机器学习的语言之争
原文:Python, Machine Learning, and Language Wars - A Highly Subjective Point of View
噢,天呀,那些主观有针对性的,自以为标题党的文章的另一个?是哒!为什么我还要不厌其烦的写下来呢?嗯,这里是来自于我的前教授的最琐碎但又改变生活的洞察和世俗的智慧之一,它已经成为了我的口头禅了:“如果你必须做这个任务超过三次以上,那么只要写一个脚本,然后对其自动化。”
现在,你或许已经开始琢磨这个博客了。我已经超过半年没写什么东西了!好吧,沉迷在社交网络平台除外,那不是真的:我写了一些东西 —— 准确来说,约400页。最近,对我来说,这真的已经是一次旅程了。而对于经常被问道的问题“为什么你选择Python来进行机器学习?”,我猜,是时候来写_我的脚本_了。
在下面的段落中,我真的不打算告诉你为什么_你_或者其他人应该使用Python。老实说,我真心讨厌那类问题:“哪个最好?”(这里,用“编程语言、文本编辑器、IDE、操作系统、计算机制造商”替换掉)。这实在是扯淡。虽然有时它挺有意思的,但是我建议你节省下关于这个问题的时间,用来在下班后跟朋友或者同事偶尔喝喝啤酒或咖啡。
目录
- 对于一个复杂问题的简短回答
- 我最喜欢的Python工具是什么?
- 我对MATLAB是怎么看的?
- Julia真棒……理论上!
- R实在没啥错
- Perl发生了什么?
- 其他观点
- Python是一个正在死掉的语言吗?
- 总结
- 反馈和观点
对于一个复杂问题的简短回答
或许我应该从一个简短的回答开始。欢迎你停止阅读这段后面的文章,因为它真的解决掉这个问题了。我是一个科学家,我喜欢完成我的工作。我喜欢有一个环境,在那里我可以快速原型,并记下我的模型和想法。我需要解决非常特殊的问题。我分析给定的数据集以得出结论。这对我来说是最重要的:我怎样才能最多产的完成我的工作呢?“多产”这里意味着什么?好吧,我通常只进行一次分析 (不同的想法测试和调试除外); 我不需要重复地24/7地运行一段特定的代码,我并不是在为最终用户开发软件应用或web应用。当我_量化y_ “多产”时,我从字面上评估(1) 把想法以代码的形式写下来所花费的时间,(2) 调试的时间和 (3) 执行的时间之和。对我来说,“最多产”意味着“获得结果需要花费多少时间?” 现在,这么多年来,我发现,Python就是为我而生的。并非总是如此,但很多时候是这样。正如生活中的其他东西一样,Python并不是“银弹”,它并非总是每一个问题的“最佳”解决方案。然而,如果你跨常见和不那么常见的问题任务来比较编程语言的话,它已经非常接近(最佳解决方案)了;Python可能是最通用,最有能力的全才。

(来源: https://xkcd.com/974/)
请记住:“过早的优化是一切罪恶的根源” (Donald Knuth)。如果你是那种想要从机器学习和数据科学划分中中优化下一个颠覆性高频交易模型的软件工程团队中的一员,那么Python可能不适合你 (但或许它是数据科学团队的语言选择,所以学习如何读懂它仍然有用)。因此,我的一个小小的忠告是,当你选择一门语言时,评估你每天的问题任务和需求。“如果你只有一把锤子,那么一切开始看起来都像一个钉子” – 你聪明得不会掉入这个陷阱!然而,记住,有一个平衡点。在有些场景下,即使螺丝刀可能是“更漂亮的”解决方法,锤子可能还是最好的选择。再次,这归结为生产力。
