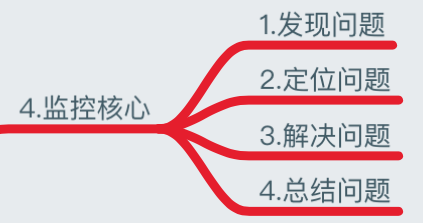
- 发现问题:当系统发生故障报警,我们会收到故障报警的信息 ;
- 定位问题:故障邮件一般都会写某某主机故障、具体故障的内容,我们需要对报警内容进行分析,比如一台服务器连不上:我们就需要考虑是网络问题、还是负载太高导致长时间无法连接,又或者某开发触发了防火墙禁止的相关策略等等,我们就需要去分析故障具体原因;
- 解决问题:当然我们了解到故障的原因后,就需要通过故障解决的优先级去解决该故障;
- 总结问题:当我们解决完重大故障后,需要对故障原因以及防范进行总结归纳,避免以后重复出现;
监控流程
基于 Zabbix 来构建整个监控体系生态圈
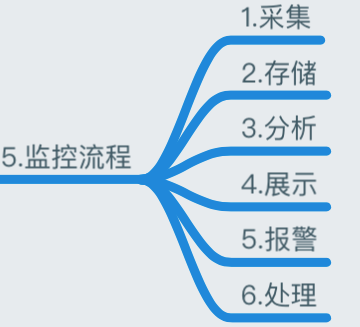
- 数据采集:Zabbix 通过 SNMP、Agent、ICMP、SSH、IPMI 等对系统进行数据采集;
- 数据存储:Zabbix 存储在 MySQL 上,也可以存储在其他数据库服务;