让我从个人经历中挑个例子来说说。 关于一个非常问题相关的假设,我需要开发一堆新颖的算法来“筛选”1千5百万个小的化合物。我完全是一个计算型人,但我和进行非计算性实验(我们称它们为“湿实验室”实验)的生物学家一起合作。目标是缩小它到一个包含100个潜在化合物的列表,这样他们可以在实验室里测试它们。提醒是,他们需要快速获得结果,因为他们仅有有限的实际来做实验。相信我,时间真的是“有限的”:在必须收集结果之前,我们刚让我们的补助金申请受理和研究得到资助 (我们的合作者对某种特定的只知春季产卵的幼虫做实验)。因此,我开始想“我要怎样尽可能快的把结果给他们?” 嗯,我懂C++和FORTRAN,如果我在各个语言中实现那些算法,那么与Python实现相比,执行“筛选”运行也许会更快些。这更多是一种有根据的猜测,我真的不知道实质上是否会更快。但有一件事我可以肯定:如果我开始用Python写代码,那么我可以让它在几天内运行 – 或许让对应的C++版本能够跑起来需要花一周的时间。以后,我会操心一个更有效的实现。在那一刻,重要的是,把那些结果拿给我的合作者 – “过早的优化是一切罪恶的根源。” 边注:相同的思路运用到数据存储解决方案。这里,我只是使用SQLite。CSV没有多大意义,因为我必须重复地注释和检索某些分子。我当然不想每次想要查看一个分子或者操作它的时候,都要全过程扫描或重写一个CSV – 在处理内存容量预留的问题。也许用MySQL会更好,但是出于上面提到的原因,我想快速地完成这项工作,并建立一个额外的SQL服务器……没时间做它了,用SQLite来完成这项工作挺好的。

(来源: https://xkcd.com/1319/)
结论:**选择满足_你的_需求的那个语言!**不过,这里有一个小小的告诫!初学者在学习一门语言之前怎么能知道它的优势和缺点,程序员应该怎么知道这门语言对她来说会是有用的呢?这就是我会做的事:只要在谷歌和GitHub上搜索那些与你最常见的问题任务有关的特别的应用和解决方法。你不需要阅读和了解代码。只需要看看最终产品,另外,不要犹豫问别人。不要只是询问一般“最好的”编程语言,而是具体点,描述你的目标以及为什么你想要学习如何编程。如果你想为MacOS X开发应用,那么你可能会想要看看Objective C和Swift,如果你想在Android上开发,那么你可能会对Java更感兴趣,以此类推。
我最喜欢的Python工具是什么?
如果你感兴趣,那些是我最喜欢并且最常使用的Python“工具”,每天,我都会使用它们中的大部分。
- NumPy: 我处理线性代数阵列结构和量化公式最喜欢的库;由SciPy增强。
- Theano: 为机器学习算法减负,并将计算分布到我的GPU内核中。
- scikit-learn: 用于每日、更基本的机器学习任务的最方便的API。
- matplotlib: 当涉及到画图时,这是我所选择的库。有时,我还使用seaborn来绘制特殊的图,例如,热图超级棒!
(来源: http://stanford.edu/~mwaskom/software/seaborn/examples/structured_heatmap.html)
- Flask (Django): 难得,我想要将一个想法转换成一个web应用。这里,Flask非常方便!
- SymPy: 对于符号数学,对我来说,它取代了WolframAlpha。
- pandas: 处理相当小的数据集,大多数来自于CSV文件。
- sqlite3:注释和查询“中型”数据集。
- IPython notebooks: 我还能说什么呢?我90%的研究发生在IPython notebooks。它只是一个让所有的东西都放在一个地方的好环境:想法、代码、注释、LaTeX方程、插图、图表、输出……
注意,IPython项目最近演变成了Jupyter项目。现在,你不止可以使用Jupyter notebook环境到Python上,还可以是R, Julia, 等等。
我对MATLAB是怎么看的?