- 数据分析:当我们事后需要复盘分析故障时,Zabbix 能给我们提供图形以及时间等相关信息,方面我们确定故障所在;
- 数据展示:web 界面展示、(移动 APP、java_php 开发一个 web 界面也可以) ;
- 监控报警:电话报警、邮件报警、微信报警、短信报警、报警升级机制等(无论什么报警都可以);
- 报警处理:当接收到报警,我们需要根据故障的级别进行处理,比如:重要紧急、重要不紧急等。根据故障的级别,配合相关的人员进行快速处理;
监控指标
具体要监控些什么东西?那么我在这里进行了分类整理:
硬件监控
早期我们通过机房巡检的方式,查看硬件设备灯光闪烁情况判断是否故障,这样非常浪费人力,并且是重复性无技术含量的工作,大家懂得。

当然我们现在可以通过IPMI对硬件详细情况进行监控,并对 CPU、内存、磁盘、温度、风扇、电压等设置报警阈值(自行对监控报警内容编写合理的报警范围)
系统监控
基本全是 Linux 服务器,那么我们肯定要监控系统资源的使用情况,系统监控是监控体系的基础。
**监控主要对象: **

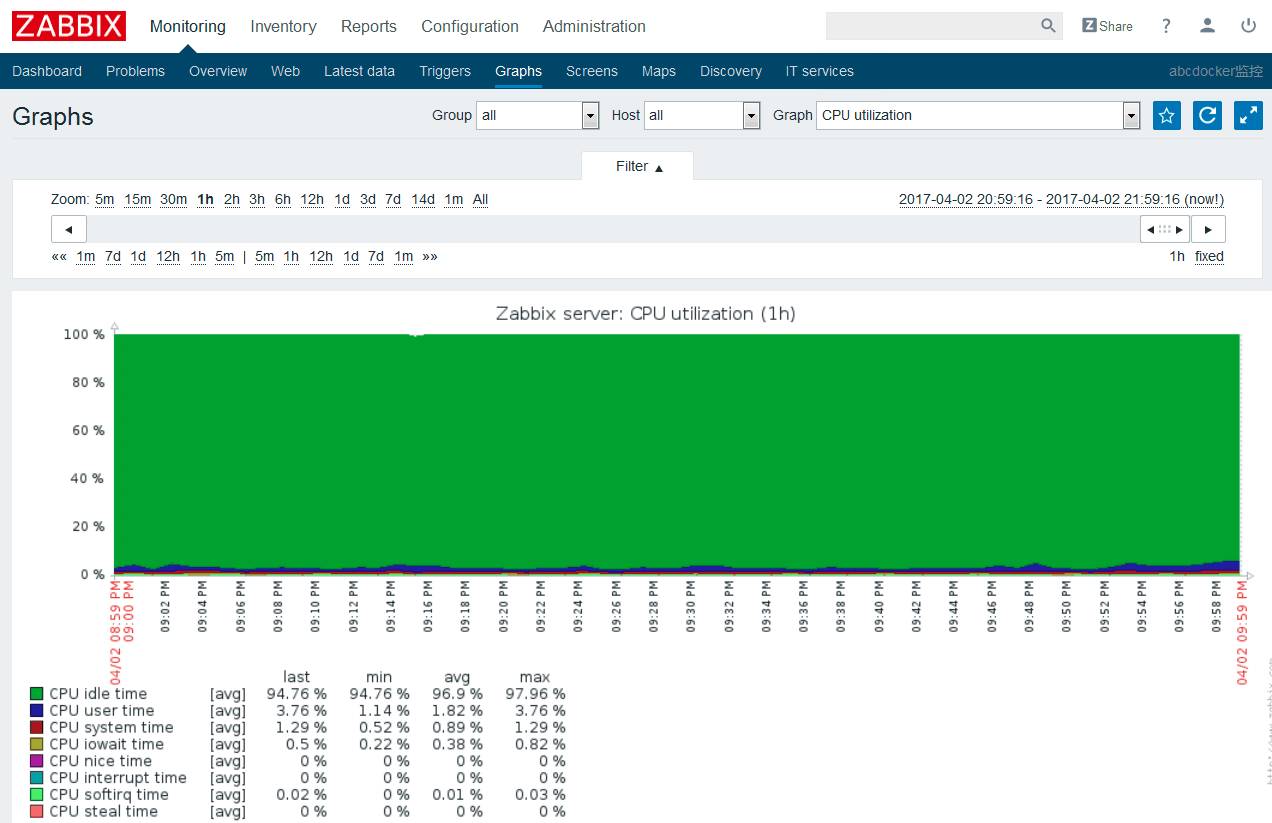
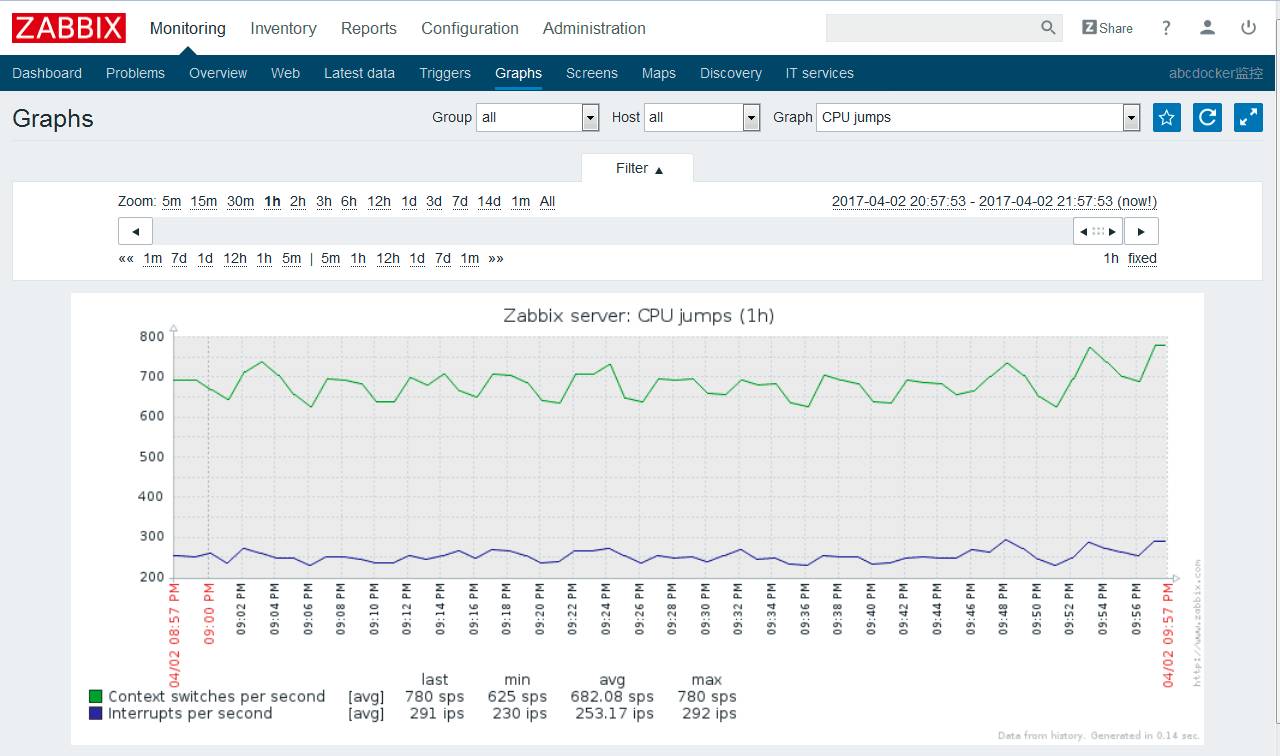
CPU 有几个重要的概念:上下文切换、运行队列和使用率。
这也是我们 CPU 监控的几个重点指标。
通常情况,每个处理器的运行队列不要高于3,CPU 利用率中“用户态/内核态”比例维持在70/30,空闲状态维持在50%,上下文切换
要根据系统繁忙程度来综合考量。
针对 CPU 常用的工具有:htop、top、vmstat、mpstat、dstat、glances
Zabbix 提供系统监控模板:Zabbix Agent Interface
cpu整体状态
cpu上下文切换
硬盘读写吞吐
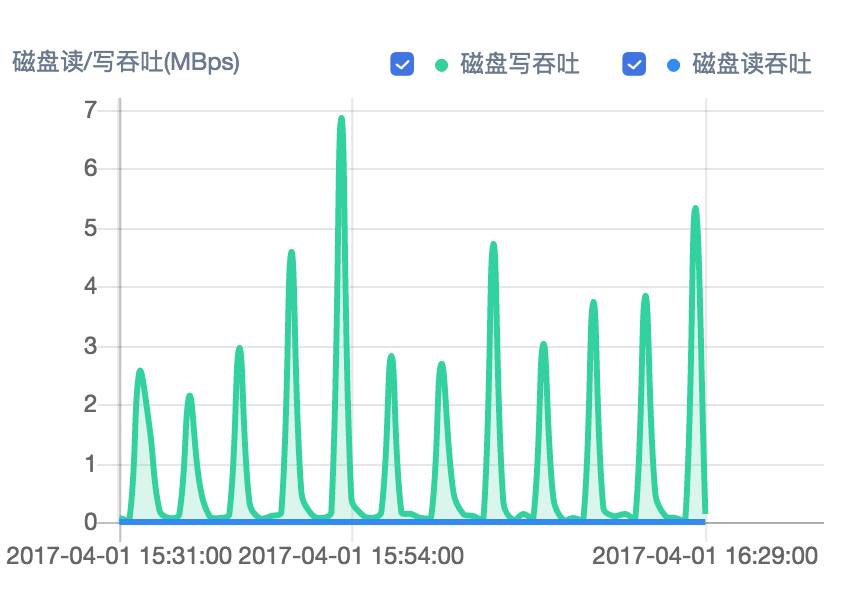
其它的系统监控还有运行的进程端口、进程数、登陆用户、Open File 等(详细查看 zabbix 自带 OS Linux 模板)
应用监控
把硬件监控和系统监控研究明白后,我们进一步操作是需要登陆到服务器上查看服务器运行了哪些服务,都需要监控起来。 应用服务监控也是监控体系中比较重要的内容,例如:LVS、Haproxy、Docker、Nginx、PHP、Memcached、Redis、MySQL、Rabbitmq 等等,相关的服务都需要使用zabbix监控起来。
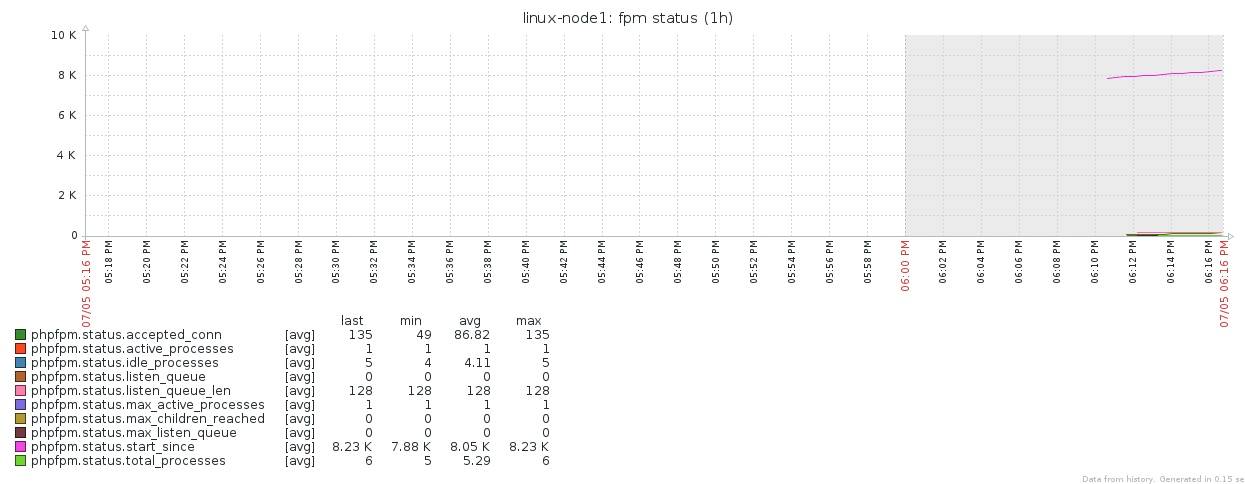
PHP-FPM状态
redis状态
Zabbix 提供应用服务监控:Zabbix Agent UserParameter Zabbix 提供的Java监控:Zabbix JMX Interface percona 提供 MySQL 数据库监控:percona-monitoring-plulgins
网络监控
网络监控是我们构建监控平台时必须要考虑的,尤其是针对有多个机房的场景,各个机房之间的网络状态,机房和全国各地的网络状态都是我们需要重点关注的对象。