几年前,我想当常用MATLAB (/Octave);大多数的计算机科学数据科学课都是用MATLAB。我真的觉得这对于原型真的一点儿都不是一个糟糕的环境!由于它的设计充分考虑了线性代数 (用于MATrix LABoratory的MATLAB),当涉及到实现机器学习算法时,比之Python/NumPy,MATLAB让人感觉更多点“自然” —— 好啦,为了公平起见,1-indexed编程语言对我们程序员来说,可能看起来有点奇怪。但是,记住,MATLAB带有一个大的价格标签,我认为它真正慢慢地淡出学术界以及工业界。此外,毕竟,我是开源粉 ;)。另外,与其他“生产性”的语言相比,它的性能也并不是那么的引人注目。看看下面的标准:
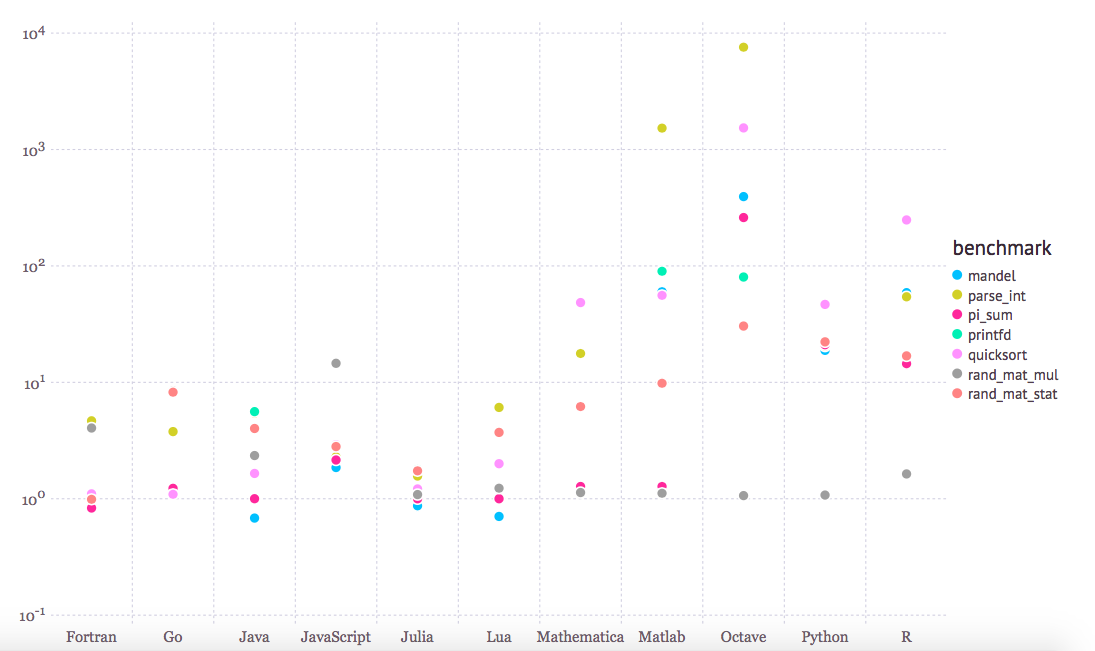
(相对于C的基准次数 —— 越小越好,C的性能 = 1.0; 来源: http://julialang.org/benchmarks/)
然而,我们不应忘记,对于Python,也有这样整洁的Theano库。在2010年,Theano的开发者报道,当代码运行在CPU时,它比NumPy快1.8倍,而如果Theano针对GPU,那么它甚至比NumPy快11倍 (J. Bergstra, O. Breuleux, F. Bastien, P. Lamblin, R. Pascanu, G. Desjardins, J. Turian, D. Warde-Farley, 和Y. Bengio. Theano: Python中的的一个CPU和GPU运算编译器。在Proc. 9th Python in Science Conf, 第1–7页,2010年。)。现在,记住,这个Theano基准是来自2010年,而多年来,Theano得到了显著的改善,现代显卡的功能也是。
我了解到,很多希腊人相信毕达哥拉斯所说的,所有的东西都是从数字生成的。这个断言带来了一个难题:不存在的东西怎么可以甚至设想生成?- Theano of Croton (哲学家,公元前6世纪)
PS: 如果你不喜欢NumPy的dot方法,那么敬请期待即将到来的Python 3.5 – 对于矩阵乘法,我们将获得一个中缀运算符,耶!