需要借助于网络监控工具 Smokeping监控机房链路。
Smokeping 是 rrdtool 的作者 Tobi Oetiker 的作品,是用 Perl 写的,主要是监视网络性能,www 服务器性能,dns 查询性能等,使用 rrdtool 绘图,而且支持分布式,直接从多个 agent 进行数据的汇总。
CDN监控。。。对接第三方接口
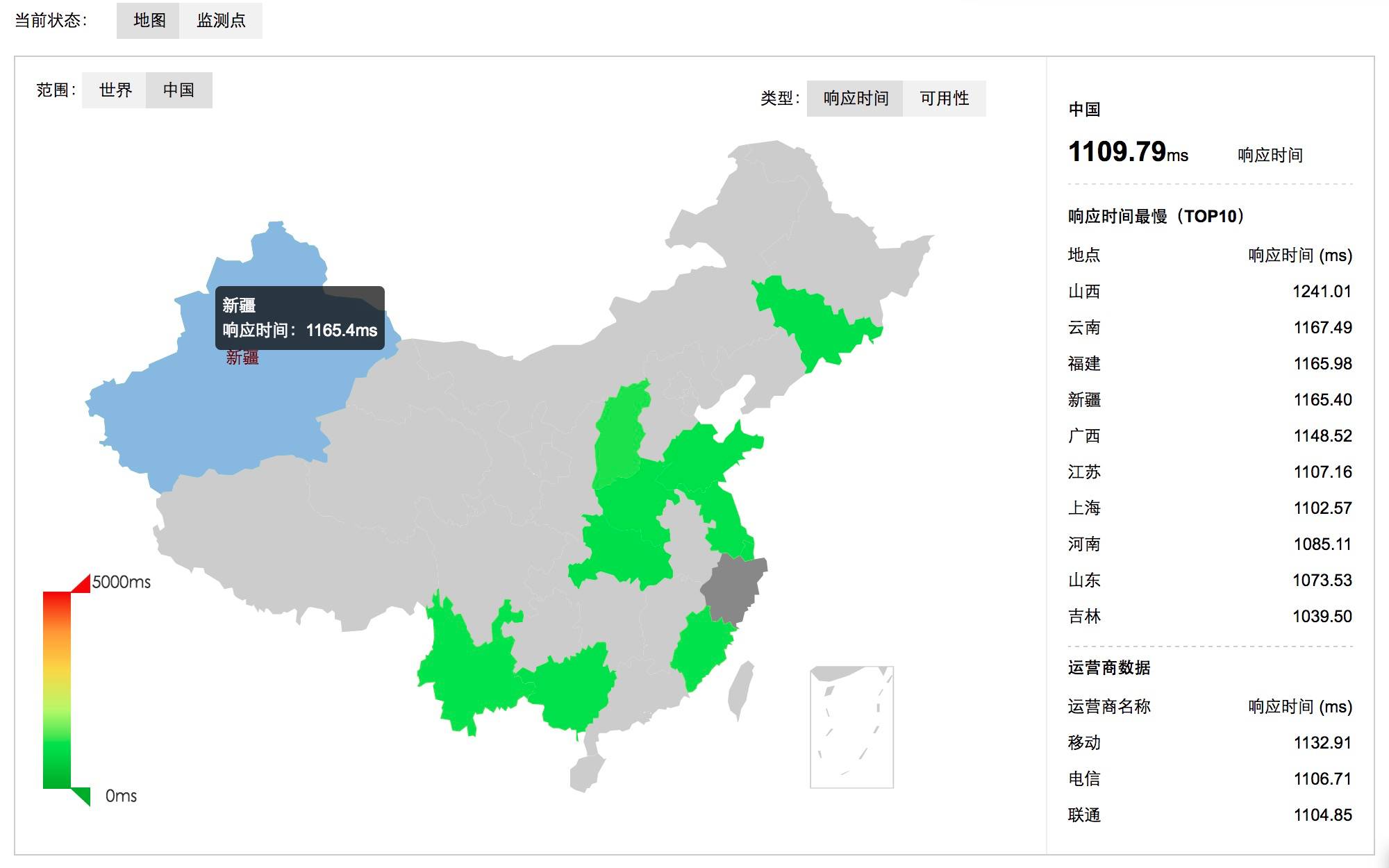
流量分析
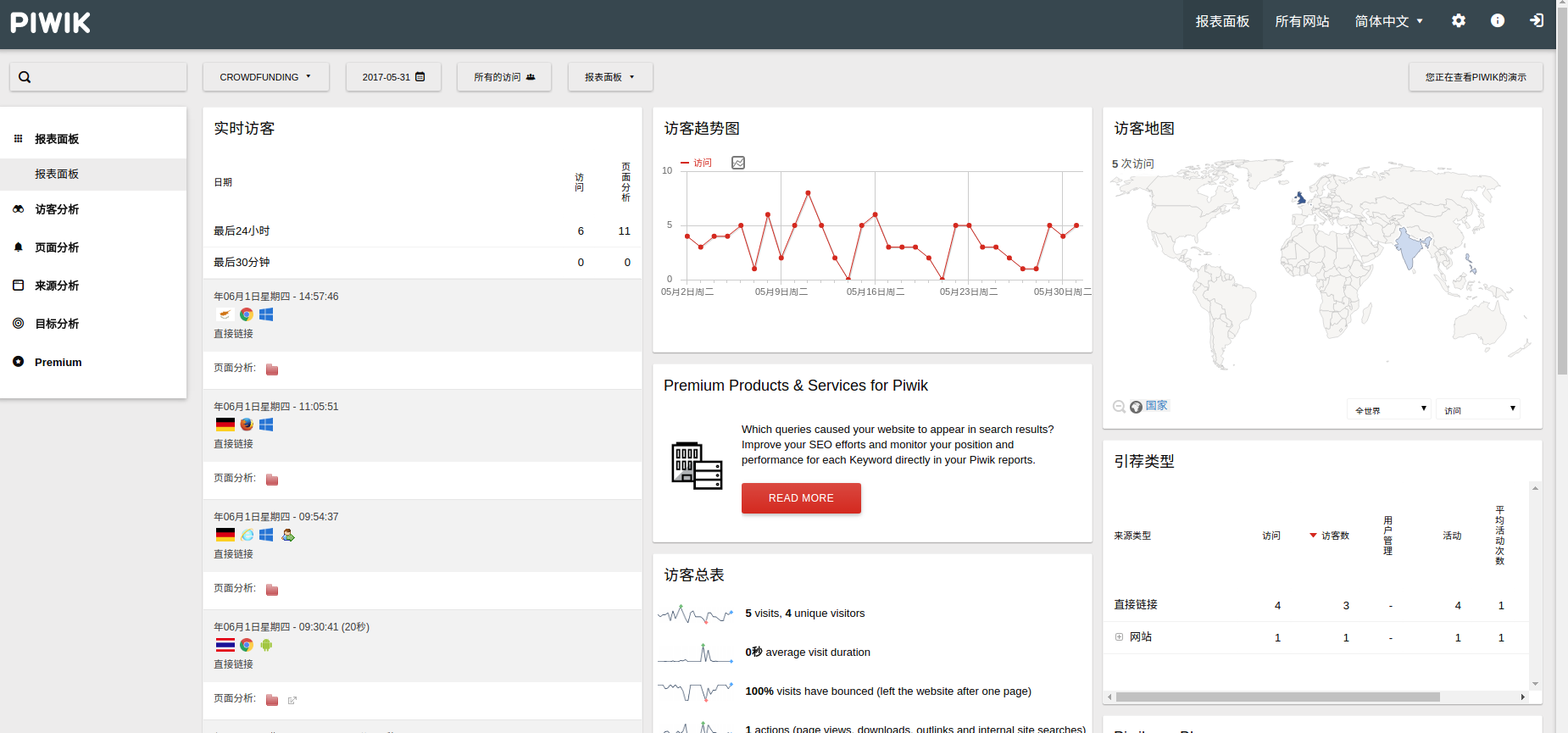
网站流量分析对于运维人员来说,更是一门必须掌握的知识了。比如对于300.cn站点来说:
通过对网站来源的统计和分析,可以了解我们在某个网站上的广告投入有没有收到预期的效果。 可以区分不同地区的访问人数、甚至产品交易额等。 百度统计、google 分析、站长工具等等,只需要在页面嵌入一个js即可,但是,数据始终是在对方手中,个性化定制不方便,推荐使用google的piwik开源网站访问统计系统。
日志监控
通常情况下,随着系统的运行,操作系统会产生系统日志,应用程序会产生应用程序的访问日志、错误日志、运行日志、网络日志,我们可以使用 ELK 来进行日志监控。
对于日志监控来说,最见的需求就是收集、存储、查询、展示。
开源社区正好有相对应的开源项目: logstash(收集) + elasticsearch(存储+搜索) + kibana(展示) 我们将这三个组合起来的技术称之为 ELK Stack,所以说 ELK Stack 指的是 Elasticsearch、Logstash、Kibana 技术栈的结合。
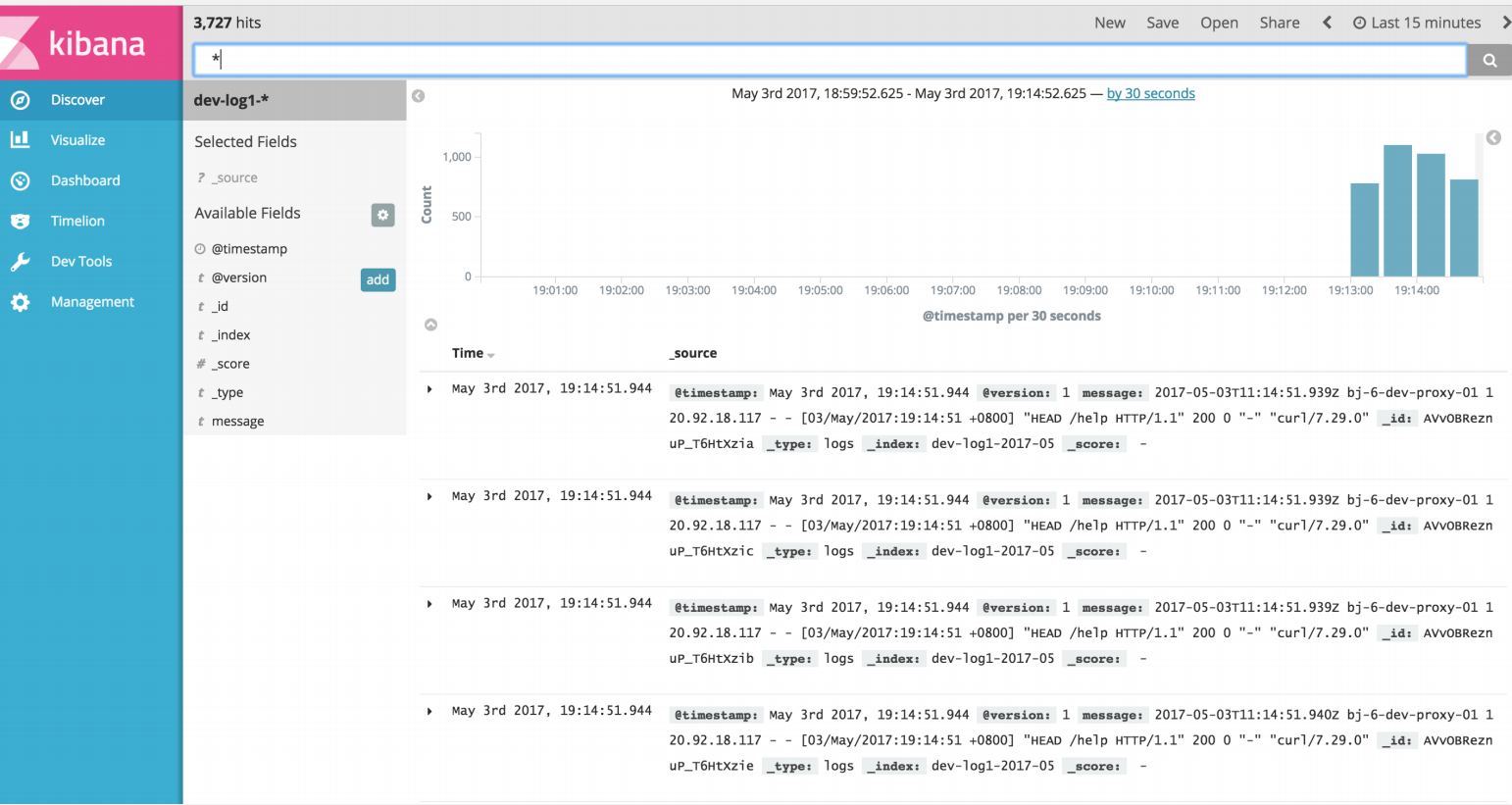
如果收集了日志信息,那么如果部署更新有异常出现,可以立即在 kibana 上看到。
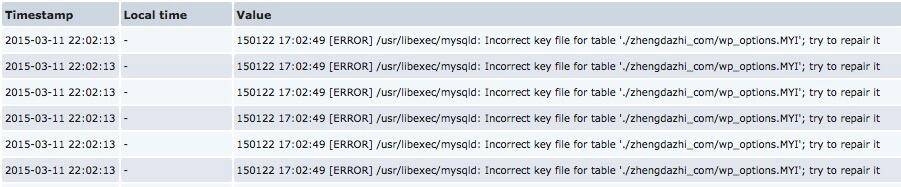
当然也可以通过Zabbix过滤错误日志来进行告警。
安全监控