“手动的”矩阵矩阵乘法 (我的意思是,无需NumPy的帮助,而BLAS或者LAPACK看起来繁琐且非常低效)。
[[1, 2], [[5, 6], [[1 * 5 + 2 * 7, 1 * 6 + 2 * 8],
[3, 4]] x [7, 8]] = [3 * 5 + 4 * 7, 3 * 6 + 4 * 8]]
如果我们有线性代数和经过优化的库来处理它,谁还会想使用嵌套的for循环来实现这个表达式!?
>>> X = numpy.array()
>>> W = numpy.array()
>>> X.dot(W)
[[19, 22],
[43, 50]]
现在,如果这个dot产品对你来说并无吸引力,那么这是它将会在Python 3.5中的样子:
>>> X @ W
[[19, 22],
[43, 50]]
老实说,我不得不承认,我并不一定是“@”符号作为矩阵操作符的一个大粉丝。然而,我真的长时间苦苦想了这个问题,没法找到更好的“未使用的”符号了。如果你有更好的想法,请让我知道,我真的很好奇!
Julia真棒……理论上!
我认为Julia是一个伟大的语言,并且我会将其推荐给那些开始编程和机器学习的人。虽然,我不确定是否真的应该这样做。为什么呢?要把自己交给这个编程语言,是有点悲伤矛盾的。使用Julia,我们无法肯定在接下来的几年内,它是否会变得够“流行”。等等,“流行性”跟一门编程语言有多棒多有用有啥关系?让我告诉你。窘境是,最有用的语言不一定是设计良好的,但一定是流行的。为什么?
- 已经有大量的(大多数是免费的)库以供你使用,这样一来,你可以对你的时间尽其所用,而无需重新发明轮子。
- 在线查找帮助、教程和样例容易得多。
- 更频繁的语言改善、更新和补丁,会让它“甚至更好”。
- 对协作更友好,并且在团队中工作更简单。
- 更多的人会从你的代码中受益 (例如,如果你决定将其分享到GitHub上)。
就个人而言,我爱Julia本身。它完美的匹配了我的个人兴趣。虽然,我使用Python;主要是因为已经有了那么多超级棒的东西在那里了,这使得它格外得心应手。Python社区一切安好,而我相信在(至少)下一个5到10年内,它还会存在并蓬勃发展。但是对于Julia,我并没那么肯定。我喜欢设计,我觉得这很棒。尽管如此,如果它并不流行,那么我无法分辨它是“面向未来的”。如果在几年内发展停止了呢?我会对那些在这点上将“死”的东西进行投资。然而,如果每个人都这样想,那么新语言就永远没戏了。
R实在没啥错
嗯,我猜我曾经是一个R人,这并不是什么大秘密。甚至我还写过一本关于它的书 (好吧,准确来讲,实际上是关于R中的热图(Heat maps in R)。注意,这是在几年前,在ggplot2是个事之前。没有真正令人信服的理由让你去看看 —— 我指的是这本书。不过,如果你无法抗拒要看看的话,这是免费的、5分钟就可读完的简短版本)。我同意,有点扯远了。所以,回到讨论:R怎么了?我觉得它完全没有不好的地方。我的意思是,毕竟,对于“数据科学”,R是非常强大的,并且完全可以胜任且“大众化”的语言!不久前,甚至微软也开始非常非常感兴趣:Microsoft收购Revolution Analytics,一家用于统计计算和预测分析的开源R编程语言服务商业提供商。
所以,我可以如何总结下对于R的感受呢?我不大确定这句话出自何处 —— 我在前段时间从某处某人那里看到的 —— 但它很好的解释了R和Python之间的区别:“R是统计学家为了自己开发的一门编程语言;而Python是计算机科学家开发的,程序员可以用它来应用统计技术。”该消息的部分是,R和Python都同样能够用于“数据科学”任务,然而,Python语法对我来说,只是感觉更自然 —— 这是个人品味问题。
我只想提出,Theano和在GPU上计算是Python的一个大增益,但我看到R也完全可以:GPU和R上的并行编程。我知道接下来你想问什么:“好吧,那么要是把我当模型编程一个漂亮_闪亮_的web应用又如何?我打赌,这是你没法在R中做的事!” 抱歉,但是你输了;看看Shiny by RStudio,一个R语言的web应用框架。你明白我的意思吗?这里没有赢家。可能永远都不会有。
把我最喜欢的Python引述中的一个从其原有语境中拿出来:“这里,我们都是大人” —— 不要在把我们的时间浪费在语言之争上了。选择那个“适合”你的语言。当涉及到就业市场上的观点:这里也没有对错。我不认为要聘请你为“数据科学家”的公司真的会计较你最喜欢的工具箱 —— 毕竟,编程语言只是“工具”。而最重要的技能是像“数据科学家”一样思考,问正确的问题,能够解决问题。难的是数学和机器学习理论,新的编程语言是可以很容易学到的。试想一下,你学会了如何挥舞锤子来把钉子敲进去,而从不同的制造商那里挑一把锤子能有多难?但如果你仍然感兴趣,例如看看TIOBE Index,_一个_编程语言流行性的估量:
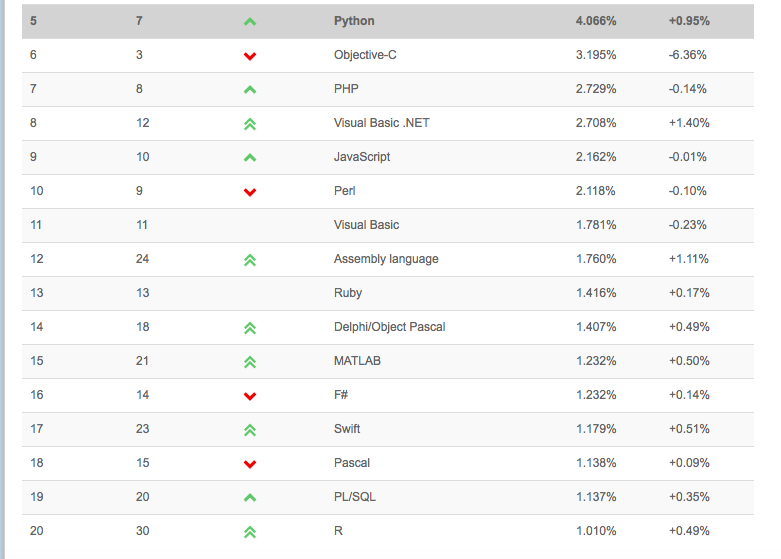
(来源: http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html)
但是,如果我们看看来自Spectrum IEEE的2015年十大编程语言,那么会发现,R语言正在快速攀升(左列:2015,右列:2014)。
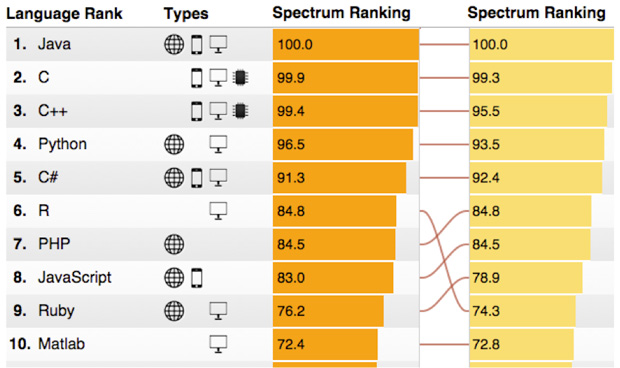
(来源: http://spectrum.ieee.org/computing/software/the-2015-top-ten-programming-languages)
我想你了解了。Python和R,不再有什么真正打的区别了。此外,当你在选择使用哪个语言的时候,你不应该担心工作计划。
Perl发生了什么?