虽然Linux开源的安全产品不少,比如四层 iptables,七层WEB防护 Nginx+lua 实现 WAF,最后将相关的日志都收至 ELK Stack,通过图形化进行不同的攻击类型展示。但是始终是一件比较耗费时间的事情,并且个人认为效果并不是很好。
API监控
由于微服务架构的推行, API 变得越来越重要,很显然我们也需要这样的数据来分辨我们提供的 API 是否能够正常运作。
监控 API 接口 GET、POST、PUT、DELETE、HEAD、OPTIONS 的请求, 可用性、正确性、响应时间为三大重性能指标

性能监控
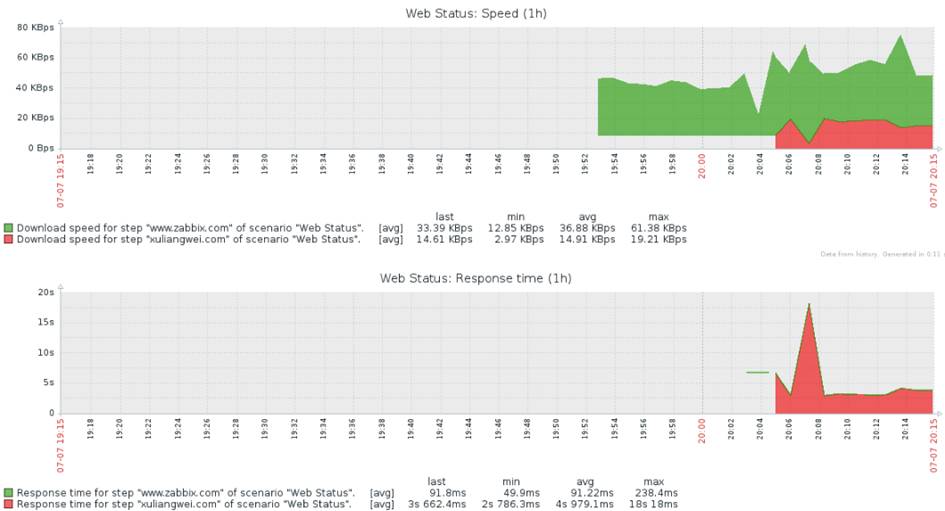
全面监控网页性能,DNS 响应时间、HTTP 建立连接时间、页面性能指数、响应时间、可用率、元素大小等
Zabbix 提供 URL监控:Zabbix Web 监控
业务监控
没有业务指标监控的监控平台,不是一个完善的监控平台,通常在我们的监控系统中,必须将我们重要的业务指标进行监控,并设置阈值进行告警通知。
例如一个产品集群:
- 每天产生多少订单;
- 每天注册多少用户;
- 每天有多少活跃用户;
- 每天有多少推广活动;
- 推广活动引入多少用户;
- 推广活动引入多少流量;
- 推广活动引入多少利润;
等等 重要指标都可以加到 Zabbix 上,然后通过 screen 展示。
监控报警
故障报警通知的方式有很多种,当然我们最常用的还是短信,邮件
报警处理
一般报警后我们故障如何处理,首先,我们可以通过告警升级机制先自动处理,比如 Nginx 服务 down 了,可以设置告警升级自动启动 Nginx。
但是如果一般业务出现了严重故障,我们通常根据故障的级别,故障的业务,来指派不同的运维人员进行处理。 当然不同业务形态、不同架构、不同服务可能采用的方式都不同,这个没有一个固定的模式套用。
总结
- 监控是一个长期持续的项目, 需要特定的1-2人跟踪改进;
- 监控使用方是业务和运维;
- 业务方应提供监控项获取方法;
- 如果有投诉,先找监控项目组,没有做到“事先”发现问题,监控项目组应该承担其责任;
- 对外提供api,供业务方使用