Perl是在我早起职业生涯中选取的第一门语言(当然,除了高中时使用的Basic, Pascal, 和Delphi)。在我还是德国的一个大学生的时候,我上了一门Perl编程课。那时,我真心喜欢它,但是,嘿,在这点上,我确实没有什么好对其进行比较的。就个人而言,我只知道少数几个积极使用Perl为每天写脚本。虽然,我认为在生物信息学领域这仍然相当普遍!? 不管怎么说,让我们保持这部分简短,让它安息:““Perl死了。Perl万岁。”
其他观点
还有许多其他语言可以用于机器学习,例如,Ruby (Thoughtful Machine Learning: A Test-Driven Approach), Java (Java-ML), Scala(Breeze), Lua(Torch), 等等。然而,除了我多年前参与的一个Java类,或者PySpark, 这一用于Spark的Python API,它是用Scala写的,我真的没有使用那些语言的丰富经验,因此不知道该说些什么好。
Python是一个正在死掉的语言吗?
这是一个合法的问题,最近它在Quora出现了,如果你想听听关于这个的一些其他不错的观点,那么看看这个问题支线。不过,如果你想听听我的观点,我会说,不,它不是。为什么?好吧,Python是一门“相当”古老的语言 —— 它的第一个版本是在90年代初的某个时候 (我们可以从1991年开始算起),它像每一个编程语言一样,不得不做出某些选择和妥协。每一个编程语言都有它自己的怪癖,而更现代的语言趋向于从过去的错误中学习,这是件好事 (顺便说一下,R是在Python之后不久发布的:1995)。 Python远不“完美”,而像其他每个语言一样,它有自己的缺点。作为一个核心Python用户,我必须提一下,GIL (Global Interpreter Lock,全局解释锁)是让我最苦恼的东西 —— 但是请注意,有一个多进程和多线程模块,因此它实际上并非是一种限制,而是某些上下文中的小小“不便”。
对于一个编程语言“多棒”并无可以量化的度量,它真正取决于你在找寻什么。你想要问的问题是:“我想要实现什么,哪一个是实现它的最好的工具” —— “如果你只有一把锤子,那么一切开始看起来都像一个钉子。”再次说到锤子和钉子,Python是非常灵活的,我每天大部分的研究都是通过Python,使用强大的scikit-learn机器学习库 —— 用于数据改写的pandas,用户可视化的matplotlib/seaborn,以及用以跟踪所有这些东西的IPython notebooks —— 来完成的。
总结
好啦,这是对于一个看似很简单的问题的一个相当长的答案。相信我,我可以花几小时或几天继续写下去。但为嘛要把事情搞复杂呢?让我们总结一下:

(来源: https://xkcd.com/353/)
反馈和观点
我想要跟你分享关于这篇文章的很多很好的意见。记住,“一句忠告”有所偏颇是自然的;你或许发现了额,我的偏见是非常喜欢Python —— 抱歉啦,但这就是我!我相信,听取其他人的想法也是非常有用的!特别是当你是“数据科学”、机器学习和编程领域的新手的时候。话虽如此,请继续,看看下面的那些带干货的评论!
Python
- hackernews上的rm999:
为了把我的数据管道(从数据源一直到生产模型和前端/可视化)弄到一块,大概一年前,我从大多使用R切换到大多使用Python。这对我能够做的事或者我当生产力并无实际影响,除了我在使用任何语言的前几年中需要对其进行额外的谷歌。我选择Python的主要原因是单纯的实用:这是一个我团队之外的人会尊重和使用的语言。这使得我更容易以许多不同的方法进行协作:与其他团队共享工具,转移代码的所有权,在我需要的时候获得帮助,等等等等。在一些公司,数据科学有“设计一些东西,然后将其抛出墙外让其他人处理”这种美誉。根据我的经验,R只是加深了这种美誉。这太糟糕了,它真的能把它所做的事情做得很好。
- hackernews上的DrNuke:
我喜欢文章中的黑客方法:工具仅仅是做一些有价值的事情的工具,而不是目标本身。如今,因为数据科学爆炸以及快速与非专业人员进行交互的需要,所以,Python生态是正确的时候的正确的工具。
- hackernews上的zzleeper:
非常有意思的文章。我觉得很多数值Pythonistas都处在相同的境地:他们容忍大多数语言,但发现R的语法有点不自然,当试图超越纯矩阵的东西时Matlab有所不足,并都在观望Julia是否会崛起 (在我看来,似乎是会的)
- reddit上的JanneJM:
关键是有足够高品质的库。我知道的许多人,包括我,并不是真的对Python很感兴趣。我们使用Numpy, Scipy, Matplotlib, Pandas等等等等。Python只是来凑凑热闹。要是这些库出现在Ruby / Perl / Lua,那么它们就是我们今天会使用的语言。
Perl
- hackernews上的leni536:
“然而,我认为Perl在生物信息学领域还是相当常见的!?”这是事实 —— 许多生物信息学每天的任务都或多或少有纯文本分析[1],而Perl在解析文本和快速使用正则表达式方面有过人之处。“我”这一代的生物信息学家(20–30)使用Python进行数据清理和分析,有时是因为绘图更好,语言更容易上手,它在高校中较为普遍,或者其他原因 —— 比我这一代年长的人们通常使用P
R
- hackernews上的geomark:
我刚完成了Coursera数据科学之路,这让我从一个完全的R新手变得至少有点精通了。之前我用Python来进行相当多的web编程,起初,除了它统计编程的能力,我并不喜欢R。但最近,我发现了一些不错的R包,它们能让那些我通常会用Python做的事情用R来做变得愉悦。就像我最近发现的用于爬取网页的rvest包。用R进行数据可视化似乎优得多,除非我想念Python中的某些东西(极有可能)。并且提供一个漂亮的统计数据应用是很容易用shiny或者RStudio Presenter做到的。但R真的没法扩展到一个大型生产应用,不是吗?因此,我觉得我需要同时用Python 和R。新增:这是一个不错的列表。谢谢。另外,在文章中,他说Python语法感觉更自然,这也是我所觉得的。但后来我开始使用R中诸如magrittr和dplyr这种包,它们给你像管道一样不错的东西,因此那种感觉开始消退了。
- hackernews上的Adam_O
从一个学生的角度来看,大多数不错的在线分析/数据分析/统计课程都使用R,从医在学习材料的时候,很难摆脱它。一旦你获取了基础概念,那么转到Python应该不难。虽然,我想大多数的人仍然更喜欢用ggplot2进行可视化。每当我使用R的时候,我觉得自己像是一个统计学家,我可以感觉到从这门语言从散发出来的“冷严谨”。但最后,我觉得同时使用这两门语言是有利的。
MATLAB/Octave
- hackernews上的sampo
Andrew Ng在Coursera的机器学习课上说,根据他的经验,用Octave/Matlab完成课程作业的学生比用Python完成的快。但是是的,课程的关键是实现和玩转小数值算法,而该博客是关于那些主要调用Python中已有的机器学习库的人。
- hackernews上的misiti3780
Octave/Matlab是“不错”,但是尝试将其集成到一个生产web应用上还需要点好运气。既然你无法真正做到这点 —— 那么避免使用它们,除非你对实现相同的算法两次并无意见。Matlab license还要花钱买,而工具箱还需要花额外的钱。R是有用的,因为长时间以来它一直有很多资源,并且统计信息社区大部分都在使用它。它还有许多尚未移植到其他语言的有用的库 (ggmap!!!)。但你仍然还是要面对相同的问题,也就是说你没法将R集成到生产WEB应用上。我非常确定,Hadoop之流不支持R, Octave, 或者Matlab。
- hackernews上的thanatropism
这里少了一件事:Matlab的语法其实是非常接近现代Fortran的。我至少通过添加类型/常规的冗余/修改do-loops语法/等等重写Matlab代码,从而写了两次Fortran代码(用于蒙特卡罗模拟;不同的上下文)。
Julia
- hackernews上的Lofkin:
就个人而言,我尝试转到Julia,但速度缓慢的高阶函数,核心数据基础设施的高流失率,以及没有Pymc 3,这些都让我在pydata待了更长一点。我已经拴在numba上了。
- hackernews上的Buttons 840:
我专业使用Python 8年了,这是我最喜欢的语言。我有点常使用numpy和scikit-learn。这么说,最近,我真的很享受学习Julia的过程。它简单易学,并且确实表现良好(读:很快)。事实上,我认为学习Julia将会和学习一些诸如numba一样有用,并且提供相似的(有人说会略胜一筹)性能。
- hackernews上的idunning:
作为那种在日常工作(及编外项目)中几乎完全使用Julia的人中的一员,我认为作者对Julia的大部分想法都是正确的。我认为这个语言很棒,使用它让我的生活更美好。在我看来有一些包实际上比它们在其他语言中的等价物更好。另一方面,我对那些不完美的事物拥有更高的容忍度,我能自己理出头绪(幸运的是有时间这样做),并且如果不存在的话(在每一点上),我愿意为它编码。当然,对大多数的人来说,并不是这样的,但没关系。作者不愿意冒着Julia将会不“存在”的风险,这很公平。它肯定尚未完成,但它正在完成的路上。虽然,我有信心,它会存活下来(并且繁荣发展),并且继续增长不充实的社区。我有一种感觉,在一两年左右,最终,作者将找到他到Julia王国之路。
- reddit上的niksko:
我同意Julia主题。它潜力巨大,并且它基本上是专门为这些类型的应用准备的,但现在还没有社区和支持。我花了一个学期进行计算进化动力学领域的一个小的研究项目,而最繁琐最困难的部分是让Julia绘制我所想要的图。另外,那个时候,它还没有支持文档字符串 :/。它速度快,炫,但不够成熟。
- reddit上的KG7ULQ:
在我学习Coursera上的Ng ML课程后,我看了看,似乎要做的事情就是使用Python……但必须学习几个大库,包括你提到的那些。然后我看到了Julia,觉得我还不如学习它,因为它已经内置了所有的线性代数和SIMD相关的东西,并且性能更好。它的确看起来像是ML的“最佳”语言。
其他语言 (我忘记提的那些)
- hackernews上的leni536:
C++并没有做错什么。对于线性代数,我使用armadillo库,它是LAPACK和BLAS一个非常棒的封装 (并且也快!)。出于某些原因,科学家有点怕C++。由于某些原因,你“不得不”在一个“更容易的”语言中进行原型。当然,你你能把C++当成计算器而不是解释语言,但我看到人们卡在原型语言的计算上,最终并没有把它带到一个更快的平台上。要点是:C++对于科学计算并不难。
- reddit上的leni536:
对我来说,如果有什么会替换掉Python,那么Scala应该是最可能的候选者。我认为,函数式语言很好的适用于数学工作,并且它在JVM上,因此原型可以变成生产代码,而不需太多开销就可以“到处”运行。Spark是Scala的杀手级应用。现在,我可以从原型到在任意大的数据集之上运行,并且之间不会有太多的障碍。
- reddit上的rpcope1:
[Scala]在编译的时候可能是慢,但它比CPython更安全,并且快得多(除了使用非字节码的代码和调用C/Fortran库之外),并且还有一些我现在在Python中及其想念的概念,例如,Option[T],隐式修改器,不废柴的map/reduce/filter,不废柴的lambda,等等。